

In today’s enterprise, the role of the data scientist can seem deceptively simple: generate insights from data and deliver them to decision makers. This process can look like a one-way trip — models are delivered, the business takes action, and the data scientists are left wondering if and how their models have driven impact. Moreover, the sober reality is that most of the time and energy is often spent battling glacial data discovery, data procurement, and model delivery processes, rather than evaluating the effectiveness of the models themselves.
The Palantir Foundry Ontology provides a solution by forming a feedback loop between operational actions and the models that informed them. The Ontology accelerates data scientists’ ability to identify bottlenecks, take action with all the relevant data, deliver their models, and finally quantify their impact on the business through changed behavior. Having worked as a machine learning engineer, and now as a Palantir architect, I’ve seen firsthand how this technology represents a paradigm shift for data science professionals. In this blog post, I’ll explain why.
Flipping the role of the data scientist from reactive to proactive
Today, data scientists largely receive a general directive from leadership, from their central organization, or from their assigned business unit. For example: “Patient waiting times have increased in recent months. How can we bring these down?” To uncover a tangible goal and figure out how to solve the problem, data scientists need to interact with subject matter experts, or SMEs, across the organization to gather the institutional knowledge required to address the challenge.
The Ontology intelligently collates all of your organization’s entities, relationships, processes, and events in one place — revealing bottlenecks and opportunities for change across the business. Equipped with a cartography of action, data scientists do not need to rely on SMEs to serve as business process tutors. Instead, they can view all systems and interconnections directly, allowing them to pinpoint who to consult and what models to create. What was once a painfully fractured experience of domain knowledge transfer is significantly streamlined, enabling data scientists to focus on optimizing solutions.
Source data in minutes, rather than months
Once opportunities for model building and process improvement have been identified, collecting the necessary data can still prove challenging because data assets are often decoupled from the relevant business units, stored in enterprise data lakes or data warehouses. Procuring the correct data assets to meet the business need requires knowledge of the source systems and various approvals.
The Ontology captures real-world business processes and associated “Actions” and links them to data objects. These objects are then surfaced as data science targets. Creating data science targets in this way eliminates the need to dive deep into data lakes or warehouses to discover relevant datasets or go through a chain of approvals once those datasets are identified.
While data procurement sometimes takes months in companies that do not use Foundry, it is now a much shorter part of the process thanks to the way the Ontology intuitively helps data scientists find relevant data.
Deliver models into the right hands, quicker than ever before
To deliver trustworthy, actionable, and explainable models and predictions to decision-makers, data scientists need to know who controls a process or decision. As mentioned earlier, however, data scientists often receive business directives from people in the organization who will not ultimately use the models produced.
To compound this challenge, delivery is rarely straightforward. Due to a number of factors, is not uncommon for models to take months or even years to develop before they’re finally used. Separate teams of machine learning (ML) engineers must take the models, refactor them into containers and application layers, and configure endpoints in order to make the models scalable and actionable. These additional steps can add unnecessary friction to delivery.
Then, even when models are deployed (e.g., as microservices in containers), app developers still need to edit business applications to request and consume predictions into an actionable context. This further narrows the window of opportunity for action as the business process or project requirements may have already changed.
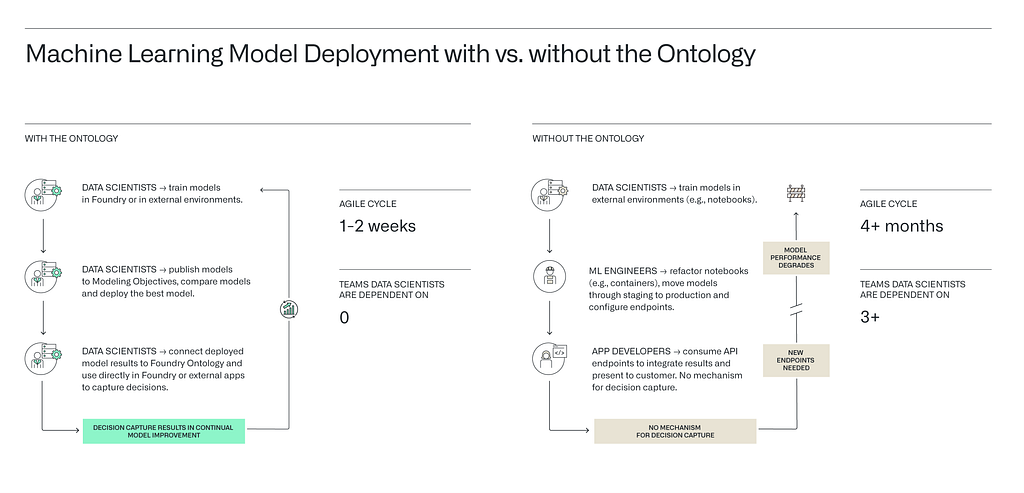
The Ontology helps data scientists overcome these friction points in several ways:
- The Ontology exposes who’s actually making use of data science models, so data science teams do not have to guess whom they’re designing their models for. As a result, they can tune their models appropriately and avoid paper cuts from engaging in unnecessary feedback loops with decision-makers.
- The Ontology creates a truly agile development cycle for ML models, enabling data scientists to train, publish, deploy, and measure the results of their models in the context of real operational feedback loops. No back-and-forth with ML engineers means faster model delivery. Once models are delivered, the data scientist can see results and tweak their models accordingly.
- The Ontology then allows data science teams to make versioned edits directly to user-facing Foundry applications or build their own apps point-and-click from scratch. Because the Ontology provides a unified API and integrated tools for rapid and collaborative application development, full-stack data science can be delivered by one agile team in proper two-week iteration cycles — the correct pattern for delivering data products.
Closing the loop between models and decisions
Knowing whether a model proved useful requires constant and consistent feedback from decision-makers, as well as visibility into the results of decisions made and other organizational behavior changes. If model predictions were not used, it is also helpful for data scientists to understand why.
The Ontology’s writeback capabilities, exposed through its API or dependent applications, enable continuous and bidirectional communication between data science and operational teams about model usage, decisions made, and business impact.
Imagine that, through Ontology records, a data science team discovers their app-deployed recommended actions are being ignored by users. Using Ontology writeback, the data science team can capture feedback by adding a usefulness toggle and comment box to the downstream application. Instantly, comments start flooding in and the problem is clear: end users don’t trust the recommendations because they do not understand their drivers.
The good news is the new solution takes just hours to deploy. The data science team publishes model feature importances linked to predictions through the Ontology that now appear alongside every recommendation for transparency.
While this situation is notional, we have seen it play out many times over with our customers, who wield the Ontology to accelerate business-wide change by harnessing the full collaborative power of their talented data science teams.
The Foundry Ontology can enable data scientists to reach their full potential. It clearly defines for data scientists where the opportunities for business improvement lie and speeds up the creation and deployment of ML models.
Learn more about Palantir Foundry and the Ontology that underlies it.
Author:
Wes Field, Forward-Deployed Architect at Palantir
![]()
How Palantir Foundry’s Ontology Deploys Data Science to the Front Line was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.