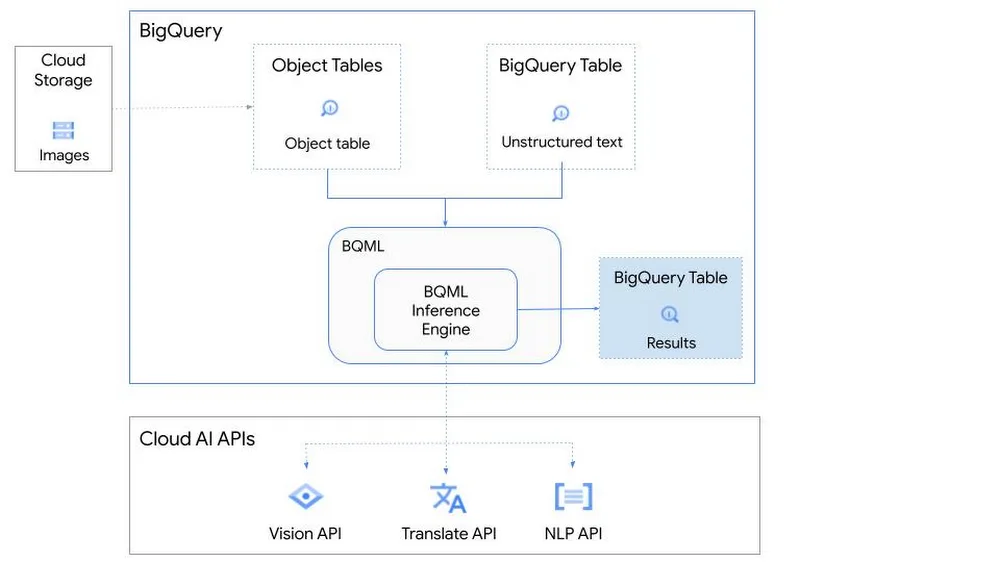
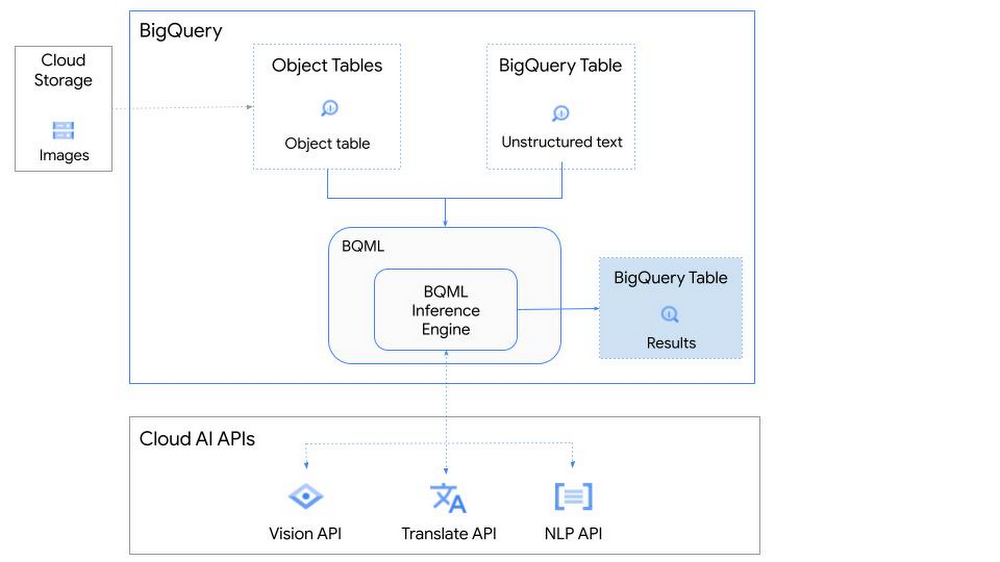
Unstructured data such as images, speech and textual data can be notoriously difficult to manage, and even harder to analyze. The analysis of unstructured data includes use cases such as extracting text from images using OCR, sentiment analysis on customer reviews and simplifying translation for analytics. All of this data needs to be stored, managed and made available for machine learning.
The new BigQuery ML inference engine empowers practitioners to run inferences on unstructured data using pre-trained AI models. The results of these inferences can be analyzed to extract insights and improve decision making. This can all be done in BigQuery, using just a few lines of SQL.
In this blog, we’ll explore how the new BigQuery ML inference engine can be used to run inferences against unstructured data in BigQuery. We’ll demonstrate how to detect and translate text from movie poster images, and run sentiment analysis against movie reviews.
BigQuery ML’s new inference engine
Google Cloud is home to a suite of pre-trained AI models and APIs. The BigQuery ML inference engine can call these APIs and manage the responses on your behalf. All you have to do is define the model you want to use and run inferences against your data. All of this is done in BigQuery using SQL. The inference results are returned in JSON format and stored in BigQuery for analysis.
Why run your inferences in BigQuery?
Traditionally, working with AI models to run inferences required expertise in programming languages like Python. The ability to run inferences in BigQuery using just SQL can make generating insights from your data using AI simple and accessible. BigQuery is also serverless, so you can focus on analyzing your data without worrying about scalability and infrastructure.
The inference results are stored in BigQuery, which allows you to analyze your unstructured data immediately, without the need to move or copy your data. A key advantage here is that this analysis can also be joined with structured data stored in BigQuery, giving you the opportunity to deepen your insights. This can simplify data management and minimize the amount of data movement and duplication required.
Which models are supported?
For now, the BigQuery ML inference engine can be used with these pre-trained Vertex AI models:
Vision AI API: This model can be used to extract features from images managed by BigQuery Object Tables and stored on Cloud Storage. For example, Vision AI can detect and classify objects, or read handwritten text.
Translation AI API: This model can be used to translate text in BigQuery tables into over one hundred languages.
Natural Language Processing API: This model can be used to derive meaning from textual data stored in BigQuery tables. For example, features like sentiment analysis can be used to determine whether the emotional tone of text is positive or negative.
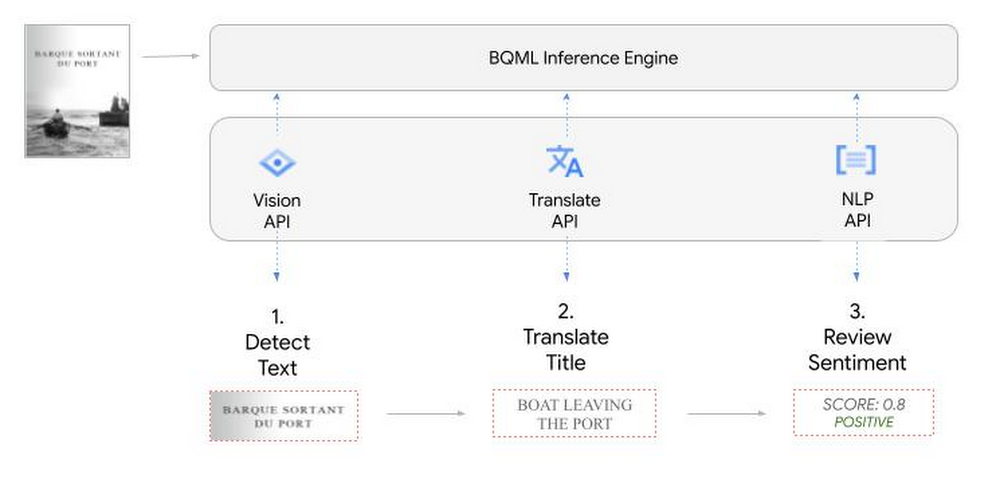
So, how does this work in practice? Let’s look at an example using images of movie posters

We will define our pre-trained models for Vision AI, Translation AI and NLP AI in BigQuery ML.
We’ll then use Vision AI to detect the text from some classic movie posters images.
Next, we’ll use Translation AI to detect any foreign posters and translate them to a language of our choosing – English in this case.
Finally, we’ll combine our unstructured data with structured data in BigQuery.
We’ll use the extracted movie titles from our movie posters to look up the viewer reviews from the BigQuery IMDB public dataset. We can then run sentiment analysis against these reviews using NLP AI.
Note: The BigQuery ML inference engine is currently in Preview. You will need to complete this enrollment form to have your project allowlisted for use with the BQML Inference Engine.
We’ll give examples of the BigQuery SQL needed to define your models and run your inferences. You’ll want to check out our notebook for a detailed guide on how to get this up and running in your Google Cloud project.
1. Define your AI Models in BigQuery
You will need to enable the APIs listed below, and also create a Cloud resource connection to enable BigQuery to interact with these services.
API | Model Name |
Cloud_ai_vision_v1 | |
Cloud_ai_translate_v3 | |
Cloud_ai_natural_language_v1 |
You can then run the CREATE MODEL query for each AI service to create your pretrained models, replacing the model_name as required.
- code_block
- [StructValue([(u’code’, u”CREATE OR REPLACE MODEL rn`{PROJECT_ID}.{DATASET_ID}.{VISION_MODEL_NAME}`rnREMOTE WITH rnCONNECTION `{PROJECT_ID}.{REGION}.{CONN_NAME}`rnOPTIONS ( remote_service_type = ‘<model_name>’ );”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d9e3aab50>)])]
2. Use the Vision AI API to detect text in images stored in Cloud Storage
You will need to create an object table for your images in Cloud Storage. This read-only object table provides metadata for images stored in Cloud Storage:
- code_block
- [StructValue([(u’code’, u”CREATE OR REPLACE EXTERNAL TABLErn`{PROJECT_ID}.{DATASET_ID}.{OBJECT_TABLE_NAME}`rnWITHrnCONNECTION `{REGION}.{CONN_NAME}`rnOPTIONS (object_metadata = ‘SIMPLE’, uris = [‘{BUCKET_LOCATION}/*’]);”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1da9aee490>)])]
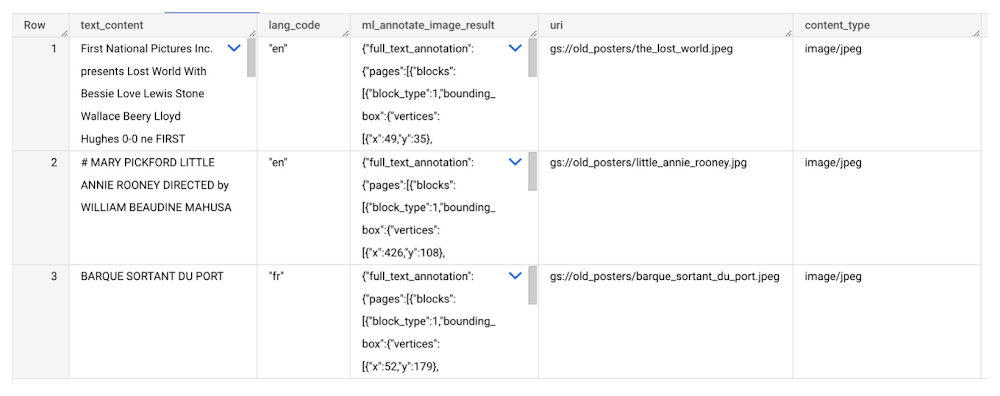
To detect the text from our posters, you can then use ML.ANNOTATE_IMAGE and specify the text_detection feature.
- code_block
- [StructValue([(u’code’, u”SELECTrn ml_annotate_image_result.full_text_annotation.text AS text_content,rn *rnFROMrn ML.ANNOTATE_IMAGE(rn MODEL `{PROJECT_ID}.{DATASET_ID}.{VISION_MODEL_NAME}`,rn TABLE `{DATASET_ID}.{OBJECT_TABLE_NAME}`,rn STRUCT([‘TEXT_DETECTION’] AS vision_features));”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d9f8d1250>)])]
A JSON response will be returned to BigQuery that includes the text content and language code of the text. You can parse the JSON to a scalar result using the dot annotation highlighted above.

3. Use the Translation AI API to translate foreign movie titles
ML.TRANSLATE can now be used to translate the foreign titles we’ve extracted from our images into English. You just need to specify the target language and the table of the movie posters for translation:
- code_block
- [StructValue([(u’code’, u’SELECTrntext_content,rnSTRING(ml_translate_result.translations[0].detected_language_code)rnas original_language,rnSTRING(ml_translate_result.translations[0].translated_text)rnas translated_titlernFROMrn ML.TRANSLATE(rnMODEL `{PROJECT_ID}.{DATASET_ID}.{TRANSLATE_MODEL_NAME}`,rnTABLE `{DATASET_ID}.image_results`,rnSTRUCT(‘TRANSLATE_TEXT’ as translate_mode, “en” as target_language_code));’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1da9981f50>)])]
Note: The table column with the text you want to translate must be named text_content:
The table of results will include json that can be parsed to extract both the original language and the translated text. In this case, the model has detected that title text is in French and has translated it to English:

4. Finally, use natural language processing (NLP) to run sentiment analysis against movie reviews
You can easily join inference results from your unstructured data with other BigQuery datasets to bolster your analysis. For example, we can now join the movie titles we extracted from our posters with thousands of movie reviews stored in BigQuery’s IMDB public dataset `bigquery-public-data.imdb.reviews`.
You can use ML.UNDERSTAND_TEXT with the analyze_sentiment feature to run sentiment analysis against some of these reviews to determine whether they are positive or negative:
- code_block
- [StructValue([(u’code’, u’SELECTrn primary_title, start_year, text_content AS review,rn FLOAT64(ml_understand_text_result.document_sentiment.score) AS score,rn FLOAT64(ml_understand_text_result.document_sentiment.magnitude) AS magnitude,rnFROMrn ML.UNDERSTAND_TEXT(rn MODEL `{PROJECT_ID}.{DATASET_ID}.{NLP_MODEL_NAME}`,rn (rn SELECTrn primary_title, start_year, review AS text_contentrn FROMrn `bigquery-public-data.imdb.title_basics` titlesrn JOINrn `bigquery-public-data.imdb.reviews` reviewsrn ONrn reviews.movie_id = titles.tconstrn WHERErn UPPER(titles.primary_title) = ‘THE LOST WORLD’ ANDrn start_year = 1925rn ),rn STRUCT(“analyze_sentiment” AS nlu_option)) ;’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d9eb51650>)])]
Note: The table column with the text you want to analyze must be named text_content:
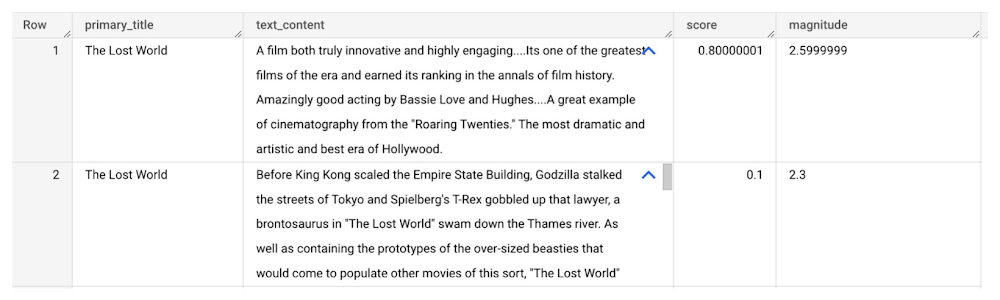
The JSON response will include a score and magnitude. The score indicates the overall emotion of the text while the magnitude indicates how much emotional content is present:
So, how did the Lost World compare with other movies that year?
To wrap up, we’ll compare the average review score of the 1925 Lost World movie to other movies released that year to see which was more popular. This can be done using familiar SQL analysis:
- code_block
- [StructValue([(u’code’, u’SELECTrn primary_title, start_year,rn AVG(FLOAT64(ml_understand_text_result.document_sentiment.score))AS av_score,rn AVG(FLOAT64(ml_understand_text_result.document_sentiment.magnitude)) AS av_magnitudernFROMrn ML.UNDERSTAND_TEXT(rn MODEL `{PROJECT_ID}.{DATASET_ID}.{NLP_MODEL_NAME}`,rn (rn SELECTrn primary_title, start_year, movie_id, review AS text_contentrn FROMrn `bigquery-public-data.imdb.title_basics` titlesrn JOINrn `bigquery-public-data.imdb.reviews` reviewsrn ONrn reviews.movie_id = titles.tconstrn WHERErn start_year = 1925rn ),rn STRUCT(“analyze_sentiment” AS nlu_option))rnGROUP BYrn primary_title, start_yearrnORDER BYrn av_score DESC;’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1da86ff210>)])]

It looks like The Lost World narrowly missed out on the top spot to Sally of the Sawdust!
Want to learn more?
Check out our notebook for a step by step guide on using the BQML inference engine for unstructured data in Google Cloud. You can also check out our Cloud AI service table-valued functions overview page for more details. Curious about pricing? The BQML Pricing page gives a breakdown of how costs are applied across these services.