In this example, we will demonstrate using current data within a Netezza Performance Server as a Service (NPSaaS) table combined with historical data in Parquet files to determine if flight delays have increased in 2022 due to the impact of the COVID-19 pandemic on the airline travel industry. This demonstration illustrates how Netezza Performance Server (NPS) can be extended to access data stored externally in cloud object storage (Parquet format files).
Background on the Netezza Performance Server capability demo
Netezza Performance Server (NPS) has recently added the ability to access Parquet files by defining a Parquet file as an external table in the database. This allows data that exists in cloud object storage to be easily combined with existing data warehouse data without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical data warehouse table.
To make it easy for clients to understand how to utilize this capability within NPS, a demonstration was created that uses flight delay data for all commercial flights from United States airports that was collected by the United States Department of Transportation (Bureau of Transportation Statistics). This data will be analyzed using Netezza SQL and Python code to determine if the flight delays for the first half of 2022 have increased over flight delays compared to earlier periods of time within the current data (January 2019 – December 2021).
This demonstration then compares the current flight delay data (January 2019 – June 2022) with historical flight delay data (June 2003 – December 2018) to understand if the flight delays experienced in 2022 are occurring with more frequency or simply following a historical pattern.
For this data scenario, the current flight delay data (2019 – 2022) is contained in a regular, internal NPS database table residing in an NPS as a Service (NPSaaS) instance within the U.S. East2 region of the Microsoft Azure cloud and the historical data (2003 – 2018) is contained in an external Parquet format file that resides on the Amazon Web Services (AWS) cloud within S3 (Simple Storage Service) storage.
All SQL and Python code is executed against the NPS database using Jupyter notebooks, which capture query output and graphing of results during the analysis phase of the demonstration. The external table capability of NPS makes it transparent to a client that some of the data resides externally to the data warehouse. This provides a cost-effective data analysis solution for clients that have frequently accessed data that they wish to combine with older, less frequently accessed data. It also allows clients to store their different data collections using the most economical storage based on the frequency of data access, instead of storing all data using high-cost data warehouse storage.
Prerequisites for the demo
The data set used in this example is a publicly available data set that is available from the United States Department of Transportation, Bureau of Transportation Statistics website at this URL: https://www.transtats.bts.gov/ot_delay/ot_delaycause1.asp?qv52ynB=qn6n&20=E
Using the default settings will return the most recent flight delay data for the last month of data available (for example, in late November 2022, the most recent data available was for August 2022). Any data from June 2003 up until the most recent month of data available can be selected.
The data definition
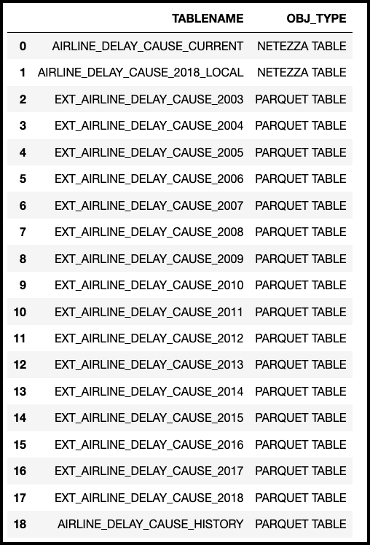
For this demonstration of NPS external tables capabilities to access AWS S3 data, the following tables were created in the NPS database.
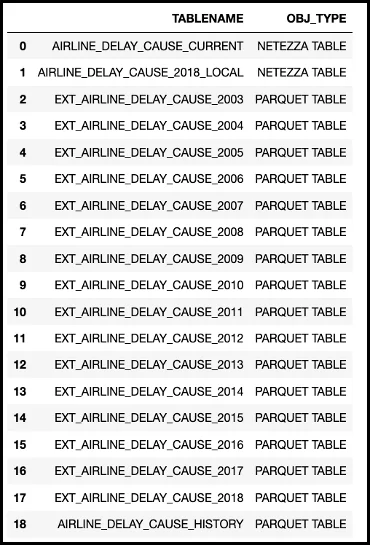
Figure 1 – NPS database table definitions
The primary tables that will be used in the analysis portion of the demonstration are the AIRLINE_DELAY_CAUSE_CURRENT table (2019 – June 2022 data) and the AIRLINE_DELAY_CAUSE_HISTORY (2003 – 2018 data) external table (Parquet file). The historical data is placed in a single Parquet file to improve query performance versus having to join sixteen external tables in a single query.
The following diagram shows the data flows:

Figure 2 – Data flow for data analysis
Brief description of the flight delay data
Before the actual data analysis is discussed, it is important to understand the data columns tracked within the flight delay information and what the columns represent.
A flight is not counted as a delayed flight unless the delay is over 15 minutes from the original departure time.
There are five types of delays that are reported by the airlines participating in flight delay tracking:
- Air Carrier – the reason for the flight delay was within the airline’s control such as maintenance or flight crew issues, aircraft cleaning, baggage loading, fueling, and related issues.
- Extreme Weather – the flight delay was caused by extreme weather factors such as a blizzard, hurricane, or tornado.
- National Aviation System (NAS) – delays attributed to the national aviation system which covers a broad set of conditions such as non-extreme weather, airport operations, heavy traffic volumes, and air traffic control.
- Late arriving aircraft – a previous flight using the same aircraft arrived late, causing the present flight to depart late.
- Security – delays caused by an evacuation of a terminal or concourse, reboarding of an aircraft due to a security breach, inoperative screening equipment, and/or long lines more than 29 minutes in screening areas.
Since a flight delay can result from more than one of the five reasons for the delay, the delays are captured using several different columns of information. The first column, ARR_DELAY15 contains the number of minutes of the flight delay. There are five columns that correspond to the flight delay types: CARRIER_CT, WEATHER_CT, NAS_CT, SECURITY_CT, and LATE_AIRCRAFT_CT. The sum of these five columns will equal the time listed in the ARR_DELAY15 column.
Because multiple factors can contribute to a flight delay, the individual components of the flight delay can indicate a fractional portion of the overall flight delay. For example, the overall delay of 4.00 (ARR_DELAY15) is comprised of 2.67 for CARRIER_CT and 1.33 for LATE_AIRCRAFT_CT to equal the total 4.00 flight delay. This allows for further analysis to understand all factors that contributed to the overall flight delay time.
Here is an excerpt of the flight delay data to illustrate how the ARR_DELAY15 and flight delay reason columns interact:
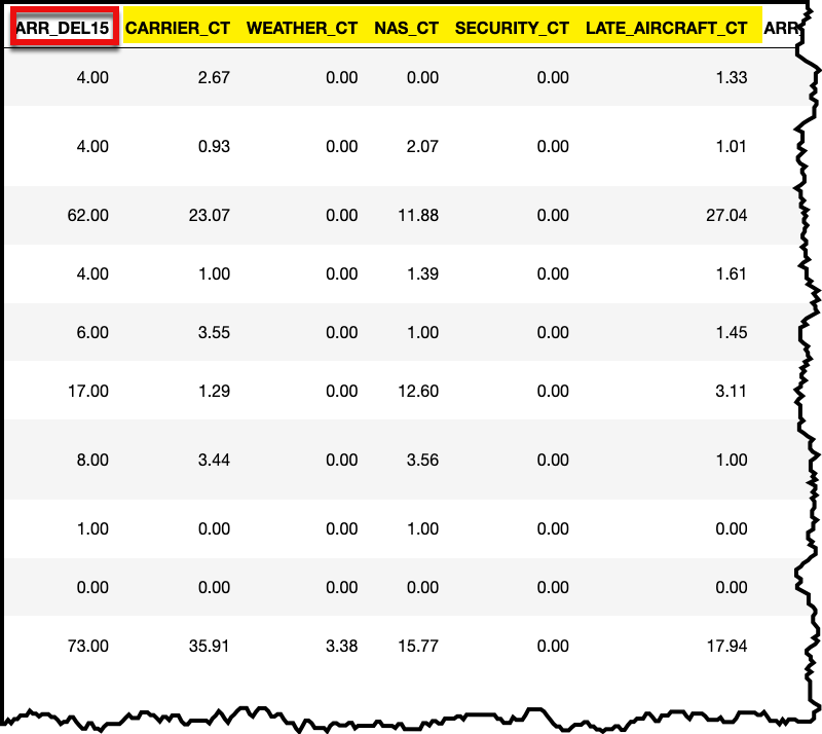
Figure 3 – Portion of the flight delay data highlighting the column relationships
Flight delay data analysis
In this final section, the actual data analysis and results of the flight delay data analysis will be highlighted.
After the flight delay tables and external files (Parquet format files) were created and data loaded, there were several queries executed to validate that the data was for the correct date range within each table and that valid data was loaded into all the tables (internal and external).
Once this data validation and table verification was complete, the data analysis of the flight delay data began.
The initial data analysis was performed on the data in the internal NPS database table to look at the current flight delay data (2019 – June 2022) using this query.

Figure 4 – Initial analysis on current flight delay data
The data was displayed using a bar graph as well to make it easier to understand.

Figure 5 – Bar graph of current flight delay data (2019 – June 2022)
In looking at this graph, it appears that 2022 has fewer flight delays than the other recent years of flight delay data, with the exception of 2020 (the height of the COVID-19 pandemic). However, the flight delay data for 2022 is for six months only (January – June) versus the 12-months of data for the years 2019 through 2021. Therefore, the data must be normalized to provide a true comparison of flight delays between 2019 through 2021 and the partial year’s data of 2022.
After the data is normalized by comparing the number of flight delays compared to the total number of flights, the data can provide a valid comparison from the 2019 through the June 2022 time-period.
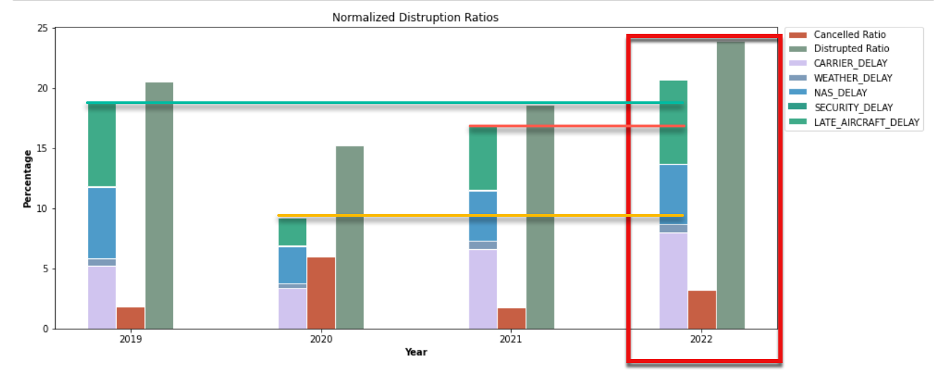
Figure 6 – There is a higher ratio of delayed flights in 2022 than in the period from 2019 – 2021
As Figure 6 highlights, when looking at the number of delayed flights compared to the total flights for the period, the flight delays in 2022 have increased over the prior years (2019 – 2021).
The next step in the analysis is to look at the historical flight delay data (2003 – 2018) to determine if the 2022 flight delays follow a historical pattern or if the flight delays have increased in 2022 due to the results of the pandemic period (airport staffing shortages, pilot shortages, and related factors).
Here is the initial query result on the historical flight delay data using a line graph output.
Figure 7 – Initial query using the historical data (2003 – 2018)

Figure 8 – Flight delays increased early in the historical years
After looking at the historical flight delay data from 2003–2018 at a high level, it was determined that the historical data should be separated into two separate time periods: 2003–2012 and 2013–2018. This separation was determined by analyzing the flight delays for each month of the year (January through December) and comparing the data for each of the historical years of data (2003–2018). With this flight delay comparison, the period from 2013–2018 had fewer flight delays for each month than the flight delay data for the period from 2003–2012.
The result of this query was output in a bar graph format to highlight the lower number of flight delays for the years from 2013–2018.

Figure 9 – Flight delays were lower during 2013 through 2018
The final analysis combines the historical flight delay data and illustrates the benefit of combining data from external AWS S3 parquet format and local Netezza format do a monthly analysis of the 2022 flight delay data (local Netezza) and graph it alongside the two historical periods (parquet): 2003–2012 and 2013–2018.

Figure 10 – The query to calculate monthly flight delays for 2022

Figure 11 – Flight delay comparison of 2022 (red) with historical period #1 (2003-2012) (blue) and historical period #2 (2013-2018) (green)
As the flight delay data graph indicates, the flight delays for 2022 are higher for every month from January through June (remember, the 2022 flight delay data is only through June) than the historical period #2 from 2013–2018. Only the oldest historical data (2003–2012) had flight delays comparable to 2022. Since the earlier analysis of current data (2019–June 2022) showed that 2022 had more flight delays than the period from 2019 through 2021, flight delays have increased in 2022 versus the last 10 years of flight delay data. This seems to indicate that the cause of the increased flight delays are factors related to the COVID-19 pandemic impacts to the airline industry.
A solution for quicker data analysis
The capabilities of NPS along with the ability to perform data analysis using Jupyter notebooks and integration with IBM Watson Studio as part of Cloud Pak for Data as a Service (with a free tier of usage) allow clients to perform data analysis quickly on a data set that can span the data warehouse and external Parquet format files in the cloud. This combination provides clients flexibility and cost savings by allowing them to host data in a storage medium based on application performance requirements, frequency of data access required, and budgetary constraints. By not requiring a client to move their data into the data warehouse, NPS can provide an advantage over other vendors such as Snowflake.
Supplemental section with additional details
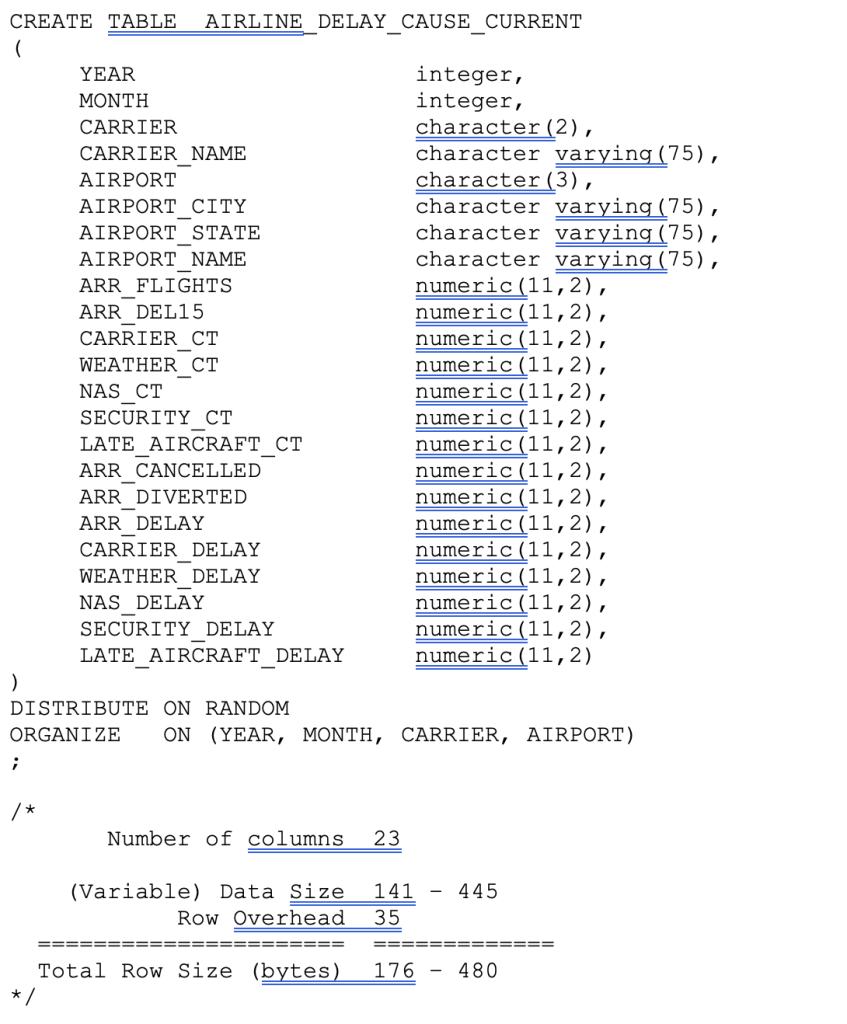
The SQL used to create the native Netezza table with current data (2019-June 2022)

The SQL to define a database source in Netezza for the cloud object storage bucket

The SQL to create external table for 2003 through 2018 from parquet files

The SQL to ‘create table as select’ from the parquet file
The post How to use Netezza Performance Server query data in Amazon Simple Storage Service (S3) appeared first on Journey to AI Blog.