Generative artificial intelligence (AI) provides an opportunity for improvements in healthcare by combining and analyzing structured and unstructured data across previously disconnected silos. Generative AI can help raise the bar on efficiency and effectiveness across the full scope of healthcare delivery.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. This unstructured data can impact the efficiency and productivity of clinical services, because it’s often found in various paper-based forms that can be difficult to manage and process. Streamlining the handling of this information is crucial for healthcare providers to improve patient care and optimize their operations.
Handling large volumes of data, extracting unstructured data from multiple paper forms or images, and comparing it with the standard or reference forms can be a long and arduous process, prone to errors and inefficiencies. However, advancements in generative AI solutions have introduced automated approaches that offer a more efficient and reliable solution for comparing multiple documents.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using the AWS tools without having to manage the infrastructure.
In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock large language model (LLM). Amazon Bedrock provides access to several LLMs, such as Anthropic Claude 3, which can be used to generate semi-structured data relevant to the healthcare industry. This can be particularly useful for creating various healthcare-related forms, such as patient intake forms, insurance claim forms, or medical history questionnaires.
Solution overview
To provide a high-level understanding of how the solution works before diving deeper into the specific elements and the services used, we discuss the architectural steps required to build our solution on AWS. We illustrate the key elements of the solution, giving you an overview of the various components and their interactions.
We then examine each of the key elements in more detail, exploring the specific AWS services that are used to build the solution, and discuss how these services work together to achieve the desired functionality. This provides a solid foundation for further exploration and implementation of the solution.
Part 1: Standard forms: Data extraction and storage
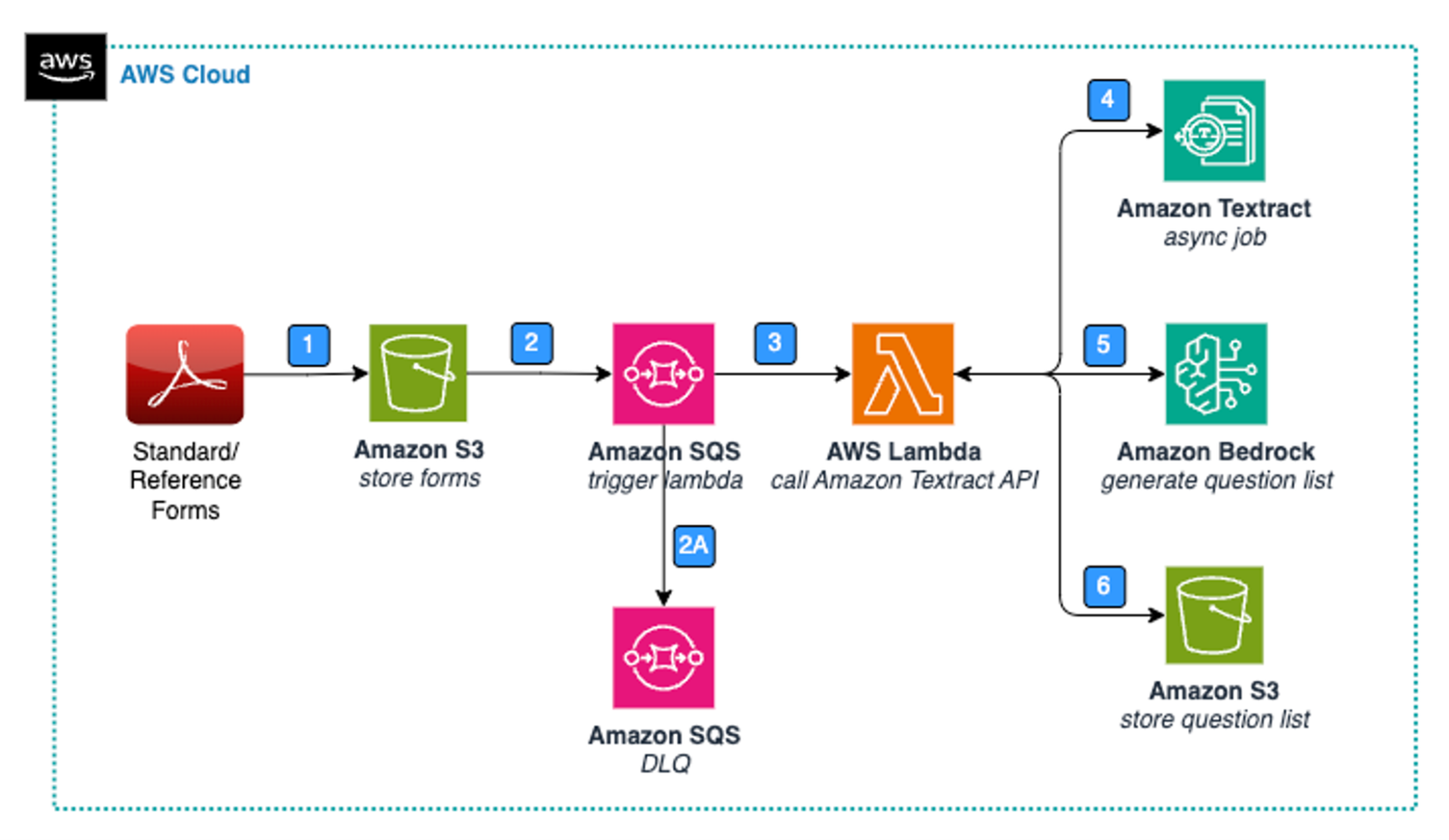
The following diagram highlights the key elements of a solution for data extraction and storage with standard forms.

Figure 1: Architecture – Standard Form – Data Extraction & Storage.
The Standard from processing steps are as follows:
- A user upload images of paper forms (PDF, PNG, JPEG) to Amazon Simple Storage Service (Amazon S3), a highly scalable and durable object storage service.
- Amazon Simple Queue Service (Amazon SQS) is used as the message queue. Whenever a new form is loaded, an event is invoked in Amazon SQS.
- If an S3 object is not processed, then after two tries it will be moved to the SQS dead-letter queue (DLQ), which can be configured further with an Amazon Simple Notification Service (Amazon SNS) topic to notify the user through email.
- The SQS message invokes an AWS Lambda The Lambda function is responsible for processing the new form data.
- The Lambda function reads the new S3 object and passes it to the Amazon Textract API to process the unstructured data and generate a hierarchical, structured output. Amazon Textract is an AWS service that can extract text, handwriting, and data from scanned documents and images. This approach allows for the efficient and scalable processing of complex documents, enabling you to extract valuable insights and data from various sources.
- The Lambda function passes the converted text to Anthropic Claude 3 on Amazon Bedrock Anthropic Claude 3 to generate a list of questions.
- Lastly, the Lambda function stores the question list in Amazon S3.
Amazon Bedrock API call to extract form details
We call an Amazon Bedrock API twice in the process for the following actions:
- Extract questions from the standard or reference form – The first API call is made to extract a list of questions and sub-questions from the standard or reference form. This list serves as a baseline or reference point for comparison with other forms. By extracting the questions from the reference form, we can establish a benchmark against which other forms can be evaluated.
- Extract questions from the custom form – The second API call is made to extract a list of questions and sub-questions from the custom form or the form that needs to be compared against the standard or reference form. This step is necessary because we need to analyze the custom form’s content and structure to identify its questions and sub-questions before we can compare them with the reference form.
By having the questions extracted and structured separately for both the reference and custom forms, the solution can then pass these two lists to the Amazon Bedrock API for the final comparison step. This approach maintains the following:
- Accurate comparison – The API has access to the structured data from both forms, making it straightforward to identify matches, mismatches, and provide relevant reasoning
- Efficient processing – Separating the extraction process for the reference and custom forms helps avoid redundant operations and optimizes the overall workflow
- Observability and interoperability – Keeping the questions separate enables better visibility, analysis, and integration of the questions from different forms
- Hallucination avoidance – By following a structured approach and relying on the extracted data, the solution helps avoid generating or hallucinating content, providing integrity in the comparison process
This two-step approach uses the capabilities of the Amazon Bedrock API while optimizing the workflow, enabling accurate and efficient form comparison, and promoting observability and interoperability of the questions involved.
See the following code (API Call):
User prompt to extract fields and list them
We provide the following user prompt to Anthropic Claude 3 to extract the fields from the raw text and list them for comparison as shown in step 3B (of Figure 3: Data Extraction & Form Field comparison).
The following figure illustrates the output from Amazon Bedrock with a list of questions from the standard or reference form.

Figure 2: Standard Form Sample Question List
Store this question list in Amazon S3 so it can be used for comparison with other forms, as shown in Part 2 of the process below.
Part 2: Data extraction and form field comparison
The following diagram illustrates the architecture for the next step, which is data extraction and form field comparison.

Figure 3: Data Extraction & Form Field comparison
Steps 1 and 2 are similar to those in Figure 1, but are repeated for the forms to be compared against the standard or reference forms. The next steps are as follows:
- The SQS message invokes a Lambda function. The Lambda function is responsible for processing the new form data.
- The raw text is extracted by Amazon Textract using a Lambda function. The extracted raw text is then passed to Step 3B for further processing and analysis.
- Anthropic Claude 3 generates a list of questions from the custom form that needs to be compared with the standard from. Then both forms and document question lists are passed to Amazon Bedrock, which compares the extracted raw text with standard or reference raw text to identify differences and anomalies to provide insights and recommendations relevant to the healthcare industry by respective category. It then generates the final output in JSON format for further processing and dashboarding. The Amazon Bedrock API call and user prompt from Step 5 (Figure 1: Architecture – Standard Form – Data Extraction & Storage) are reused for this step to generate a question list from the custom form.
We discuss Steps 4–6 in the next section.
The following screenshot shows the output from Amazon Bedrock with a list of questions from the custom form.

Figure 4: Custom Form Sample Question List
Final comparison using Anthropic Claude 3 on Amazon Bedrock:
The following examples show the results from the comparison exercise using Amazon Bedrock with Anthropic Claude 3, showing one that matched and one that didn’t match with the reference or standard form.
The following is the user prompt for forms comparison:
The following is the first call:
The following is the second call:
The following screenshot shows the questions matched with the reference form.

The following screenshot shows the questions that didn’t match with the reference form.


The steps from the preceding architecture diagram continue as follows:
4. The SQS queue invokes a Lambda function.
5. The Lambda function invokes an AWS Glue job and monitors for completion.
a. The AWS Glue job processes the final JSON output from the Amazon Bedrock model in tabular format for reporting.
6. Amazon QuickSight is used to create interactive dashboards and visualizations, allowing healthcare professionals to explore the analysis, identify trends, and make informed decisions based on the insights provided by Anthropic Claude 3.
The following screenshot shows a sample QuickSight dashboard.


Next steps
Many healthcare providers are investing in digital technology, such as electronic health records (EHRs) and electronic medical records (EMRs) to streamline data collection and storage, allowing appropriate staff to access records for patient care. Additionally, digitized health records provide the convenience of electronic forms and remote data editing for patients. Electronic health records offer a more secure and accessible record system, reducing data loss and facilitating data accuracy. Similar solutions can offer capturing the data in these paper forms into EHRs.
Conclusion
Generative AI solutions like Amazon Bedrock with Anthropic Claude 3 can significantly streamline the process of extracting and comparing unstructured data from paper forms or images. By automating the extraction of form fields and questions, and intelligently comparing them against standard or reference forms, this solution offers a more efficient and accurate approach to handling large volumes of data. The integration of AWS services like Lambda, Amazon S3, Amazon SQS, and QuickSight provides a scalable and robust architecture for deploying this solution. As healthcare organizations continue to digitize their operations, such AI-powered solutions can play a crucial role in improving data management, maintaining compliance, and ultimately enhancing patient care through better insights and decision-making.
About the Authors
 Satish Sarapuri is a Sr. Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure generative AI, data mesh, data lake, and analytics platform solutions on AWS, through which customers can make data-driven decisions to gain impactful outcomes for their business and help them on their digital and data transformation journey. In his spare time, he enjoys spending time with his family and playing tennis.
Satish Sarapuri is a Sr. Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure generative AI, data mesh, data lake, and analytics platform solutions on AWS, through which customers can make data-driven decisions to gain impactful outcomes for their business and help them on their digital and data transformation journey. In his spare time, he enjoys spending time with his family and playing tennis.
 Harpreet Cheema is a Machine Learning Engineer at the AWS Generative AI Innovation Center. He is very passionate in the field of machine learning and in tackling data-oriented problems. In his role, he focuses on developing and delivering machine learning focused solutions for customers across different domains.
Harpreet Cheema is a Machine Learning Engineer at the AWS Generative AI Innovation Center. He is very passionate in the field of machine learning and in tackling data-oriented problems. In his role, he focuses on developing and delivering machine learning focused solutions for customers across different domains.
 Deborah Devadason is a Senior Advisory Consultant in the Professional Service team at Amazon Web Services. She is a results-driven and passionate Data Strategy specialist with over 25 years of consulting experience across the globe in multiple industries. She leverages her expertise to solve complex problems and accelerate business-focused journeys, thereby creating a stronger backbone for the digital and data transformation journey.
Deborah Devadason is a Senior Advisory Consultant in the Professional Service team at Amazon Web Services. She is a results-driven and passionate Data Strategy specialist with over 25 years of consulting experience across the globe in multiple industries. She leverages her expertise to solve complex problems and accelerate business-focused journeys, thereby creating a stronger backbone for the digital and data transformation journey.