Embeddings represent real-world objects, like entities, text, images, or videos as an array of numbers (a.k.a vectors) that machine learning models can easily process. Embeddings are the building blocks of many ML applications such as semantic search, recommendations, clustering, outlier detection, named entity extraction, and more. Last year, we introduced support for text embeddings in BigQuery, allowing machine learning models to understand real-world data domains more effectively and earlier this year we introduced vector search, which lets you index and work with billions of embeddings and build generative AI applications on BigQuery.
At Next ’24, we announced further enhancement of embedding generation capabilities in BigQuery with support for:
Multimodal embeddings generation in BigQuery via Vertex AI’s multimodalembedding model, which lets you embed text and image data in the same semantic space
Embedding generation for structured data using PCA, Autoencoder or Matrix Factorization models that you train on your data in BigQuery
Multimodal embeddings
Multimodal embedding generates embedding vectors for text and image data in the same semantic space (vectors of items similar in meaning are closer together) and the generated embeddings have the same dimensionality (text and image embeddings are the same size). This enables a rich array of use cases such as embedding and indexing your images and then searching for them via text.
You can start using multimodal embedding in BigQuery using the following simple flow. If you like, you can take a look at our overview video which walks through a similar example.
Step 0: Create an object table which points to your unstructured data
You can work with unstructured data in BigQuery via object tables. For example, if you have your images stored in a Google Cloud Storage bucket on which you want to generate embeddings, you can create a BigQuery object table that points to this data without needing to move it.
To follow along the steps in this blog you will need to reuse an existing BigQuery CONNECTION or create a new one following instruction here. Ensure that the principal of the connection used has the ‘Vertex AI User’ role and that the Vertex AI API is enabled for your project. Once the connection is created you can create an object table as follows:
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE EXTERNAL TABLErn `bqml_tutorial.met_images`rnWITH CONNECTION `Location.ConnectionID`rnOPTIONSrn( object_metadata = ‘SIMPLE’,rn uris = [‘gs://gcs-public-data–met/*’]rn);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50d190>)])]>
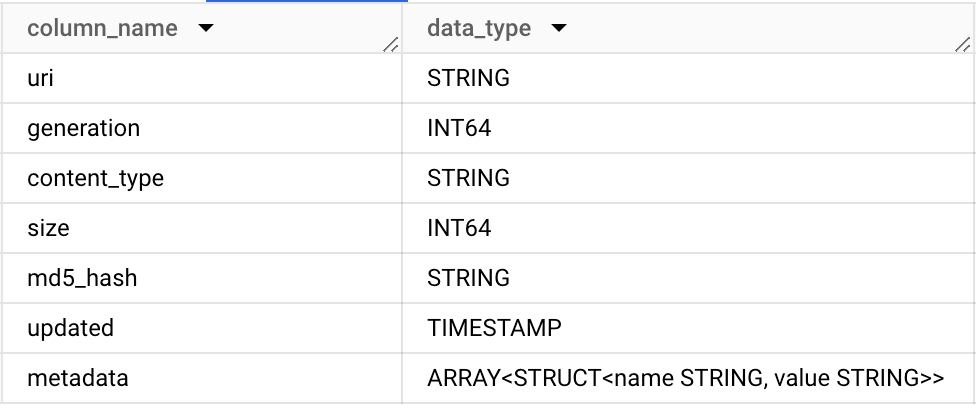
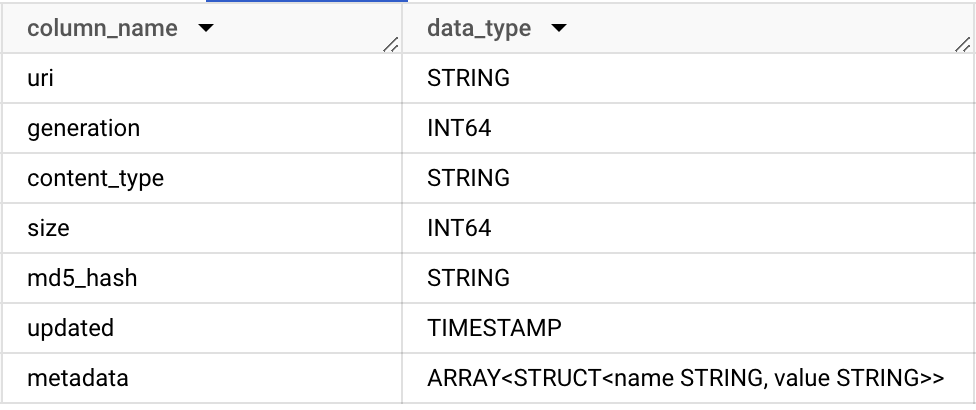
In this example, we are creating an object table that contains public domain art images from The Metropolitan Museum of Art (a.k.a. “The Met”) using a public Cloud Storage bucket that contains this data. The resulting object table has the following schema:
Let’s look at a sample of these images. You can do this using a BigQuery Studio Colab notebook by following instructions in this tutorial. As you can see, the images represent a wide range of objects and art pieces.
Image source: The Metropolitan Museum of Art
Now that we have the object table with images, let’s create embeddings for them.
Step 1: Create model
To generate embeddings, first create a BigQuery model that uses the Vertex AI hosted ‘multimodalembedding@001’ endpoint.
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE MODELrn bqml_tutorial.multimodal_embedding_model REMOTErnWITH CONNECTION `LOCATION.CONNNECTION_ID`rnOPTIONS (endpoint = ‘multimodalembedding@001’)”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50d040>)])]>
Note that while the multimodalembedding model supports embedding generation for text, it is specifically designed for cross-modal semantic search scenarios, for example, searching images given text. For text-only use cases, we recommend using the textembedding-gecko@ model instead.
Step 2: Generate embeddings
You can generate multimodal embeddings in BigQuery via the ML.GENERATE_EMBEDDING function. This function also works for generating text embeddings (via textembedding-gecko model) and structured data embeddings (via PCA, AutoEncoder and Matrix Factorization models). To generate embeddings, simply pass in the embedding model and the object table you created in previous steps to the ML.GENERATE_EMBEDDING function.
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE TABLE `bqml_tutorial.met_image_embeddings`rnASrnSELECT * FROM ML.GENERATE_EMBEDDING(rn MODEL `bqml_tutorial.multimodal_embedding_model`,rn TABLE `bqml_tutorial.met_images`)rnWHERE content_type = ‘image/jpeg’rnLimit 10000″), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50d550>)])]>
To reduce the tutorial’s runtime, we limit embedding generation to 10,000 images. This query will take 30 minutes to 2 hours to run. Once this step is completed you can see a preview of the output in BigQuery Studio. The generated embeddings have a dimension of 1408.

Step 3 (optional): Create a vector index on generated embeddings
While the embeddings generated in the previous step can be persisted and used directly in downstream models and applications, we recommend creating a vector index for improving embedding search performance and enabling the nearest-neighbor query pattern. You can learn more about vector search in BigQuery here.
- code_block
- <ListValue: [StructValue([(‘code’, “– Create a vector index on the embeddingsrnrnCREATE OR REPLACE VECTOR INDEX `met_images_index`rnON bqml_tutorial.met_image_embeddings(ml_generate_embedding_result)rnOPTIONS(index_type = ‘IVF’,rn distance_type = ‘COSINE’)”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50d790>)])]>
Step 4: Use embeddings for text-to-image (cross-modality) search
You can now use these embeddings in your applications. For example, to search for “pictures of white or cream colored dress from victorian era” you first embed the search string like so:
- code_block
- <ListValue: [StructValue([(‘code’, ‘– embed search stringrnrnCREATE OR REPLACE TABLE `bqml_tutorial.search_embedding`rnASrnSELECT * FROM ML.GENERATE_EMBEDDING(rn MODEL `bqml_tutorial.multimodal_embedding_model`,rn (rn SELECT “pictures of white or cream colored dress from victorian era” AS contentrn )rn)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50da00>)])]>
You can now use the embedded search string to find similar (nearest) image embeddings as follows:
- code_block
- <ListValue: [StructValue([(‘code’, ‘– use the embedded search string to search for imagesrnrnCREATE OR REPLACE TABLErn `bqml_tutorial.vector_search_results` ASrnSELECTrn base.uri AS gcs_uri,rn distancernFROMrn VECTOR_SEARCH( TABLE `bqml_tutorial.met_image_embeddings`,rn “ml_generate_embedding_result”,rn TABLE `bqml_tutorial.search_embedding`,rn “ml_generate_embedding_result”,rn top_k => 5)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e02ff50da30>)])]>
Step 5: Visualize results
Now let’s visualize the results along with the computed distance and see how we performed on the search query “pictures of white or cream colored dress from victorian era”. Refer the accompanying tutorial on how to render this output using a BigQuery notebook.
Image source: The Metropolitan Museum of Art
The results look quite good!
Wrapping up
In this blog, we demonstrated a common vector search usage pattern but there are many other use cases for embeddings. For example, with multimodal embeddings you can perform zero-shot classification of images by converting a table of images and a separate table containing sentence-like labels to embeddings. You can then classify images by computing distance between images and each descriptive label’s embedding. You can also use these embeddings as input for training other ML models, such as clustering models in BigQuery to help you discover hidden groupings in your data. Embeddings are also useful wherever you have free text input as a feature, for example, embeddings of user reviews or call transcripts can be used in a churn prediction model, embeddings of images of a house can be used as input features in a price prediction model etc. You can even use embeddings instead of categorical text data when such categories have semantic meaning, for example, product categories in a deep-learning recommendation model.
In addition to multimodal and text embeddings, BigQuery also supports generating embeddings on structured data using PCA, AUTOENCODER and Matrix Factorization models that have been trained on your data in BigQuery. These embeddings have a wide range of use cases. For example, embeddings from PCA and AUTOENCODER models can be used for anomaly detection (embeddings further away from other embeddings are deemed anomalies) and as input features to other models, for example, a sentiment classification model trained on embeddings from an autoencoder. Matrix Factorization models are classically used for recommendation problems, and you can use them to generate user and item embeddings. Then, given a user embedding you can find the nearest item embeddings and recommend these items, or cluster users so that they can be targeted with specific promotions.
To generate such embeddings, first use the CREATE MODEL function to create a PCA, AutoEncoder or Matrix Factorization model and pass in your data as input, and then use ML.GENERATE_EMBEDDING function providing the model, and a table input to generate embeddings on this data.
Getting started
Support for multimodal embeddings and support for embeddings on structured data in BigQuery is now available in preview. Get started by following our documentation and tutorials. Have feedback? Let us know what you think at bqml-feedback@google.com.