Posted by AJ Piergiovanni and Anelia Angelova, Research Scientists, Google Research
Vision-language foundational models are built on the premise of a single pre-training followed by subsequent adaptation to multiple downstream tasks. Two main and disjoint training scenarios are popular: a CLIP-style contrastive learning and next-token prediction. Contrastive learning trains the model to predict if image-text pairs correctly match, effectively building visual and text representations for the corresponding image and text inputs, whereas next-token prediction predicts the most likely next text token in a sequence, thus learning to generate text, according to the required task. Contrastive learning enables image-text and text-image retrieval tasks, such as finding the image that best matches a certain description, and next-token learning enables text-generative tasks, such as Image Captioning and Visual Question Answering (VQA). While both approaches have demonstrated powerful results, when a model is pre-trained contrastively, it typically does not fare well on text-generative tasks and vice-versa. Furthermore, adaptation to other tasks is often done with complex or inefficient methods. For example, in order to extend a vision-language model to videos, some models need to do inference for each video frame separately. This limits the size of the videos that can be processed to only a few frames and does not fully take advantage of motion information available across frames.
Motivated by this, we present “A Simple Architecture for Joint Learning for MultiModal Tasks”, called MaMMUT, which is able to train jointly for these competing objectives and which provides a foundation for many vision-language tasks either directly or via simple adaptation. MaMMUT is a compact, 2B-parameter multimodal model that trains across contrastive, text generative, and localization-aware objectives. It consists of a single image encoder and a text decoder, which allows for a direct reuse of both components. Furthermore, a straightforward adaptation to video-text tasks requires only using the image encoder once and can handle many more frames than prior work. In line with recent language models (e.g., PaLM, GLaM, GPT3), our architecture uses a decoder-only text model and can be thought of as a simple extension of language models. While modest in size, our model outperforms the state of the art or achieves competitive performance on image-text and text-image retrieval, video question answering (VideoQA), video captioning, open-vocabulary detection, and VQA.
 |
 |
 |
| The MaMMUT model enables a wide range of tasks such as image-text/text-image retrieval (top left and top right), VQA (middle left), open-vocabulary detection (middle right), and VideoQA (bottom). |
Decoder-only model architecture
One surprising finding is that a single language-decoder is sufficient for all these tasks, which obviates the need for both complex constructs and training procedures presented before. For example, our model (presented to the left in the figure below) consists of a single visual encoder and single text-decoder, connected via cross attention, and trains simultaneously on both contrastive and text-generative types of losses. Comparatively, prior work is either not able to handle image-text retrieval tasks, or applies only some losses to only some parts of the model. To enable multimodal tasks and fully take advantage of the decoder-only model, we need to jointly train both contrastive losses and text-generative captioning-like losses.
 |
| MaMMUT architecture (left) is a simple construct consisting of a single vision encoder and a single text decoder. Compared to other popular vision-language models — e.g., PaLI (middle) and ALBEF, CoCa (right) — it trains jointly and efficiently for multiple vision-language tasks, with both contrastive and text-generative losses, fully sharing the weights between the tasks. |
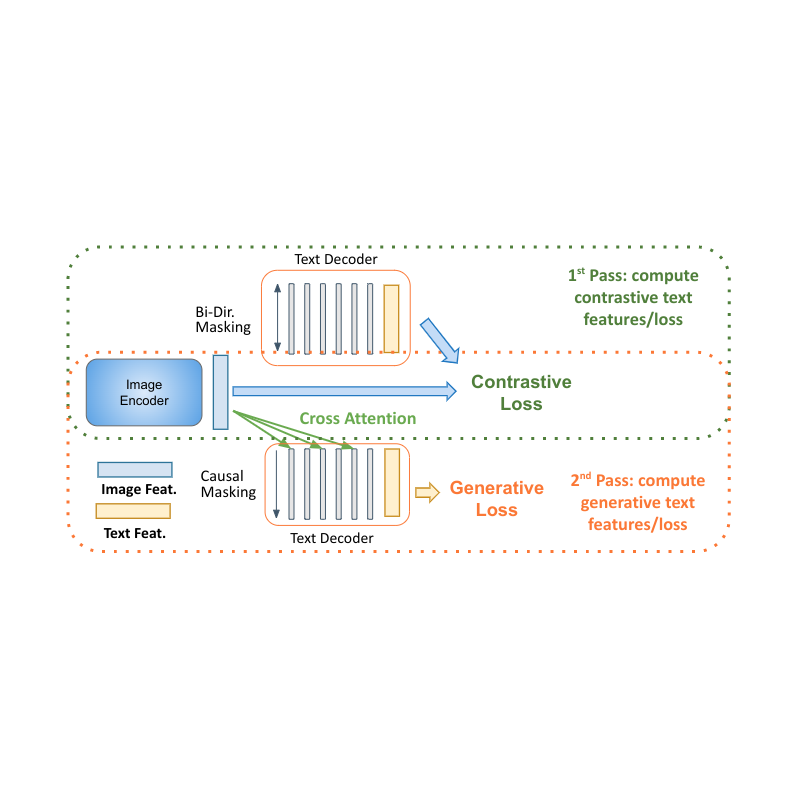
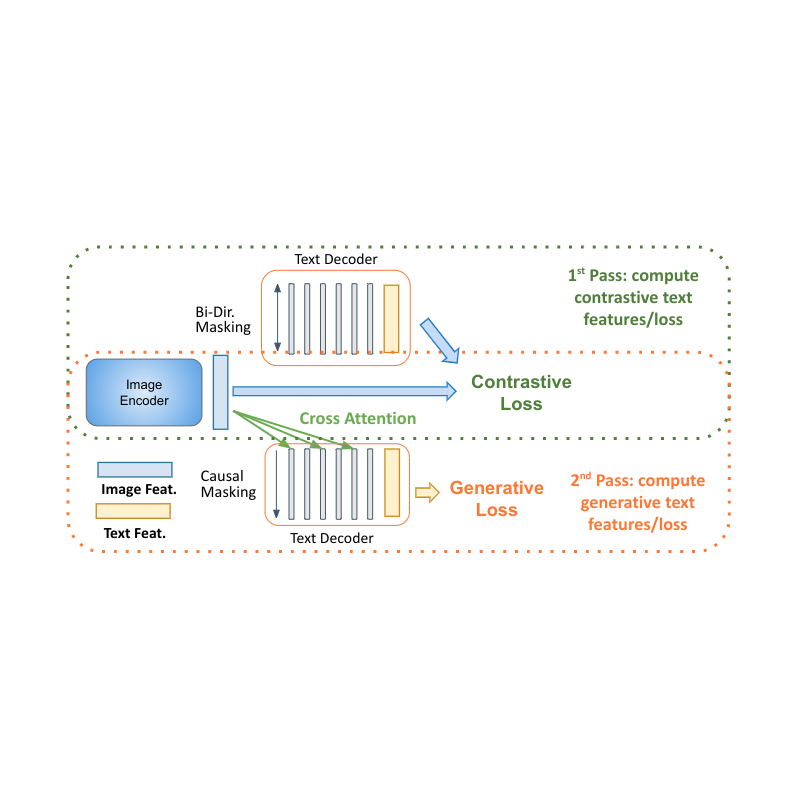
Decoder two-pass learning
Decoder-only models for language learning show clear advantages in performance with smaller model size (almost half the parameters). The main challenge for applying them to multimodal settings is to unify the contrastive learning (which uses unconditional sequence-level representation) with captioning (which optimizes the likelihood of a token conditioned on the previous tokens). We propose a two-pass approach to jointly learn these two conflicting types of text representations within the decoder. During the first pass, we utilize cross attention and causal masking to learn the caption generation task — the text features can attend to the image features and predict the tokens in sequence. On the second pass, we disable the cross-attention and causal masking to learn the contrastive task. The text features will not see the image features but can attend bidirectionally to all text tokens at once to produce the final text-based representation. Completing this two-pass approach within the same decoder allows for accommodating both types of tasks that were previously hard to reconcile. While simple, we show that this model architecture is able to provide a foundation for multiple multimodal tasks.
 |
| MaMMUT decoder-only two-pass learning enables both contrastive and generative learning paths by the same model. |
Another advantage of our architecture is that, since it is trained for these disjoint tasks, it can be seamlessly applied to multiple applications such as image-text and text-image retrieval, VQA, and captioning.
Moreover, MaMMUT easily adapts to video-language tasks. Previous approaches used a vision encoder to process each frame individually, which required applying it multiple times. This is slow and restricts the number of frames the model can handle, typically to only 6–8. With MaMMUT, we use sparse video tubes for lightweight adaptation directly via the spatio-temporal information from the video. Furthermore, adapting the model to Open-Vocabulary Detection is done by simply training to detect bounding-boxes via an object-detection head.
 |
| Adaptation of the MaMMUT architecture to video tasks (left) is simple and fully reuses the model. This is done by generating a video “tubes” feature representation, similar to image patches, that are projected to lower dimensional tokens and run through the vision encoder. Unlike prior approaches (right) that need to run multiple individual images through the vision encoder, we use it only once. |
Results
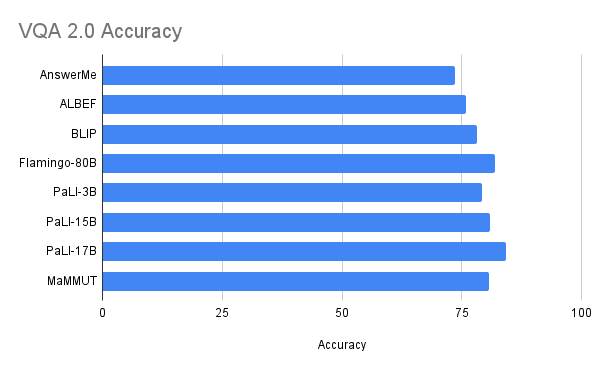
Our model achieves excellent zero-shot results on image-text and text-image retrieval without any adaptation, outperforming all previous state-of-the-art models. The results on VQA are competitive with state-of-the-art results, which are achieved by much larger models. The PaLI model (17B parameters) and the Flamingo model (80B) have the best performance on the VQA2.0 dataset, but MaMMUT (2B) has the same accuracy as the 15B PaLI.
 |
| MaMMUT outperforms the state of the art (SOTA) on Zero-Shot Image-Text (I2T) and Text-Image (T2I) retrieval on both MS-COCO (top) and Flickr (bottom) benchmarks. |
|
| Performance on the VQA2.0 dataset is competitive but does not outperform large models such as Flamingo-80B and PalI-17B. Performance is evaluated in the more challenging open-ended text generation setting. |
MaMMUT also outperforms the state-of-the-art on VideoQA, as shown below on the MSRVTT-QA and MSVD-QA datasets. Note that we outperform much bigger models such as Flamingo, which is specifically designed for image+video pre-training and is pre-trained with both image-text and video-text data.
|
| MaMMUT outperforms the SOTA models on VideoQA tasks (MSRVTT-QA dataset, top, MSVD-QA dataset, bottom), outperforming much larger models, e.g., the 5B GIT2 or Flamingo, which uses 80B parameters and is pre-trained for both image-language and vision-language tasks. |
Our results outperform the state-of-the-art on open-vocabulary detection fine-tuning as is also shown below.
Key ingredients
We show that joint training of both contrastive and text-generative objectives is not an easy task, and in our ablations we find that these tasks are served better by different design choices. We see that fewer cross-attention connections are better for retrieval tasks, but more are preferred by VQA tasks. Yet, while this shows that our model’s design choices might be suboptimal for individual tasks, our model is more effective than more complex, or larger, models.
|
| Ablation studies showing that fewer cross-attention connections (1-2) are better for retrieval tasks (top), whereas more connections favor text-generative tasks such as VQA (bottom). |
Conclusion
We presented MaMMUT, a simple and compact vision-encoder language-decoder model that jointly trains a number of conflicting objectives to reconcile contrastive-like and text-generative tasks. Our model also serves as a foundation for many more vision-language tasks, achieving state-of-the-art or competitive performance on image-text and text-image retrieval, videoQA, video captioning, open-vocabulary detection and VQA. We hope it can be further used for more multimodal applications.
Acknowledgements
The work described is co-authored by: Weicheng Kuo, AJ Piergiovanni, Dahun Kim, Xiyang Luo, Ben Caine, Wei Li, Abhijit Ogale, Luowei Zhou, Andrew Dai, Zhifeng Chen, Claire Cui, and Anelia Angelova. We would like to thank Mojtaba Seyedhosseini, Vijay Vasudevan, Priya Goyal, Jiahui Yu, Zirui Wang, Yonghui Wu, Runze Li, Jie Mei, Radu Soricut, Qingqing Huang, Andy Ly, Nan Du, Yuxin Wu, Tom Duerig, Paul Natsev, Zoubin Ghahramani for their help and support.