Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Use cases such as fraud detection, product recommendations, and traffic prediction are examples where milliseconds matter and are critical for business success. Strict service level agreements (SLAs) need to be met, and a typical request may require multiple steps such as preprocessing, data transformation, feature engineering, model selection logic, model aggregation, and postprocessing.
Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Each model has its own merits and dependencies based on the external data sources as well as runtime environment such as CPU/GPU power of the underlying compute resources. An application may require multiple ML models to serve a single inference request. In certain scenarios, a request may flow across multiple models. There is no one-size-fits-all approach, and it’s important for ML practitioners to look for tried-and-proven methods to address recurring ML hosting challenges. This has led to the evolution of design patterns for ML model hosting.
In this post, we explore common design patterns for building ML applications on Amazon SageMaker.
Design patterns for building ML applications
Let’s look at the following design patterns to use for hosting ML applications.
Single-model based ML applications
This is a great option when your ML use case requires a single model to serve a request. The model is deployed on a dedicated compute infrastructure with the ability to scale based on the input traffic. This option is also ideal when the client application has a low-latency (in the order of milliseconds or seconds) inference requirement.
Multi-model based ML applications
To make hosting more cost-effective, this design pattern allows you to host multiple models on the same tenant infrastructure. Multiple ML models can share the host or container resources, including caching the most-used ML models in the memory, resulting in better utilization of memory and compute resources. Depending on the types of the models you chose to deploy, model co-hosting may use the following methods:
- Multi-model hosting – This option allows you to host multiple models using a shared serving container on a single endpoint. This feature is ideal when you have a large number of similar models that you can serve through a shared serving container and don’t need to access all the models at the same time.
- Multi-container hosting – This option is ideal when you have multiple models running on different serving stacks with similar resource needs, and when individual models don’t have sufficient traffic to utilize the full capacity of the endpoint instances. Multi-container hosting allows you to deploy multiple containers that use different models or frameworks on a single endpoint. The models can be completely heterogenous, with their own independent serving stack.
- Model ensembles – In a lot of production use cases, there can often be many upstream models feeding inputs to a given downstream model. This is where ensembles are useful. Ensemble patterns involve mixing output from one or more base models in order to reduce the generalization error of the prediction. The base models can be diverse and trained by different algorithms. Model ensembles can out-perform single models because the prediction error of the model decreases when the ensemble approach is used.
The following are common use cases of ensemble patterns and their corresponding design pattern diagrams:
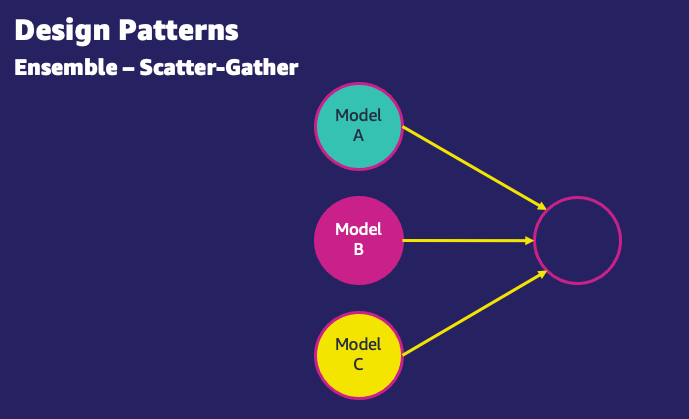
- Scatter-gather – In a scatter-gather pattern, a request for inference is routed to a number of models. An aggregator is then used to collect the responses and distill them into a single inference response. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.

- Model aggregate – In an aggregation pattern, outputs from multiple models are averaged. For classification models, multiple models’ predictions are evaluated to determine the class that received the most votes and is treated as the final output of the ensemble. For example, in a two-class classification problem to classify a set of fruits as oranges or apples, if two models vote for an orange and one model votes for an apple, then the aggregated output will be an orange. Aggregation helps combat inaccuracy in individual models and makes the output more accurate.

- Dynamic selection – Another pattern for ensemble models is to dynamically perform model selection for the given input attributes. For example, in a given input of images of fruits, if the input contains an orange, model A will be used because it’s specialized for oranges. If the input contains an apple, model B will be used because it’s specialized for apples.

- Serial inference ML applications – With a serial inference pattern, also known as an inference pipeline, use cases have requirements to preprocess incoming data before invoking a pre-trained ML model for generating inferences. Additionally, in some cases, the generated inferences may need to be processed further, so that they can be easily consumed by downstream applications. An inference pipeline allows you to reuse the same preprocessing code used during model training to process the inference request data used for predictions.

- Business logic – Productionizing ML always involves business logic. Business logic patterns involve everything that’s needed to perform an ML task that is not ML model inference. This includes loading the model from Amazon Simple Storage Service (Amazon S3), for example, database lookups to validate the input, obtaining pre-computed features from the feature store, and so on. After these business logic steps are complete, the inputs are passed through to ML models.

ML inference options
For model deployment, it’s important to work backward from your use case. What is the frequency of the prediction? Do you expect live traffic to your application and real-time response to your clients? Do you have many models trained for different subsets of data for the same use case? Does the prediction traffic fluctuate? Is latency of inference a concern? Based on these details, all the preceding design patterns can be implemented using the following deployment options:
- Real-time inference – Real-time inference is ideal for inference workloads where you have real-time, interactive, low-latency requirements. Real-time ML inference workloads may include a single-model based ML application, where an application requires only one ML model to serve a single request, or a multi-model based ML application, where an application requires multiple ML models to serve a single request.
- Near-real-time (asynchronous) inference – With-near-real time inference, you can queue incoming requests. This can be utilized for running inference on inputs that are hundreds of MBs. It operates in near-real time and allows users to use the input for inference, and read the output from the endpoint from an S3 bucket. It can especially be handy in cases with NLP and computer vision, where there are large payloads that require longer preprocessing times.
- Batch inference – Batch inference can be utilized for running inference offline on a large dataset. Because it runs offline, batch inference doesn’t offer the lowest latency. Here, the inference request is processed with either a scheduled or event-based trigger of a batch inference job.
- Serverless inference – Serverless inference is ideal for workloads that have idle periods between traffic spurts and can tolerate a few extra seconds of latency (cold start) for the first invocation after an idle period. For example, a chatbot service or an application to process forms or analyze data from documents. In this case, you might want an online inference option that is able to automatically provision and scale compute capacity based on the volume of inference requests. And during idle time, it should be able to turn off compute capacity completely so that you’re not charged. Serverless inference takes away the undifferentiated heavy lifting of selecting and managing servers by automatically launching compute resources and scaling them in and out depending on traffic.
Use fitness functions to select the right ML inference option
Deciding on the right hosting option is important because it impacts the end-users rendered by your applications. For this purpose, we’re borrowing the concept of fitness functions, which was coined by Neal Ford and his colleagues from AWS Partner ThoughtWorks in their work Building Evolutionary Architectures. Fitness functions provide a prescriptive assessment of various hosting options based on the customer’s objectives. Fitness functions help you obtain the necessary data to allow for the planned evolution of your architecture. They set measurable values to assess how close your solution is to achieving your set goals. Fitness functions can and should be adapted as the architecture evolves to guide a desired change process. This provides architects with a tool to guide their teams while maintaining team autonomy.
There are five main fitness functions that customers care about when it comes to selecting the right ML inference option for hosting their ML models and applications.
| Fitness function | Description |
| Cost | To deploy and maintain an ML model and ML application on a scalable framework is a critical business process, and the costs may vary greatly depending on choices made about model hosting infrastructure, hosting option, ML frameworks, ML model characteristics, optimizations, scaling policy, and more. The workloads must utilize the hardware infrastructure optimally to ensure that the cost remains in check. This fitness function specifically refers to the infrastructure cost, which is a part of overall total cost of ownership (TCO). The infrastructure costs are the combined costs for storage, network, and compute. It’s also critical to understand other components of TCO, including operational costs and security and compliance costs. Operational costs are the combined costs of operating, monitoring, and maintaining the ML infrastructure. The operational costs are calculated as the number of engineers required based on each scenario and the annual salary of engineers, aggregated over a specific period. Customers using self-managed ML solutions on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), and Amazon Elastic Kubernetes Service (Amazon EKS) need to build operational tooling themselves. Customers using SageMaker incur significantly less TCO. SageMaker inference is a fully managed service and provides capabilities out of the box for deploying ML models for inference. You don’t need to provision instances, monitor instance health, manage security updates or patches, emit operational metrics, or build monitoring for your ML inference workloads. It has built-in capabilities to ensure high availability and resiliency. SageMaker supports security with end-to-end encryption at rest and in transit, including encryption of the root volume and Amazon Elastic Block Store (Amazon EBS) volume, Amazon Virtual Private Cloud (Amazon VPC) support, AWS PrivateLink, customer-managed keys, AWS Identity and Access Management (IAM) fine-grained access control, AWS CloudTrail audits, internode encryption for training, tag-based access control, network isolation, and Interactive Application Proxy. All of these security features are provided out of the box in SageMaker, and can save businesses tens of development months of engineering effort over a 3-year period. SageMaker is a HIPAA-eligible service, and is certified under PCI, SOC, GDPR, and ISO. SageMaker also supports FIPS endpoints. For more information about TCO, refer to The total cost of ownership of Amazon SageMaker. |
| Inference latency | Many ML models and applications are latency critical, in which the inference latency must be within the bounds specified by a service level objective. Inference latency depends upon a multitude of factors, including model size and complexity, hardware platform, software environment, and network architecture. For example, larger and more complex models can take longer to run inference. |
| Throughput (transactions per second) | For model inference, optimizing throughput is crucial for performance tuning and achieving the business objective of the ML application. As we continue to advance rapidly in all aspects of ML, including low-level implementations of mathematical operations in chip design, hardware-specific libraries play a greater role in performance optimization. Various factors such as payload size, network hops, nature of hops, model graph features, operators in the model, and the CPU, GPU, and memory profile of the model hosting instances affect the throughput of the ML model. |
| Scaling configuration complexity | It’s crucial for the ML models or applications to run on a scalable framework that can handle the demand of varying traffic. It also allows for the maximum utilization of CPU and GPU resources and prevents over-provisioning of compute resources. |
| Expected traffic pattern | ML models or applications can have different traffic patterns, ranging from continuous real-time live traffic to periodic peaks of thousands of requests per second, and from infrequent, unpredictable request patterns to offline batch requests on larger datasets. Working backward from the expected traffic pattern is recommended in order to select the right hosting option for your ML model. |
Deploying models with SageMaker
SageMaker is a fully managed AWS service that provides every developer and data scientist with the ability to quickly build, train, and deploy ML models at scale. With SageMaker inference, you can deploy your ML models on hosted endpoints and get inference results. SageMaker provides a wide selection of hardware and features to meet your workload requirements, allowing you to select over 70 instance types with hardware acceleration. SageMaker can also provide inference instance type recommendation using a new feature called SageMaker Inference Recommender, in case you’re not sure which one would be most optimal for your workload.
You can choose deployment options to best meet your use cases, such as real time inference, asynchronous, batch, and even serverless endpoints. In addition, SageMaker offers various deployment strategies such as canary, blue/green, shadow, and A/B testing for model deployment, along with cost-effective deployment with multi-model, multi-container endpoints, and elastic scaling. With SageMaker inference, you can view the performance metrics for your endpoints in Amazon CloudWatch, automatically scale endpoints based on traffic, and update your models in production without losing any availability.
SageMaker offers four options to deploy your model so you can start making predictions:
- Real-time inference – This is suitable for workloads with millisecond latency requirements, payload sizes up to 6 MB, and processing times of up to 60 seconds.
- Batch transform – This is ideal for offline predictions on large batches of data that are available up-front.
- Asynchronous inference – This is designed for workloads that don’t have sub-second latency requirements, payload sizes up to 1 GB, and processing times of up to 15 minutes.
- Serverless inference – With serverless inference, you can quickly deploy ML models for inference without having to configure or manage the underlying infrastructure. Additionally, you pay only for the compute capacity used to process inference requests, which is ideal for intermittent workloads.
The following diagram can help you understand the SageMaker hosting model deployment options along with the associated fitness function evaluations.

Let’s explore each of the deployment options in more detail.
Real-time inference in SageMaker
SageMaker real-time inference is recommended if you have sustained traffic and need lower and consistent latency for your requests with payload sizes up to 6 MB, and processing times of up to 60 seconds. You deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. These endpoints are fully managed and support auto scaling. Real-time inference is popular for use cases where you expect a low-latency, synchronous response with predictable traffic patterns, such as personalized recommendations for products and services or transactional fraud detection use cases.
Typically, a client application sends requests to the SageMaker HTTPS endpoint to obtain inferences from a deployed model. You can deploy multiple variants of a model to the same SageMaker HTTPS endpoint. This is useful for testing variations of a model in production. Auto scaling allows you to dynamically adjust the number of instances provisioned for a model in response to changes in your workload.
The following table provides guidance on evaluating SageMaker real-time inference based on the fitness functions.
| Fitness function | Description |
| Cost | Real-time endpoints offer synchronous response to inference requests. Because the endpoint is always running and available to provide real-time synchronous inference response, you pay for using the instance. Costs can quickly add up when you deploy multiple endpoints, especially if the endpoints don’t fully utilize the underlying instances. Choosing the right instance for your model helps ensure you have the most performant instance at the lowest cost for your models. Auto scaling is recommended to dynamically adjust the capacity depending on traffic to maintain steady and predictable performance at the possible lowest cost. SageMaker extends access to Graviton2 and Graviton3-based ML instance families. AWS Graviton processors are custom built by Amazon Web Services using 64-bit Arm Neoverse cores to deliver the best price performance for your cloud workloads running on Amazon EC2. With Graviton-based instances, you have more options for optimizing the cost and performance when deploying your ML models on SageMaker. SageMaker also supports Inf1 instances, providing high performance and cost-effective ML inference. With 1–16 AWS Inferentia chips per instance, Inf1 instances can scale in performance and deliver up to three times higher throughput and up to 50% lower cost per inference compared to the AWS GPU-based instances. To use Inf1 instances in SageMaker, you can compile your trained models using Amazon SageMaker Neo and select the Inf1 instances to deploy the compiled model on SageMaker. You can also explore Savings Plans for SageMaker to benefit from cost savings up to 64% compared to the on-demand price. When you create an endpoint, SageMaker attaches an EBS storage volume to each ML compute instance that hosts the endpoint. The size of the storage volume depends on the instance type. Additional cost for real-time endpoints includes cost of GB-month of provisioned storage, plus GB data processed in and GB data processed out of the endpoint instance. |
| Inference latency | Real-time inference is ideal when you need a persistent endpoint with millisecond latency requirements. It supports payload sizes up to 6 MB, and processing times of up to 60 seconds. |
| Throughput | An ideal value of inference throughput is subjective to factors such as model, model input size, batch size, and endpoint instance type. As a best practice, review CloudWatch metrics for input requests and resource utilization, and select the appropriate instance type to achieve optimal throughput. A business application can be either throughput optimized or latency optimized. For example, dynamic batching can help increase the throughput for latency-sensitive apps using real-time inference. However, there are limits to batch size, without which the inference latency could be affected. Inference latency will grow as you increase the batch size to improve throughput. Therefore, real-time inference is an ideal option for latency-sensitive applications. SageMaker provides options of asynchronous inference and batch transform, which are optimized to give higher throughput compared to real-time inference if the business applications can tolerate a slightly higher latency. |
| Scaling configuration complexity | SageMaker real-time endpoints support auto scaling out of the box. When the workload increases, auto scaling brings more instances online. When the workload decreases, auto scaling removes unnecessary instances, helping you reduce your compute cost. Without auto scaling, you need to provision for peak traffic or risk model unavailability. Unless the traffic to your model is steady throughout the day, there will be excess unused capacity. This leads to low utilization and wasted resources. With SageMaker, you can configure different scaling options based on the expected traffic pattern. Simple scaling or target tracking scaling is ideal when you want to scale based on a specific CloudWatch metric. You can do this by choosing a specific metric and setting threshold values. The recommended metrics for this option are average If you require advanced configuration, you can set a step scaling policy to dynamically adjust the number of instances to scale based on the size of the alarm breach. This helps you configure a more aggressive response when demand reaches a certain level. You can use a scheduled scaling option when you know that the demand follows a particular schedule in the day, week, month, or year. This helps you specify a one-time schedule or a recurring schedule or cron expressions along with start and end times, which form the boundaries of when the auto scaling action starts and stops. For more details, refer to Configuring autoscaling inference endpoints in Amazon SageMaker and Load test and optimize an Amazon SageMaker endpoint using automatic scaling. |
| Traffic pattern | Real-time inference is ideal for workloads with a continual or regular traffic pattern. |
Asynchronous inference in SageMaker
SageMaker asynchronous inference is a new capability in SageMaker that queues incoming requests and processes them asynchronously. This option is ideal for requests with large payload sizes (up to 1 GB), long processing times (up to 15 minutes), and near-real-time latency requirements. Example workloads for asynchronous inference include healthcare companies processing high-resolution biomedical images or videos like echocardiograms to detect anomalies. These applications receive bursts of incoming traffic at different times in the day and require near-real-time processing at low cost. Processing times for these requests can range in the order of minutes, eliminating the need to run real-time inference. Instead, input payloads can be processed asynchronously from an object store like Amazon S3 with automatic queuing and a predefined concurrency threshold. Upon processing, SageMaker places the inference response in the previously returned Amazon S3 location. You can optionally choose to receive success or error notifications via Amazon Simple Notification Service (Amazon SNS).
The following table provides guidance on evaluating SageMaker asynchronous inference based on the fitness functions.
| Fitness function | Description |
| Cost | Asynchronous inference is a great choice for cost-sensitive workloads with large payloads and burst traffic. Asynchronous inference enables you to save on costs by auto scaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests. Requests that are received when there are zero instances are queued for processing after the endpoint scales up. |
| Inference latency | Asynchronous inference is ideal for near-real-time latency requirements. The requests are placed in a queue and processed as soon as the compute is available. This typically results in tens of milliseconds in latency. |
| Throughput | Asynchronous inference is ideal for non-latency sensitive use cases, because applications don’t have to compromise on throughput. Requests aren’t dropped during traffic spikes because the asynchronous inference endpoint queues up requests rather than dropping them. |
| Scaling configuration complexity | SageMaker supports auto scaling for asynchronous endpoint. Unlike real-time hosted endpoints, asynchronous inference endpoints support scaling down instances to zero by setting the minimum capacity to zero. For asynchronous endpoints, SageMaker strongly recommends that you create a policy configuration for target-tracking scaling for a deployed model (variant). For use cases that can tolerate a cold start penalty of a few minutes, you can optionally scale down the endpoint instance count to zero when there are no outstanding requests and scale back up as new requests arrive so that you only pay for the duration that the endpoints are actively processing requests. |
| Traffic pattern | Asynchronous endpoints queue incoming requests and process them asynchronously. They’re a good option for intermittent or infrequent traffic patterns. |
Batch inference in SageMaker
SageMaker batch transform is ideal for offline predictions on large batches of data that are available up-front. The batch transform feature is a high-performance and high-throughput method for transforming data and generating inferences. It’s ideal for scenarios where you’re dealing with large batches of data, don’t need subsecond latency, or need to both preprocess and transform the training data. Customers in certain domains such as advertising and marketing or healthcare often need to make offline predictions on hyperscale datasets where high throughput is often the objective of the use case and latency isn’t a concern.
When a batch transform job starts, SageMaker initializes compute instances and distributes the inference workload between them. It releases the resources when the jobs are complete, so you pay only for what was used during the run of your job. When the job is complete, SageMaker saves the prediction results in an S3 bucket that you specify. Batch inference tasks are usually good candidates for horizontal scaling. Each worker within a cluster can operate on a different subset of data without the need to exchange information with other workers. AWS offers multiple storage and compute options that enable horizontal scaling. Example workloads for SageMaker batch transform include offline applications such as banking applications for predicting customer churn where an offline job can be scheduled to run periodically.
The following table provides guidance on evaluating SageMaker batch transform based on the fitness functions.
| Fitness function | Description |
| Cost | SageMaker batch transform allows you to run predictions on large or small batch datasets. You are charged for the instance type you choose, based on the duration of use. SageMaker manages the provisioning of resources at the start of the job and releases them when the job is complete. There is no additional data processing cost. |
| Inference latency | You can use event-based or scheduled invocation. Latency could vary depending on the size of inference data, job concurrency, complexity of the model, and compute instance capacity. |
| Throughput | Batch transform jobs can be done on a range of datasets, from petabytes of data to very small datasets. There is no need to resize larger datasets into small chunks of data. You can speed up batch transform jobs by using optimal values for parameters such as MaxPayloadInMB, MaxConcurrentTransforms, or BatchStrategy. The ideal value for Batch processing can increase throughput and optimize your resources because it helps complete a larger number of inferences in a certain amount of time at the expense of latency. To optimize model deployment for higher throughput, the general guideline is to increase the batch size until throughput decreases. |
| Scaling configuration complexity | SageMaker batch transform is used for offline inference that is not latency sensitive. |
| Traffic pattern | For offline inference, a batch transform job is scheduled or started using an event-based trigger. |
Serverless inference in SageMaker
SageMaker serverless inference allows you to deploy ML models for inference without having to configure or manage the underlying infrastructure. Based on the volume of inference requests your model receives, SageMaker serverless inference automatically provisions, scales, and turns off compute capacity. As a result, you pay for only the compute time to run your inference code and the amount of data processed, not for idle time. You can use SageMaker’s built-in algorithms and ML framework-serving containers to deploy your model to a serverless inference endpoint or choose to bring your own container. If traffic becomes predictable and stable, you can easily update from a serverless inference endpoint to a SageMaker real-time endpoint without the need to make changes to your container image. With serverless inference, you also benefit from other SageMaker features, including built-in metrics such as invocation count, faults, latency, host metrics, and errors in CloudWatch.
The following table provides guidance on evaluating SageMaker serverless inference based on the fitness functions.
| Fitness function | Description |
| Cost | With a pay-as-you-run model, serverless inference is a cost-effective option if you have infrequent or intermittent traffic patterns. You pay only for the duration for which the endpoint processes the request, and therefore can save costs if the traffic pattern is intermittent. |
| Inference latency | Serverless endpoints offer low inference latency (in the order of milliseconds to seconds), with the ability to scale instantly from tens to thousands of inferences within seconds based on the usage patterns, making it ideal for ML applications with intermittent or unpredictable traffic. Because serverless endpoints provision compute resources on demand, your endpoint may experience a few extra seconds of latency (cold start) for the first invocation after an idle period. The cold start time depends on your model size, how long it takes to download your model, and the startup time of your container. |
| Throughput | When configuring your serverless endpoint, you can specify the memory size and maximum number of concurrent invocations. SageMaker serverless inference auto-assigns compute resources proportional to the memory you select. If you choose a larger memory size, your container has access to more vCPUs. As a general rule, the memory size should be at least as large as your model size. The memory sizes you can choose are 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB, and 6144 MB. Regardless of the memory size you choose, serverless endpoints have 5 GB of ephemeral disk storage available. |
| Scaling configuration complexity | Serverless endpoints automatically launch compute resources and scale them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies. This takes away the undifferentiated heavy lifting of selecting and managing servers. |
| Traffic pattern | Serverless inference is ideal for workloads with infrequent or intermittent traffic patterns. |
Model hosting design patterns in SageMaker
SageMaker inference endpoints use Docker containers for hosting ML models. Containers allow you package software into standardized units that run consistently on any platform that supports Docker. This ensures portability across platforms, immutable infrastructure deployments, and easier change management and CI/CD implementations. SageMaker provides pre-built managed containers for popular frameworks such as Apache MXNet, TensorFlow, PyTorch, Sklearn, and Hugging Face. For a full list of available SageMaker container images, refer to Available Deep Learning Containers Images. In the case that SageMaker doesn’t have a supported container, you can also build your own container (BYOC) and push your own custom image, installing the dependencies that are necessary for your model.
To deploy a model on SageMaker, you need a container (SageMaker managed framework containers or BYOC) and a compute instance to host the container. SageMaker supports multiple advanced options for common ML model hosting design patterns where models can be hosted on a single container or co-hosted on a shared container.
A real-time ML application may use a single model or multiple models to serve a single prediction request. The following diagram shows various inference scenarios for an ML application.

Let’s explore a suitable SageMaker hosting option for each of the preceding inference scenarios. You can refer to the fitness functions to assess if it’s the right option for the given use case.
Hosting a single-model based ML application
There are several options to host single-model based ML applications using SageMaker hosting services depending on the deployment scenario.
Single-model endpoint
SageMaker single-model endpoints allow you to host one model on a container hosted on dedicated instances for low latency and high throughput. These endpoints are fully managed and support auto scaling. You can configure the single-model endpoint as a provisioned endpoint where you pass in endpoint infrastructure configuration such as the instance type and count, or a serverless endpoint where SageMaker automatically launches compute resources and scales them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies. Serverless endpoints are for applications with intermittent or unpredictable traffic.
The following diagram shows single-model endpoint inference scenarios.

The following table provides guidance on evaluating fitness functions for a provisioned single-model endpoint. For serverless endpoint fitness function evaluations, refer to the serverless endpoint section in this post.
| Fitness function | Description |
| Cost | You are charged for usage of the instance type you choose. Because the endpoint is always running and available, costs can quickly add up. Choosing the right instance for your model helps ensure you have the most performant instance at the lowest cost for your models. Auto scaling is recommended to dynamically adjust the capacity depending on traffic to maintain steady and predictable performance at the possible lowest cost. |
| Inference latency | A single-model endpoint provides real-time, interactive, synchronous inference with millisecond latency requirements. |
| Throughput | Throughput can be impacted by various factors, such as model input size, batch size, endpoint instance type, and so on. It is recommended to review CloudWatch metrics for input requests and resource utilization, and select the appropriate instance type to achieve optimal throughput. SageMaker provides features to manage resources and optimize inference performance when deploying ML models. You can optimize model performance using Neo, or use Inf1 instances for better throughput of your SageMaker hosted models using a GPU instance for your endpoint. |
| Scaling configuration complexity | Auto scaling is supported out of the box. SageMaker recommends choosing an appropriate scaling configuration by performing load tests. |
| Traffic pattern | A single-model endpoint is ideal for workloads with predictable traffic patterns. |
Co-hosting multiple models
When you’re dealing with a large number of models, deploying each one on an individual endpoint with a dedicated container and instance can result in a significant increase in cost. Additionally, it also becomes difficult to manage so many models in production, specifically when you don’t need to invoke all the models at the same time but still need them to be available at all times. Co-hosting multiple models on the same underlying compute resources makes it easy to manage ML deployments at scale and lowers your hosting costs through increased usage of the endpoint and its underlying compute resources. SageMaker supports advanced model co-hosting options such as multi-model endpoint (MME) for homogenous models and multi-container endpoint (MCE) for heterogenous models. Homogeneous models use the same ML framework on a shared service container, whereas heterogenous models allow you to deploy multiple serving containers that use different models or frameworks on a single endpoint.
The following diagram shows model co-hosting options using SageMaker.

SageMaker multi-model endpoints
SageMaker MMEs allow you to host multiple models using a shared serving container on a single endpoint. This is a scalable and cost-effective solution to deploy a large number of models that cater to the same use case, framework, or inference logic. MMEs can dynamically serve requests based on the model invoked by the caller. It also reduces deployment overhead because SageMaker manages loading models in memory and scaling them based on the traffic patterns to them. This feature is ideal when you have a large number of similar models that you can serve through a shared serving container and don’t need to access all the models at the same time. Multi-model endpoints also enable time-sharing of memory resources across your models. This works best when the models are fairly similar in size and invocation latency, allowing MMEs to effectively use the instances across all models. SageMaker MMEs support hosting both CPU and GPU backed models. By using GPU backed models, you can lower your model deployment costs through increased usage of the endpoint and its underlying accelerated compute instances. For a real world use case of MMEs, refer to How to scale machine learning inference for multi-tenant SaaS use cases.
The following table provides guidance on evaluating the fitness functions for MMEs.
| Fitness function | Description |
| Cost | MMEs enable using a shared serving container to host thousands of models on a single endpoint. This reduces hosting costs significantly by improving endpoint utilization compared with using single-model endpoints. For example, if you have 10 models to deploy using an ml.c5.large instance, based on SageMaker pricing, the cost of having 10 single-model persistent endpoints is: 10 * $0.102 = $1.02 per hour. Whereas with one MME hosting the 10 models, we achieve 10 times cost savings: 1 * $0.102 = $0.102 per hour. |
| Inference latency | By default, MMEs cache frequently used models in memory and on disk to provide low-latency inference. The cached models are unloaded or deleted from disk only when a container runs out of memory or disk space to accommodate a newly targeted model. MMEs allow lazy loading of models, which means models are loaded into memory when invoked for the first time. This optimizes memory utilization; however, it causes response time spikes on first load, resulting in a cold start problem. Therefore, MMEs are also well suited to scenarios that can tolerate occasional cold-start-related latency penalties that occur when invoking infrequently used models. To meet the latency and throughput goals of ML applications, GPU instances are preferred over CPU instances (given the computational power GPUs offer). With MME support for GPU, you can deploy thousands of deep learning models behind one SageMaker endpoint. MMEs can run multiple models on a GPU core, share GPU instances behind an endpoint across multiple models, and dynamically load and unload models based on the incoming traffic. With this, you can significantly save cost and achieve the best price performance. If your use case demands significantly higher transactions per second (TPS) or latency requirements, we recommend hosting the models on dedicated endpoints. |
| Throughput | An ideal value of MME inference throughput depends on factors such as model, payload size, and endpoint instance type. A higher amount of instance memory enables you to have more models loaded and ready to serve inference requests. You don’t need to waste time loading the model. A higher amount of vCPUs enables you to invoke more unique models concurrently. MMEs dynamically load and unload the model to and from instance memory, which may impact I/O performance. SageMaker MMEs with GPU work using NVIDIA Triton Inference Server, which is an open-source inference serving software that simplifies the inference serving process and provides high inference performance. SageMaker loads the model to the NVIDIA Triton container’s memory on a GPU accelerated instance and serves the inference request. The GPU core is shared by all the models in an instance. If the model is already loaded in the container memory, the subsequent requests are served faster because SageMaker doesn’t need to download and load it again. A proper performance testing and analysis is recommended in successful production deployments. SageMaker provides CloudWatch metrics for multi-model endpoints so you can determine the endpoint usage and the cache hit rate to help optimize your endpoint. |
| Scaling configuration complexity | SageMaker multi-model endpoints fully support auto scaling, which manages replicas of models to ensure models scale based on traffic patterns. However, a proper load testing is recommended to determine the optimal size of the instances for auto scaling the endpoint. Right-sizing the MME fleet is important to avoid too many models unloading. Loading hundreds of models on a few larger instances may lead to throttling in some cases, and using more and smaller instances could be preferred. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity. Set up your endpoint-level scaling policy with either custom parameters or invocations per minute (recommended) to add more instances to the endpoint fleet. The invocation rates used to trigger an auto scale event are based on the aggregate set of predictions across the full set of models served by the endpoint. |
| Traffic pattern | MMEs are ideal when you have a large number of similar sized models that you can serve through a shared serving container and don’t need to access all the models at the same time. |
SageMaker multi-container endpoints
SageMaker MCEs support deploying up to 15 containers that use different models or frameworks on a single endpoint, and invoking them independently or in sequence for low-latency inference and cost savings. The models can be completely heterogenous, with their own independent serving stack. Securely hosting multiple models from different frameworks on a single instance could save you up to 90% in cost.
The MCE invocation patterns are as follows:
- Inference pipelines – Containers in an MME can be invoked in a linear sequence, also known as a serial inference pipeline. They are typically used to separate preprocessing, model inference, and postprocessing into independent containers. The output from the current container is passed as input to the next. They are represented as a single pipeline model in SageMaker. An inference pipeline can be deployed as an MME, where one of the containers in the pipeline can dynamically serve requests based on the model being invoked.
- Direct invocation – With direct invocation, a request can be sent to a specific inference container hosted on an MCE.
The following table provides guidance on evaluating the fitness functions for MCEs.
| Fitness function | Description |
| Cost | MCEs enable you to run up to 15 different ML containers on a single endpoint and invoke them independently, thereby saving costs. This option is ideal when you have multiple models running on different serving stacks with similar resource needs, and when individual models don’t have sufficient traffic to utilize the full capacity of the endpoint instances. MCEs are therefore more cost effective than a single-model endpoint. MCEs offer synchronous inference response, which means the endpoint is always available and you pay for the uptime of the instance. Cost can add up depending on the number and type of instances. |
| Inference latency | MCEs are ideal for running ML apps with different ML frameworks and algorithms for each model that are accessed infrequently but still require low-latency inference. The models are always available for low-latency inference and there is no cold start problem. |
| Throughput | MCEs are limited to up to 15 containers on a multi-container endpoint, and GPU inference is not supported due to resource contention. For multi-container endpoints using direct invocation mode, SageMaker not only provides instance-level metrics as it does with other common endpoints, but also supports per-container metrics. As a best practice, review CloudWatch metrics for input requests and resource utilization, and the select appropriate instance type to achieve optimal throughput. |
| Scaling configuration complexity | MCEs support auto scaling. However, in order to configure automatic scaling, it is recommended that the model in each container exhibits similar CPU utilization and latency on each inference request. This is recommended because if traffic to the multi-container endpoint shifts from a low CPU utilization model to a high CPU utilization model, but the overall call volume remains the same, the endpoint doesn’t scale out, and there may not be enough instances to handle all the requests to the high CPU utilization model. |
| Traffic pattern | MCEs are ideal for workloads with continual or regular traffic patterns, for hosting models across different frameworks (such as TensorFlow, PyTorch, or Sklearn) that may not have sufficient traffic to saturate the full capacity of an endpoint instance. |
Hosting a multi-model based ML application
Many business applications need to use multiple ML models to serve a single prediction request to their consumers. For example, a retail company that wants to provide recommendations to its users. The ML application in this use case may want to use different custom models for recommending different categories of products. If the company wants to add personalization to the recommendations by using individual user information, the number of custom models further increases. Hosting each custom model on a distinct compute instance is not only cost prohibitive, but also leads to underutilization of the hosting resources if not all models are frequently used. SageMaker offers efficient hosting options for multi-model based ML applications.
The following diagram shows multi-model hosting options for a single endpoint using SageMaker.

Serial inference pipeline
An inference pipeline is a SageMaker model that is composed of a linear sequence of 2–15 containers that process requests for inferences on data. You use an inference pipeline to define and deploy any combination of pretrained SageMaker built-in algorithms and your own custom algorithms packaged in Docker containers. You can use an inference pipeline to combine preprocessing, predictions, and postprocessing data science tasks. The output from one container is passed as input to the next. When defining the containers for a pipeline model, you also specify the order in which the containers are run. They are represented as a single pipeline model in SageMaker. The inference pipeline can be deployed as an MME, where one of the containers in the pipeline can dynamically serve requests based on the model being invoked. You can also run a batch transform job with an inference pipeline. Inference pipelines are fully managed.
The following table provides guidance on evaluating the fitness functions for ML model hosting using a serial inference pipeline.
| Fitness function | Description |
| Cost | Serial inference pipeline enables you to run up to 15 different ML containers on a single endpoint, leading to cost effectiveness of hosting the inference containers. There are no additional costs for using this feature. You pay only for the instances running on an endpoint. Cost can add up depending on the number and type of instances. |
| Inference latency | When an ML application is deployed as an inference pipeline, the data between different models doesn’t leave the container space. Feature processing and inferences run with low latency because the containers are co-located on the same EC2 instances. |
| Throughput | Within an inference pipeline model, SageMaker handles invocations as a sequence of HTTP requests. The first container in the pipeline handles the initial request, then the intermediate response is sent as a request to the second container, and so on, for each container in the pipeline. SageMaker returns the final response to the client. Throughput is subjective to factors such as model, model input size, batch size, and endpoint instance type. As a best practice, review CloudWatch metrics for input requests and resource utilization, and select the appropriate instance type to achieve optimal throughput. |
| Scaling configuration complexity | Serial inference pipelines support auto scaling. However, in order to configure automatic scaling, it is recommended that the model in each container exhibits similar CPU utilization and latency on each inference request. This is recommended because if traffic to the multi-container endpoint shifts from a low CPU utilization model to a high CPU utilization model, but the overall call volume remains the same, the endpoint doesn’t scale out and there may not be enough instances to handle all the requests to the high CPU utilization model. |
Traffic pattern | Serial inference pipelines are ideal for predictable traffic patterns with models that run sequentially on the same endpoint. |
Deploying model ensembles (Triton DAG):
SageMaker offers integration with NVIDIA Triton Inference Server through Triton Inference Server Containers. These containers include NVIDIA Triton Inference Server, support for common ML frameworks, and useful environment variables that let you optimize performance on SageMaker. With NVIDIA Triton container images, you can easily serve ML models and benefit from the performance optimizations, dynamic batching, and multi-framework support provided by NVIDIA Triton. Triton helps maximize the utilization of GPU and CPU, further lowering the cost of inference.
In business use cases where ML applications use several models to serve a prediction request, if each model uses a different framework or is hosted on a separate instance, it may lead to increased workload and cost as well as an increase in overall latency. SageMaker NVIDIA Triton Inference Server supports deployment of models from all major frameworks, such as TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch TorchScript, TensorRT, and Python/C++ model formats and more. Triton model ensemble represents a pipeline of one or more models or preprocessing and postprocessing logic, and the connection of input and output tensors between them. A single inference request to an ensemble triggers the run of the entire pipeline. Triton also has multiple built-in scheduling and batching algorithms that combine individual inference requests to improve inference throughput. These scheduling and batching decisions are transparent to the client requesting inference. The models can be run on CPUs or GPUs for maximum flexibility and to support heterogeneous computing requirements.
Hosting multiple GPU backed models on multi-model endpoints is supported through the SageMaker Triton Inference Server. The NVIDIA Triton Inference Server has been extended to implement an MME API contract, to integrate with MMEs. You can use the NVIDIA Triton Inference Server, which creates a model repository configuration for different framework backends, to deploy an MME with auto scaling. This feature allows you to scale hundreds of hyper-personalized models that are fine-tuned to cater to unique end-user experiences in AI applications. You can also use this feature to achieve needful price performance for your inference application using fractional GPUs. To learn more, refer to Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints.
The following table provides guidance on evaluating the fitness functions for ML model hosting using MMEs with GPU support on Triton inference containers. For single-model endpoints and serverless endpoint fitness function evaluations, refer to the earlier sections in this post.
| Fitness function | Description |
| Cost | SageMaker MMEs with GPU support using Triton Inference Server provide a scalable and cost-effective way to deploy a large number of deep learning models behind one SageMaker endpoint. With MMEs, multiple models share the GPU instance behind an endpoint. This enables you to break the linearly increasing cost of hosting multiple models and reuse infrastructure across all the models. You pay for the uptime of the instance. |
| Inference latency | SageMaker with Triton Inference Server is purpose-built to maximize throughput and hardware utilization with ultra-low (single-digit milliseconds) inference latency. It has a wide range of supported ML frameworks (including TensorFlow, PyTorch, ONNX, XGBoost, and NVIDIA TensorRT) and infrastructure backends, including NVIDIA GPUs, CPUs, and AWS Inferentia. With MME support for GPU using SageMaker Triton Inference Server, you can deploy thousands of deep learning models behind one SageMaker endpoint. SageMaker loads the model to the NVIDIA Triton container’s memory on a GPU accelerated instance and serves the inference request. The GPU core is shared by all the models in an instance. If the model is already loaded in the container memory, the subsequent requests are served faster because SageMaker doesn’t need to download and load it again. |
| Throughput | MMEs offer capabilities for running multiple deep learning or ML models on the GPU, at the same time, with Triton Inference Server. This allows you easily use the NVIDIA Triton multi-framework, high-performance inference serving with the SageMaker fully managed model deployment. Triton supports all NVIDIA GPU-, x86-, Arm® CPU-, and AWS Inferentia-based inferencing. It offers dynamic batching, concurrent runs, optimal model configuration, model ensemble, and streaming audio and video inputs to maximize throughput and utilization. Other factors such as network and payload size may play a minimal role in the overhead associated with the inference. |
| Scaling configuration complexity | MMEs can scale horizontally using an auto scaling policy, and provision additional GPU compute instances based on metrics such as With Triton inference server, you can easily build a custom container that includes your model with Triton and bring it to SageMaker. SageMaker Inference will handle the requests and automatically scale the container as usage increases, making model deployment with Triton on AWS easier. |
| Traffic pattern | MMEs are ideal for predictable traffic patterns with models run as DAGs on the same endpoint. SageMaker takes care of traffic shaping to the MME endpoint and maintains optimal model copies on GPU instances for best price performance. It continues to route traffic to the instance where the model is loaded. If the instance resources reach capacity due to high utilization, SageMaker unloads the least-used models from the container to free up resources to load more frequently used models. |
Best practices
Consider the following best practices:
- High cohesion and low coupling between models – Host the models in the same container that has high cohesion (drives single-business functionality) and encapsulate them together for ease of upgrade and manageability. At the same time, decouple those models from each other (host them in different container) so that you can easily upgrade one model without impacting other models. Host multiple models that use different containers behind one endpoint and invoke then independently or add model preprocessing and postprocessing logic as a serial inference pipeline.
- Inference latency – Group the models that are single-business functionality driven and host them in a single container to minimize the number of hops and therefore minimize the overall latency. There are other caveats, like if the grouped models use multiple frameworks; you might also choose to host in multiple containers but run on the same host to reduce latency and minimize cost.
- Logically group ML models with high cohesion – The logical group may consist of models that are homogeneous (for example, all XGBoost models) or heterogeneous (for example, a few XGBoost and a few BERT). It may consist of models that are shared across multiple business functionalities or may be specific to fulfilling only one business functionality.
- Shared models – If the logical group consists of shared models, the ease of upgrading the models and latency will play a major role in architecting the SageMaker endpoints. For example, if latency is a priority, it’s better to place all the models in a single container behind a single SageMaker endpoint to avoid multiple hops. The downside is that if any of the models need to be upgraded, it will result in upgrading all the relevant SageMaker endpoints hosting this model.
- Non-shared models – If the logical group consists of only business feature specific models and is not shared with other groups, the packaging complexity and latency dimensions will become key to achieve. It’s advisable to host these models in a single container behind a single SageMaker endpoint.
- Efficient use of hardware (CPU, GPU) – Group CPU-based models together and host them on the same host so that you can efficiently use the CPU. Similarly, group GPU-based models together so that you can efficiently use and scale them. There are hybrid workloads that require both CPU and GPU on the same host. Hosting the CPU-only and GPU-only models on the same host should be driven by high cohesion and application latency requirements. Additionally, cost, ability to scale, and blast radius on impact in case of failure are the key dimensions to look into.
- Fitness functions – Use fitness functions as a guideline for selecting an ML hosting option.
Conclusion
When it comes to ML hosting, there is no one-size-fits-all approach. ML practitioners need to choose the right design pattern to address their ML hosting challenges. Evaluating the fitness functions provides prescriptive guidance on selecting the right ML hosting option.
For more details on each of the hosting options, refer to the following posts in this series:
- Part 2: Getting started with deploying real-time models on Amazon SageMaker
- Part 3: Run and optimize multi-model inference with Amazon SageMaker multi-model endpoints
- Part 4: Design patterns for serial inference on Amazon SageMaker
- Part 5: Cost efficient ML inference with multi-framework models on Amazon SageMaker
- Part 6: Best practices in testing and updating models on SageMaker
- Part 7: Run ensemble ML models on Amazon SageMaker
About the authors
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Deepali Rajale is AI/ML Specialist Technical Account Manager at Amazon Web Services. She works with enterprise customers providing technical guidance on implementing machine learning solutions with best practices. In her spare time, she enjoys hiking, movies and hanging out with family and friends.
Deepali Rajale is AI/ML Specialist Technical Account Manager at Amazon Web Services. She works with enterprise customers providing technical guidance on implementing machine learning solutions with best practices. In her spare time, she enjoys hiking, movies and hanging out with family and friends.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.