
Over the last year, there’s been a lot of change in the commercial image and video asset industry: New generative AI applications let users create their own still and live images based on prompts, and traditional stock-media asset providers are offering customers richer search experiences that have a deep understanding of the image/live image content and that expose it with a natural language interface.
To continually push the state of the art, these organizations must use data to evolve their products rapidly, for example to:
Optimize still and live image generation models
Identify inappropriate content, such as violence or nudity
Analyze behavior to identify improvements to the user experience
Recommend similar images or prompts based on previous activity
Enhance static asset search capabilities
To do this, they need unstructured images, live images, and audio data, combined with structured user-experience data and metadata about the assets they are interacting with, whether they’re static or AI-generated.
In this post, we outline a solution based on our real-life engagements with leaders in the industry who operate at the scale of petabytes per day. This solution delivers several benefits:
Minimizes costs by avoiding duplicate data and storage, while facilitating AI model proximity to data for efficient inference
Simplifies development and delivery by combining diverse data types in a unified data architecture
Optimizes use of limited engineering resources through an integrated, scalable serverless platform that combines BigQuery and Google Cloud Storage
Allows users to augment and transform their data according to the needs of their business
Enables companies to develop lightweight, powerful analyses quickly and securely, to activate customer data and quickly iterate on the output of models
The challenge of unstructured data
Generated (unstructured) image data, the (semi-structured) prompts that made them, as well as user behavior data (structured, in tables) for things like session time and frequency, are all rich in potential insights. For example, knowing which types of prompts lead to successfully generating an image — and those that don’t — provides insights into product and model development opportunities.
But combining these different data types often requires advanced analytics to interpret them meaningfully. Technologies like natural language processing and computer vision are at the forefront of extracting these kinds of valuable insights. However, integrating unstructured data within an existing analytics framework of structured data, for example user behavior data in database tables, is not without its hurdles. Common challenges include:
Data security standards: Adhering to stringent data security standards to protect sensitive information is crucial. These standards include applying data masking to sensitive PII data and following least-privilege security principles for data access.
Data type silos: Unstructured data is often stored separately from structured data, preventing effective analysis across data types, for example, filtering media assets (unstructured) based on user profiles (structured), as they reside in separate systems.
High-performance, scalable cloud computing resources: The need for powerful computing resources is imperative to manage and analyze large unstructured datasets effectively due to the data’s complexity, volume, and the potential need for real-time results. In addition, high performance networking allows for low-latency data transfers to enable the transfer of unstructured data between storage (Cloud Storage) and analytical layers (BigQuery, Vertex, etc.)
Maintaining data integrity across layers: As insights are extracted from unstructured data, preserving the original source of truth and ensuring consistency across intermediate (interstitial) layers is crucial for reliable, iterative analysis.
Streamlining data integration with Cloud Storage and BigQuery
To overcome the challenges of working with unstructured data, Cloud Storage and BigQuery can be used to centralize data, using BigQuery object tables to enable consistent data access to varied sources through one analytical platform. Below is an example of a simple yet effective architecture that harnesses BigQuery for both metadata generation and enhancement. This approach uses BigQuery’s built-in generative AI functions, coupled with remote User Defined Functions (UDFs) that interface with Vertex AI APIs. The integration elevates the process of data enrichment and analysis, and offers a more streamlined and efficient workflow.
The power of BigQuery object tables
In the example below, we focus on a static image use case, however, this same technique could be used for images created using generative AI. The true potential of this architecture lies in its versatility. The use of object tables in BigQuery means this pattern can be adapted to any form of unstructured data, for example images, audio, documents, opening up a world of possibilities for data science and analysis. This flexibility ensures the architecture can evolve with the changing needs and types of data, helping the solution withstand the test of time in the dynamic field of image curation and generation.
This architecture shows the integration of structured and unstructured data, utilizing the strengths of both to enhance platform capabilities. BigQuery serves as a central hub, amalgamating user data information (for example: user demographics, images viewed and used, session duration, session frequency), image metadata, and queries. Concurrently, external AI APIs augment this dataset with insights about the content of the images, for example describing what is happening in a scene (e.g. “a photographic image of a dog playing with a ball on grass”) .
This convergence of data facilitates the training of sophisticated image-generation models, tailored to meet the specific requirements of the platform’s users. It also unlocks advanced search and image-curation functionalities, enabling users to navigate through an extensive collection of images. The project’s ability to provide access to external systems and empower data augmentation within BigQuery helps to centralize analytic workloads. This not only streamlines data analysis but also fosters informed decision-making.
Solution overview
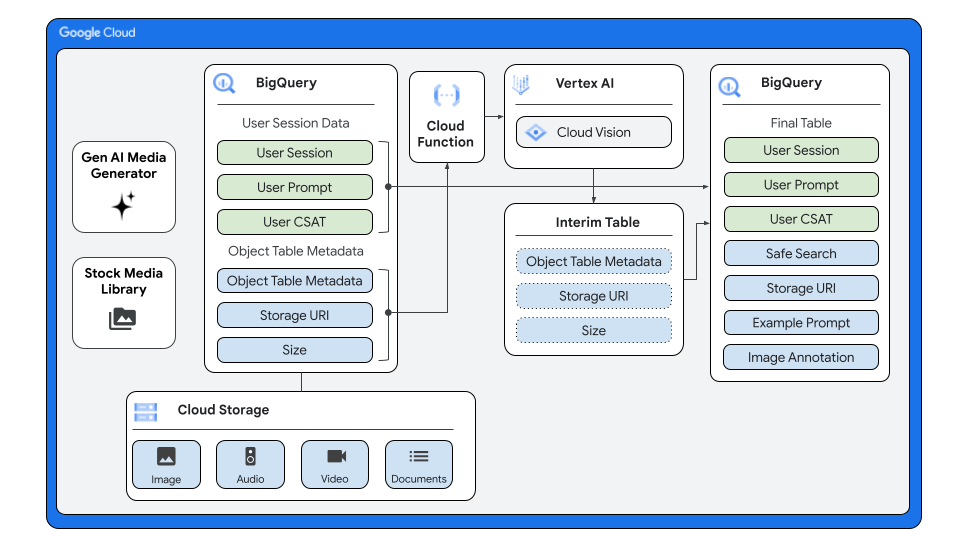
The goal of the solution is to create a way to interact with unstructured data through BigQuery. Using BigQuery object tables to analyze unstructured data in Cloud Storage, you can perform analyses using generative AI models via remote functions, cloud APIs via Vertex AI, or perform inference by using BigQuery ML, and then join the results of these operations with the rest of your structured data in BigQuery.
Step 1. Creating an example dataset
Prerequisites
Data: Multiple image repositories on third-party sites like Kaggle and Hugging Face
Project setup: To get started we need to activating essential project APIs:
gcloud services enable cloudfunctions.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
gcloud services enable vision.googleapis.com
Step 2. Create the object table
The object table provides the reference to the non-structured data (e.g., audio, live images and images).
To do this, we create the BigQuery BigLake remote connection, building a bridge between BigQuery and Cloud Storage:
Command for creation: bq mk –connection –location=us-central1 –project_id=bq-object-tables-demo –connection_type=CLOUD_RESOURCE biglake-connection
To show the details of this new creation, use: bq show –connection bq-object-tables-demo.us-central1.biglake-connection
Then, give your BQ service account the correct permissions to access your Cloud Storage bucket.
Your serviceAccountId typically looks like this: {“serviceAccountId”: “bqcx-012345678910-abcd@gcp-sa-bigquery-condel.iam.gserviceaccount.com”}`. And it needs the object viewer permission. This can be achieved by:
- code_block
- <ListValue: [StructValue([(‘code’, ‘gsutil iam ch \ serviceAccount:bqcx-012345678910-abcd@gcp-sa-bigquery-condel.iam.gserviceaccount.com:objectViewer gs://bq-object-tables-demo-data’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc6999d30>)])]>
Make your object table in BigQuery in an existing dataset, or create a dataset for your object table.
Create the dataset with: bq mk -d –data_location=us-central1 bq_object_table_demo-dataset
This is a sample query you can use to create the object table
- code_block
- <ListValue: [StructValue([(‘code’, ‘CREATE OR REPLACE EXTERNAL TABLE `bq-object-tables.bq_ot_dataset.bq_object_tables_external_table` rnWITH CONNECTION `bq-object-tables.us-east1.biglake-connection` OPTIONS ( object_metadata=”DIRECTORY”, uris = [‘gs://bq-object-tables-demo-data/*’ ], max_staleness=INTERVAL 30 MINUTE, metadata_cache_mode=”AUTOMATIC”);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc69994c0>)])]>
The max_staleness option lets you manage the trade-off between data freshness and performance by specifying a tolerable level of staleness for the materialized view; this can help improve query response times and reduce costs. By setting an appropriate value, you can achieve consistently high performance while keeping costs under control, even when working with large, frequently changing datasets.
Create metadata using Native BQ Functionality
These steps can all be automated into a Directed Acyclic Graph (DAG) for use in an orchestration tool such as Cloud Composer.
Step 3. Reference the model from a native generative AI BQML function
First create the link back to the model in your BQ dataset like this:
- code_block
- <ListValue: [StructValue([(‘code’, “# Create ModelrnCREATE OR REPLACE MODELrn`bq-object-tables.bq_ot_dataset.myvisionmodel`rnREMOTE WITH CONNECTION `bq-object-tables.us-east1.biglake-connection`rnOPTIONS (remote_service_type =’cloud_ai_vision_v1′);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc6999730>)])]>
Annotate image
This code parses the images, extracts their contents and outputs a JSON array of words that describe the image and the model’s confidence that the description is correct. This function will then put the description into a table.
- code_block
- <ListValue: [StructValue([(‘code’, “# Annotate imagernSELECT *rnFROM ML.ANNOTATE_IMAGE(rn MODEL `mydataset.myvisionmodel`,rn TABLE `mydataset.mytable`,rn STRUCT([‘label_detection’] AS vision_features)rn);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc6999b50>)])]>
Step 4. Create a UDF in BigQuery
You can create a Cloud function using this basic code.
If you’re unsure how to create a cloud function, please see the docs for how to create a cloud function UDF.
Then, to deploy the Cloud Function, follow these steps:
4.1. Deploy your Cloud Function
You may need to enable Cloud Functions API.
You may need to enable Cloud Build APIs.
4.2. Grant the BigQuery connection service account access to the Cloud Function
One way you can find the service account is by using the BigQuery cli ‘show’ command
4.3. Reference the functions in BigQuery
Create a BigQuery remote function to reference the Cloud Function UDF
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE FUNCTION `mydataset.vision_safe_search`(signed_url_ STRING) RETURNS JSONrnREMOTE WITH CONNECTION `us.gcs-connection`rnOPTIONS(endpoint=’https://region-myproject.cloudfunctions.net/vision_safe_search’,rnmax_batching_rows = 1);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc81b7520>)])]>
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE FUNCTION `mydataset.vision_annotation`(signed_url_ STRING) RETURNS JSONrnREMOTE WITH CONNECTION `us.gcs-connection`rnOPTIONS(endpoint=’https://region-myproject.cloudfunctions.net/vision_annotation’,rnmax_batching_rows = 1);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc81b78b0>)])]>
Step 5. Use the function in a query
- code_block
- <ListValue: [StructValue([(‘code’, ‘CREATE TABLE `mydataset.mid_processing` ASrnSELECT uri,mydataset.vision_safe_search(signed_url) as safe_search, mydataset.vision_annotation(signed_url) as annotationrnFROM EXTERNAL_OBJECT_TRANSFORM(rnTABLE `mydataset.imageall`,rn[“SIGNED_URL”]);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eefc81b7100>)])]>
Tap into unstructured data with BigQuery object tables and AI
This architecture demonstrates the power of streamlining data integration for centralized analyses through BigQuery. Although we reference image data for this example, this methodology is highly flexible; using object tables we can reference any type of unstructured data in Cloud Storage buckets that could also refer to audio files that might reference a call center AI use case, for example, or live image files relevant to training a computer vision model.
By centralizing data in Cloud Storage and BigQuery and intelligently using object tables, you can efficiently manage both structured and unstructured data. For our image-based example, this unified approach provides a rich dataset that contains user IDs, original prompts, prompt categories, image safety ratings, and even additional ML-generated prompts.
The potential applications for these metadata sets are huge. Product teams could use them to build more robust image-generation models or create an advanced image-search system, providing highly relevant results aligned with users’ search terms and image descriptions.
Take the next step
You can get started today using this framework. For additional help, ask your Google Cloud account manager to reach out to the Built with BigQuery team.
The Built with BigQuery team helps Independent Software Vendors (ISVs) and data providers build innovative applications with Google Data Cloud. Participating companies can:
Accelerate product design and architecture through access to designated experts who can provide insight into key use cases, architectural patterns, and best practices
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption