Generative AI (GenAI) and large language models (LLMs), such as those available soon via Amazon Bedrock and Amazon Titan are transforming the way developers and enterprises are able to solve traditionally complex challenges related to natural language processing and understanding. Some of the benefits offered by LLMs include the ability to create more capable and compelling conversational AI experiences for customer service applications, and improving employee productivity through more intuitive and accurate responses.
For these use cases, however, it’s critical for the GenAI applications implementing the conversational experiences to meet two key criteria: limit the responses to company data, thereby mitigating model hallucinations (incorrect statements), and filter responses according to the end-user content access permissions.
To restrict the GenAI application responses to company data only, we need to use a technique called Retrieval Augmented Generation (RAG). An application using the RAG approach retrieves information most relevant to the user’s request from the enterprise knowledge base or content, bundles it as context along with the user’s request as a prompt, and then sends it to the LLM to get a GenAI response. LLMs have limitations around the maximum word count for the input prompt, therefore choosing the right passages among thousands or millions of documents in the enterprise, has a direct impact on the LLM’s accuracy.
In designing effective RAG, content retrieval is a critical step to ensure the LLM receives the most relevant and concise context from enterprise content to generate accurate responses. This is where the highly accurate, machine learning (ML)-powered intelligent search in Amazon Kendra plays an important role. Amazon Kendra is a fully managed service that provides out-of-the-box semantic search capabilities for state-of-the-art ranking of documents and passages. You can use the high-accuracy search in Amazon Kendra to source the most relevant content and documents to maximize the quality of your RAG payload, yielding better LLM responses than using conventional or keyword-based search solutions. Amazon Kendra offers easy-to-use deep learning search models that are pre-trained on 14 domains and don’t require any ML expertise, so there’s no need to deal with word embeddings, document chunking, and other lower-level complexities typically required for RAG implementations. Amazon Kendra also comes with pre-built connectors to popular data sources such as Amazon Simple Storage Service (Amazon S3), SharePoint, Confluence, and websites, and supports common document formats such as HTML, Word, PowerPoint, PDF, Excel, and pure text files. To filter responses based on only those documents that the end-user permissions allow, Amazon Kendra offers connectors with access control list (ACL) support. Amazon Kendra also offers AWS Identity and Access Management (IAM) and AWS IAM Identity Center (successor to AWS Single Sign-On) integration for user-group information syncing with customer identity providers such as Okta and Azure AD.
In this post, we demonstrate how to implement a RAG workflow by combining the capabilities of Amazon Kendra with LLMs to create state-of-the-art GenAI applications providing conversational experiences over your enterprise content. After Amazon Bedrock launches, we will publish a follow-up post showing how to implement similar GenAI applications using Amazon Bedrock, so stay tuned.
Solution overview
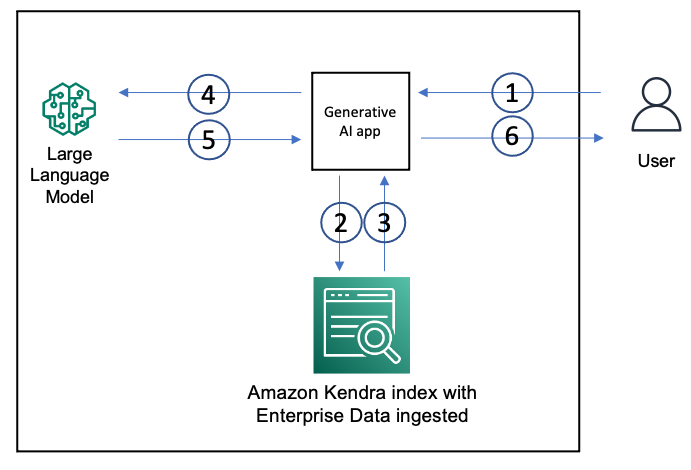
The following diagram shows the architecture of a GenAI application with a RAG approach.

We use an Amazon Kendra index to ingest enterprise unstructured data from data sources such as wiki pages, MS SharePoint sites, Atlassian Confluence, and document repositories such as Amazon S3. When a user interacts with the GenAI app, the flow is as follows:
- The user makes a request to the GenAI app.
- The app issues a search query to the Amazon Kendra index based on the user request.
- The index returns search results with excerpts of relevant documents from the ingested enterprise data.
- The app sends the user request and along with the data retrieved from the index as context in the LLM prompt.
- The LLM returns a succinct response to the user request based on the retrieved data.
- The response from the LLM is sent back to the user.
With this architecture, you can choose the most suitable LLM for your use case. LLM options include our partners Hugging Face, AI21 Labs, Cohere, and others hosted on an Amazon SageMaker endpoint, as well as models by companies like Anthropic and OpenAI. With Amazon Bedrock, you will be able to choose Amazon Titan, Amazon’s own LLM, or partner LLMs such as those from AI21 Labs and Anthropic with APIs securely without the need for your data to leave the AWS ecosystem. The additional benefits that Amazon Bedrock will offer include a serverless architecture, a single API to call the supported LLMs, and a managed service to streamline the developer workflow.
For the best results, a GenAI app needs to engineer the prompt based on the user request and the specific LLM being used. Conversational AI apps also need to manage the chat history and the context. GenAI app developers can use open-source frameworks such as LangChain that provide modules to integrate with the LLM of choice, and orchestration tools for activities such as chat history management and prompt engineering. We have provided the KendraIndexRetriever class, which implements a LangChain retriever interface, which applications can use in conjunction with other LangChain interfaces such as chains to retrieve data from an Amazon Kendra index. We have also provided a few sample applications in the GitHub repo. You can deploy this solution in your AWS account using the step-by-step guide in this post.
Prerequisites
For this tutorial, you’ll need a bash terminal with Python 3.9 or higher installed on Linux, Mac, or Windows Subsystem for Linux, and an AWS account. We also recommend using an AWS Cloud9 instance or an Amazon Elastic Compute Cloud (Amazon EC2) instance.
Implement a RAG workflow
To configure your RAG workflow, complete the following steps:
- Use the provided AWS CloudFormation template to create a new Amazon Kendra index.
This template includes sample data containing AWS online documentation for Amazon Kendra, Amazon Lex, and Amazon SageMaker. Alternately, if you have an Amazon Kendra index and have indexed your own dataset, you can use that. Launching the stack requires about 30 minutes followed by about 15 minutes to synchronize it and ingest the data in the index. Therefore, wait for about 45 minutes after launching the stack. Note the index ID and AWS Region on the stack’s Outputs tab.
- For an improved GenAI experience, we recommend requesting an Amazon Kendra service quota increase for maximum
DocumentExcerptsize, so that Amazon Kendra provides larger document excerpts to improve semantic context for the LLM. - Install the AWS SDK for Python on the command line interface of your choice.
- If you want to use the sample web apps built using Streamlit, you first need to install Streamlit. This step is optional if you want to only run the command line versions of the sample applications.
- Install LangChain.
- The sample applications used in this tutorial require you to have access to one or more LLMs from Flan-T5-XL, Flan-T5-XXL, Anthropic Claud-V1, and OpenAI-text-davinci-003.
- If you want to use Flan-T5-XL or Flan-T5-XXL, deploy them to an endpoint for inference using Amazon SageMaker Studio Jumpstart.

- If you want to work with Anthropic Claud-V1 or OpenAI-da-vinci-003, acquire the API keys for your LLMs of your interest from https://www.anthropic.com/ and https://openai.com/, respectively.
- If you want to use Flan-T5-XL or Flan-T5-XXL, deploy them to an endpoint for inference using Amazon SageMaker Studio Jumpstart.
- Follow the instructions in the GitHub repo to install the
KendraIndexRetrieverinterface and sample applications. - Before you run the sample applications, you need to set environment variables with the Amazon Kendra index details and API keys of your preferred LLM or the SageMaker endpoints of your deployments for Flan-T5-XL or Flan-T5-XXL. The following is a sample script to set the environment variables:
- In a command line window, change to the
samplessubdirectory of where you have cloned the GitHub repository. You can run the command line apps from the command line aspython <sample-file-name.py>. You can run the streamlit web app by changing the directory tosamplesand runningstreamlit run app.py <anthropic|flanxl|flanxxl|openai>. - Open the sample file
kendra_retriever_flan_xxl.pyin an editor of your choice.

Observe the statement result = run_chain(chain, "What's SageMaker?"). This is the user query (“What’s SageMaker?”) that’s being run through the chain that uses Flan-T-XXL as the LLM and Amazon Kendra as the retriever. When this file is run, you can observe the output as follows. The chain sent the user query to the Amazon Kendra index, retrieved the top three result excerpts, and sent them as the context in a prompt along with the query, to which the LLM responded with a succinct answer. It has also provided the sources, (the URLs to the documents used in generating the answer).
- Now let’s run the web app
app.pyasstreamlit run app.py flanxxl. For this specific run, we are using a Flan-T-XXL model as the LLM.
It opens a browser window with the web interface. You can enter a query, which in this case is “What is Amazon Lex?” As seen in the following screenshot, the application responds with an answer, and the Sources section provides the URLs to the documents from which the excerpts were retrieved from the Amazon Kendra index and sent to the LLM in the prompt as the context along with the query.

- Now let’s run
app.pyagain and get a feel of the conversational experience usingstreamlit run app.py anthropic. Here the underlying LLM used is Anthropic Claud-V1.
As you can see in the following video, the LLM provides a detailed answer to the user’s query based on the documents it retrieved from the Amazon Kendra index and then supports the answer with the URLs to the source documents that were used to generate the answer. Note that the subsequent queries don’t explicitly mention Amazon Kendra; however, the ConversationalRetrievalChain (a type of chain that’s part of the LangChain framework and provides an easy mechanism to develop conversational application-based information retrieved from retriever instances, used in this LangChain application), manages the chat history and the context to get an appropriate response.
Also note that in the following screenshot, Amazon Kendra finds the extractive answer to the query and shortlists the top documents with excerpts. Then the LLM is able to generate a more succinct answer based on these retrieved excerpts.

In the following sections, we explore two use cases for using Generative AI with Amazon Kendra.
Use case 1: Generative AI for financial service companies
Financial organizations create and store data across various data repositories, including financial reports, legal documents, and whitepapers. They must adhere to strict government regulations and oversight, which means employees need to find relevant, accurate, and trustworthy information quickly. Additionally, searching and aggregating insights across various data sources is cumbersome and error prone. With Generative AI on AWS, users can quickly generate answers from various data sources and types, synthesizing accurate answers at enterprise scale.
We chose a solution using Amazon Kendra and AI21 Lab’s Jurassic-2 Jumbo Instruct LLM. With Amazon Kendra, you can easily ingest data from multiple data sources such as Amazon S3, websites, and ServiceNow. Then Amazon Kendra uses AI21 Lab’s Jurassic-2 Jumbo Instruct LLM to carry out inference activities on enterprise data such as data summarization, report generation, and more. Amazon Kendra augments LLMs to provide accurate and verifiable information to the end-users, which reduces hallucination issues with LLMs. With the proposed solution, financial analysts can make faster decisions using accurate data to quickly build detailed and comprehensive portfolios. We plan to make this solution available as an open-source project in near future.
Example
Using the Kendra Chatbot solution, financial analysts and auditors can interact with their enterprise data (financial reports and agreements) to find reliable answers to audit-related questions. Kendra ChatBot provides answers along with source links and has the capability to summarize longer answers. The following screenshot shows an example conversation with Kendra ChatBot.

Architecture overview
The following diagram illustrates the solution architecture.

The workflow includes the following steps:
- Financial documents and agreements are stored on Amazon S3, and ingested to an Amazon Kendra index using the S3 data source connector.
- The LLM is hosted on a SageMaker endpoint.
- An Amazon Lex chatbot is used to interact with the user via the Amazon Lex web UI.
- The solution uses an AWS Lambda function with LangChain to orchestrate between Amazon Kendra, Amazon Lex, and the LLM.
- When users ask the Amazon Lex chatbot for answers from a financial document, Amazon Lex calls the LangChain orchestrator to fulfill the request.
- Based on the query, the LangChain orchestrator pulls the relevant financial records and paragraphs from Amazon Kendra.
- The LangChain orchestrator provides these relevant records to the LLM along with the query and relevant prompt to carry out the required activity.
- The LLM processes the request from the LangChain orchestrator and returns the result.
- The LangChain orchestrator gets the result from the LLM and sends it to the end-user through the Amazon Lex chatbot.
Use case 2: Generative AI for healthcare researchers and clinicians
Clinicians and researchers often analyze thousands of articles from medical journals or government health websites as part of their research. More importantly, they want trustworthy data sources they can use to validate and substantiate their findings. The process requires hours of intensive research, analysis, and data synthesis, lengthening the time to value and innovation. With Generative AI on AWS, you can connect to trusted data sources and run natural language queries to generate insights across these trusted data sources in seconds. You can also review the sources used to generate the response and validate its accuracy.
We chose a solution using Amazon Kendra and Flan-T5-XXL from Hugging Face. First, we use Amazon Kendra to identify text snippets from semantically relevant documents in the entire corpus. Then we use the power of an LLM such as Flan-T5-XXL to use the text snippets from Amazon Kendra as context and obtain a succinct natural language answer. In this approach, the Amazon Kendra index functions as the passage retriever component in the RAG mechanism. Lastly, we use Amazon Lex to power the front end, providing a seamless and responsive experience to end-users. We plan to make this solution available as an open-source project in the near future.
Example
The following screenshot is from a web UI built for the solution using the template available on GitHub. The text in pink are responses from the Amazon Kendra LLM system, and the text in blue are the user questions.

Architecture overview
The architecture and solution workflow for this solution are similar to that of use case 1.
Clean up
To save costs, delete all the resources you deployed as part of the tutorial. If you launched the CloudFormation stack, you can delete it via the AWS CloudFormation console. Similarly, you can delete any SageMaker endpoints you may have created via the SageMaker console.
Conclusion
Generative AI powered by large language models is changing how people acquire and apply insights from information. However, for enterprise use cases, the insights must be generated based on enterprise content to keep the answers in-domain and mitigate hallucinations, using the Retrieval Augmented Generation approach. In the RAG approach, the quality of the insights generated by the LLM depends on the semantic relevance of the retrieved information on which it is based, making it increasingly necessary to use solutions such as Amazon Kendra that provide high-accuracy semantic search results out of the box. With its comprehensive ecosystem of data source connectors, support for common file formats, and security, you can quickly start using Generative AI solutions for enterprise use cases with Amazon Kendra as the retrieval mechanism.
For more information on working with Generative AI on AWS, refer to Announcing New Tools for Building with Generative AI on AWS. You can start experimenting and building RAG proofs of concept (POCs) for your enterprise GenAI apps, using the method outlined in this blog. As mentioned earlier, once Amazon Bedrock is available, we will publish a follow up blog showing how you can build RAG using Amazon Bedrock.
About the authors
 Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
Abhinav Jawadekar is a Principal Solutions Architect focused on Amazon Kendra in the AI/ML language services team at AWS. Abhinav works with AWS customers and partners to help them build intelligent search solutions on AWS.
 Jean-Pierre Dodel is the Principal Product Manager for Amazon Kendra and leads key strategic product capabilities and roadmap prioritization. He brings extensive Enterprise Search and ML/AI experience to the team, with prior leading roles at Autonomy, HP, and search startups prior to joining Amazon 7 years ago.
Jean-Pierre Dodel is the Principal Product Manager for Amazon Kendra and leads key strategic product capabilities and roadmap prioritization. He brings extensive Enterprise Search and ML/AI experience to the team, with prior leading roles at Autonomy, HP, and search startups prior to joining Amazon 7 years ago.
 Mithil Shah is an ML/AI Specialist at AWS. Currently he helps public sector customers improve lives of citizens by building Machine Learning solutions on AWS.
Mithil Shah is an ML/AI Specialist at AWS. Currently he helps public sector customers improve lives of citizens by building Machine Learning solutions on AWS.
 Firaz Akmal is a Sr. Product Manager for Amazon Kendra at AWS. He is a customer advocate, helping customers understand their search and generative AI use-cases with Kendra on AWS. Outside of work Firaz enjoys spending time in the mountains of the PNW or experiencing the world through his daughter’s perspective.
Firaz Akmal is a Sr. Product Manager for Amazon Kendra at AWS. He is a customer advocate, helping customers understand their search and generative AI use-cases with Kendra on AWS. Outside of work Firaz enjoys spending time in the mountains of the PNW or experiencing the world through his daughter’s perspective.
 Abhishek Maligehalli Shivalingaiah is a Senior AI Services Solution Architect at AWS with focus on Amazon Kendra. He is passionate about building applications using Amazon Kendra ,Generative AI and NLP. He has around 10 years of experience in building Data & AI solutions to create value for customers and enterprises. He has built a (personal) chatbot for fun to answers questions about his career and professional journey. Outside of work he enjoys making portraits of family & friends, and loves creating artworks.
Abhishek Maligehalli Shivalingaiah is a Senior AI Services Solution Architect at AWS with focus on Amazon Kendra. He is passionate about building applications using Amazon Kendra ,Generative AI and NLP. He has around 10 years of experience in building Data & AI solutions to create value for customers and enterprises. He has built a (personal) chatbot for fun to answers questions about his career and professional journey. Outside of work he enjoys making portraits of family & friends, and loves creating artworks.