Google sees AI as a foundational and transformational technology, with recent advances in generative AI technologies, such as LaMDA, PaLM, Imagen, Parti, MusicLM, and similar machine learning (ML) models, some of which are now being incorporated into our products. This transformative potential requires us to be responsible not only in how we advance our technology, but also in how we envision which technologies to build, and how we assess the social impact AI and ML-enabled technologies have on the world. This endeavor necessitates fundamental and applied research with an interdisciplinary lens that engages with — and accounts for — the social, cultural, economic, and other contextual dimensions that shape the development and deployment of AI systems. We must also understand the range of possible impacts that ongoing use of such technologies may have on vulnerable communities and broader social systems.
Our team, Technology, AI, Society, and Culture (TASC), is addressing this critical need. Research on the societal impacts of AI is complex and multi-faceted; no one disciplinary or methodological perspective can alone provide the diverse insights needed to grapple with the social and cultural implications of ML technologies. TASC thus leverages the strengths of an interdisciplinary team, with backgrounds ranging from computer science to social science, digital media and urban science. We use a multi-method approach with qualitative, quantitative, and mixed methods to critically examine and shape the social and technical processes that underpin and surround AI technologies. We focus on participatory, culturally-inclusive, and intersectional equity-oriented research that brings to the foreground impacted communities. Our work advances Responsible AI (RAI) in areas such as computer vision, natural language processing, health, and general purpose ML models and applications. Below, we share examples of our approach to Responsible AI and where we are headed in 2023.
 |
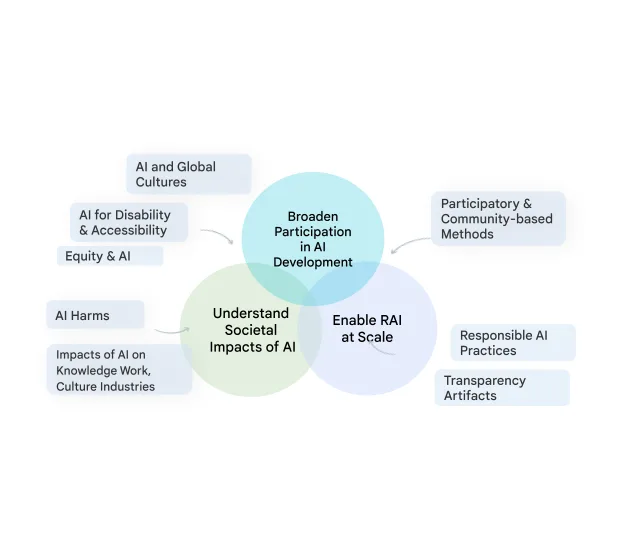
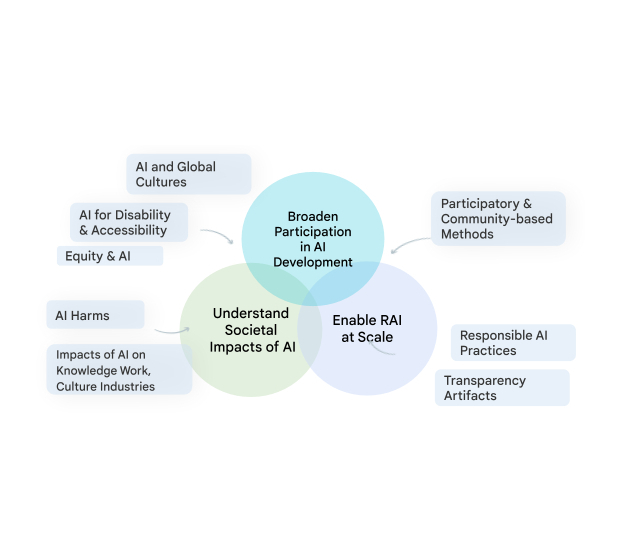
| A visual diagram of the various social, technical, and equity-oriented research areas that TASC studies to progress Responsible AI in a way that respects the complex relationships between AI and society. |
Theme 1: Culture, communities, & AI
One of our key areas of research is the advancement of methods to make generative AI technologies more inclusive of and valuable to people globally, through community-engaged, and culturally-inclusive approaches. Toward this aim, we see communities as experts in their context, recognizing their deep knowledge of how technologies can and should impact their own lives. Our research champions the importance of embedding cross-cultural considerations throughout the ML development pipeline. Community engagement enables us to shift how we incorporate knowledge of what’s most important throughout this pipeline, from dataset curation to evaluation. This also enables us to understand and account for the ways in which technologies fail and how specific communities might experience harm. Based on this understanding we have created responsible AI evaluation strategies that are effective in recognizing and mitigating biases along multiple dimensions.
Our work in this area is vital to ensuring that Google’s technologies are safe for, work for, and are useful to a diverse set of stakeholders around the world. For example, our research on user attitudes towards AI, responsible interaction design, and fairness evaluations with a focus on the global south demonstrated the cross-cultural differences in the impact of AI and contributed resources that enable culturally-situated evaluations. We are also building cross-disciplinary research communities to examine the relationship between AI, culture, and society, through our recent and upcoming workshops on Cultures in AI/AI in Culture, Ethical Considerations in Creative Applications of Computer Vision, and Cross-Cultural Considerations in NLP.
Our recent research has also sought out perspectives of particular communities who are known to be less represented in ML development and applications. For example, we have investigated gender bias, both in natural language and in contexts such as gender-inclusive health, drawing on our research to develop more accurate evaluations of bias so that anyone developing these technologies can identify and mitigate harms for people with queer and non-binary identities.
Theme 2: Enabling Responsible AI throughout the development lifecycle
We work to enable RAI at scale, by establishing industry-wide best practices for RAI across the development pipeline, and ensuring our technologies verifiably incorporate that best practice by default. This applied research includes responsible data production and analysis for ML development, and systematically advancing tools and practices that support practitioners in meeting key RAI goals like transparency, fairness, and accountability. Extending earlier work on Data Cards, Model Cards and the Model Card Toolkit, we released the Data Cards Playbook, providing developers with methods and tools to document appropriate uses and essential facts related to a dataset. Because ML models are often trained and evaluated on human-annotated data, we also advance human-centric research on data annotation. We have developed frameworks to document annotation processes and methods to account for rater disagreement and rater diversity. These methods enable ML practitioners to better ensure diversity in annotation of datasets used to train models, by identifying current barriers and re-envisioning data work practices.
Future directions
We are now working to further broaden participation in ML model development, through approaches that embed a diversity of cultural contexts and voices into technology design, development, and impact assessment to ensure that AI achieves societal goals. We are also redefining responsible practices that can handle the scale at which ML technologies operate in today’s world. For example, we are developing frameworks and structures that can enable community engagement within industry AI research and development, including community-centered evaluation frameworks, benchmarks, and dataset curation and sharing.
In particular, we are furthering our prior work on understanding how NLP language models may perpetuate bias against people with disabilities, extending this research to address other marginalized communities and cultures and including image, video, and other multimodal models. Such models may contain tropes and stereotypes about particular groups or may erase the experiences of specific individuals or communities. Our efforts to identify sources of bias within ML models will lead to better detection of these representational harms and will support the creation of more fair and inclusive systems.
TASC is about studying all the touchpoints between AI and people — from individuals and communities, to cultures and society. For AI to be culturally-inclusive, equitable, accessible, and reflective of the needs of impacted communities, we must take on these challenges with inter- and multidisciplinary research that centers the needs of impacted communities. Our research studies will continue to explore the interactions between society and AI, furthering the discovery of new ways to develop and evaluate AI in order for us to develop more robust and culturally-situated AI technologies.
Acknowledgements
We would like to thank everyone on the team that contributed to this blog post. In alphabetical order by last name: Cynthia Bennett, Eric Corbett, Aida Mostafazadeh Davani, Emily Denton, Sunipa Dev, Fernando Diaz, Mark Díaz, Shaun Kane, Shivani Kapania, Michael Madaio, Vinodkumar Prabhakaran, Rida Qadri, Renee Shelby, Ding Wang, and Andrew Zaldivar. Also, we would like to thank Toju Duke and Marian Croak for their valuable feedback and suggestions.