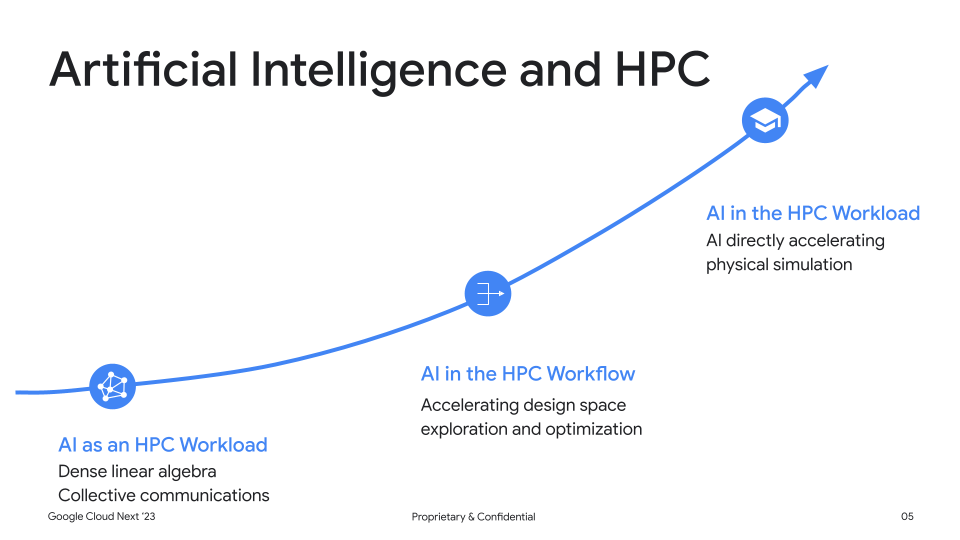
The convergence of high performance computing (HPC) systems and AI and machine learning workloads is transforming the way we solve complex problems. HPC systems are well-suited for AI and machine learning workloads because they offer the AI-enabled computing infrastructure and parallel processing capabilities needed to train ML workloads like large language models (LLMs) — AI models trained on huge sets of textual data to produce relevant responses to requests in natural language. Meanwhile, AI and machine learning workloads can be used to improve the performance of HPC systems by optimizing their algorithms and configurations. And we’re seeing problems traditionally solved with HPC methods being accelerated by or replaced by AI, such as protein folding with AlphaFold.
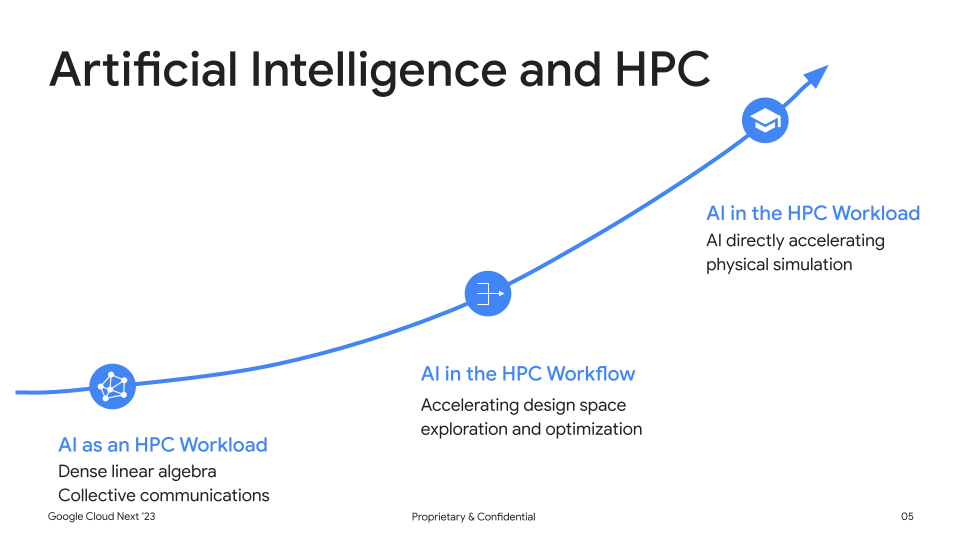
This combination is creating new opportunities for innovation and collaboration between the HPC and AI and machine learning communities. We are seeing customers using AI and machine learning frameworks like the NVIDIA NeMo framework on conventional HPC clusters to customize and deploy models at scale. These systems can be deployed on NVIDIA GPU supercomputers on Google Cloud, such as the A3 VMs powered by NVIDIA H100 Tensor Core GPUs.
Google Cloud HPC Toolkit improvements for AI and ML
Google Cloud HPC Toolkit is a set of open-source tools and resources that help you create repeatable, turnkey HPC environments for your HPC, AI and machine learning workloads; you can quickly and easily use an existing blueprint, or create your own in a simple YAML file, to get a cluster up and running in minutes.
Today we are excited to announce updates to Cloud HPC Toolkit that enable AI and machine learning workloads on Google Cloud. The AI and machine learning blueprint was developed in collaboration with our partner NVIDIA to ensure the best performance for your AI and machine learning needs. Blueprints are available with preconfigured partitions that support three different NVIDIA GPU VM types: G2, A2 and A3.
In addition, the systems can be based on our Ubuntu Deep Learning VM Image and include the latest NCCL Fast Socket optimizations. With powerful tools like the enroot container utility and the Pyxis plugin for Slurm Workload Manager bundled in the blueprint, you can now seamlessly integrate with unprivileged containers and specify the container in a Slurm job. With only a few clicks, you can set up an HPC environment that can train your LLMs on NVIDIA GPUs available on Google Cloud.
Deploy AI and ML with the Cloud HPC Toolkit
Deploying clusters with the HPC Toolkit is a simple process; a typical deployment involves three steps:
- Follow the instructions to set up the Cloud HPC Toolkit for your Google Cloud project.
- Create an HPC deployment folder. Typically, customers customize one of the examples in the github repository and then run
ghpc create <path-to-deployment-configuration.yaml>. This creates a deployment folder that contains all of the auto-generated Terraform configuration, Packer build scripts, and VM startup scripts needed to deploy your cluster, which would otherwise take thousands of lines of custom configuration. - Deploy the infrastructure using
ghpc deploy <path-to-deployment-folder/>. This triggers the deployment of custom VM images, networks, firewalls, and instance templates, as well as Slurm login and controller nodes used to launch workloads.
Once the HPC cluster has been provisioned, you can then train and deploy AI models like any standard HPC workload. First, log into the Slurm login node and run initial verification tests such as
srun -N 1 --gpus-per-node=8 nvidia-smi
Then, you can follow these instructions to install and run the NVIDIA NeMo framework. Similarly, you can also use this tutorial to set up LLaMA, a foundational LLM built by Meta.
What our partners are saying
“The convergence of high performance computing systems and AI and machine learning workloads is transforming the way enterprises across industries tackle complex problems,” said Nirmalya De, Product Manager, NeMo, NVIDIA. “Our collaboration with the Google HPC Toolkit team helps ensure AI and machine learning workloads running NVIDIA NeMo are fast and easily scalable on NVIDIA H100 Tensor Core GPUs available on Google Cloud — unlocking the potential of AI technology with the new HPC Toolkit blueprint.”
Connect with your Google Cloud team today to see how the Cloud HPC Toolkit can get your LLMs up and running faster on HPC systems.