By Gustavo Carmo, Elliot Chow, Nagendra Kamath, Akshay Modi, Jason Ge, Wenbing Bai, Jackson de Campos, Lingyi Liu, Pablo Delgado, Meenakshi Jindal, Boris Chen, Vi Iyengar, Kelli Griggs, Amir Ziai, Prasanna Padmanabhan, and Hossein Taghavi
Introduction
In 2007, Netflix started offering streaming alongside its DVD shipping services. As the catalog grew and users adopted streaming, so did the opportunities for creating and improving our recommendations. With a catalog spanning thousands of shows and a diverse member base spanning millions of accounts, recommending the right show to our members is crucial.
Why should members care about any particular show that we recommend? Trailers and artworks provide a glimpse of what to expect in that show. We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently.
Our goal in building a media-focused ML infrastructure is to reduce the time from ideation to productization for our media ML practitioners. We accomplish this by paving the path to:
- Accessing and processing media data (e.g. video, image, audio, and text)
- Training large-scale models efficiently
- Productizing models in a self-serve fashion in order to execute on existing and newly arriving assets
- Storing and serving model outputs for consumption in promotional content creation
In this post, we will describe some of the challenges of applying machine learning to media assets, and the infrastructure components that we have built to address them. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline. Finally, we’ll conclude with a brief discussion of the opportunities on the horizon.
Infrastructure challenges and components
In this section, we highlight some of the unique challenges faced by media ML practitioners, along with the infrastructure components that we have devised to address them.

Media Access: Jasper
In the early days of media ML efforts, it was very hard for researchers to access media data. Even after gaining access, one needed to deal with the challenges of homogeneity across different assets in terms of decoding performance, size, metadata, and general formatting.
To streamline this process, we standardized media assets with pre-processing steps that create and store dedicated quality-controlled derivatives with associated snapshotted metadata. In addition, we provide a unified library that enables ML practitioners to seamlessly access video, audio, image, and various text-based assets.

Media Feature Storage: Amber Storage
Media feature computation tends to be expensive and time-consuming. Many ML practitioners independently computed identical features against the same asset in their ML pipelines.
To reduce costs and promote reuse, we have built a feature store in order to memoize features/embeddings tied to media entities. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns.

Compute Triggering and Orchestration: Amber Orchestration
Productized models must run over newly arriving assets for scoring. In order to satisfy this requirement, ML practitioners had to develop bespoke triggering and orchestration components per pipeline. Over time, these bespoke components became the source of many downstream errors and were difficult to maintain.
Amber is a suite of multiple infrastructure components that offers triggering capabilities to initiate the computation of algorithms with recursive dependency resolution.

Training Performance
Media model training poses multiple system challenges in storage, network, and GPUs. We have developed a large-scale GPU training cluster based on Ray, which supports multi-GPU / multi-node distributed training. We precompute the datasets, offload the preprocessing to CPU instances, optimize model operators within the framework, and utilize a high-performance file system to resolve the data loading bottleneck, increasing the entire training system throughput 3–5 times.

Serving and Searching
Media feature values can be optionally synchronized to other systems depending on necessary query patterns. One of these systems is Marken, a scalable service used to persist feature values as annotations, which are versioned and strongly typed constructs associated with Netflix media entities such as videos and artwork.
This service provides a user-friendly query DSL for applications to perform search operations over these annotations with specific filtering and grouping. Marken provides unique search capabilities on temporal and spatial data by time frames or region coordinates, as well as vector searches that are able to scale up to the entire catalog.
ML practitioners interact with this infrastructure mostly using Python, but there is a plethora of tools and platforms being used in the systems behind the scenes. These include, but are not limited to, Conductor, Dagobah, Metaflow, Titus, Iceberg, Trino, Cassandra, Elastic Search, Spark, Ray, MezzFS, S3, Baggins, FSx, and Java/Scala-based applications with Spring Boot.
Case study: scaling match cutting using the media ML infra
The Media Machine Learning Infrastructure is empowering various scenarios across Netflix, and some of them are described here. In this section, we showcase the use of this infrastructure through the case study of Match Cutting.
Background
Match Cutting is a video editing technique. It’s a transition between two shots that uses similar visual framing, composition, or action to fluidly bring the viewer from one scene to the next. It is a powerful visual storytelling tool used to create a connection between two scenes.

In an earlier post, we described how we’ve used machine learning to find candidate pairs. In this post, we will focus on the engineering and infrastructure challenges of delivering this feature.
Where we started
Initially, we built Match Cutting to find matches across a single title (i.e. either a movie or an episode within a show). An average title has 2k shots, which means that we need to enumerate and process ~2M pairs.

This entire process was encapsulated in a single Metaflow flow. Each step was mapped to a Metaflow step, which allowed us to control the amount of resources used per step.
Step 1
We download a video file and produce shot boundary metadata. An example of this data is provided below:
SB = {0: [0, 20], 1: [20, 30], 2: [30, 85], …}Each key in the SB dictionary is a shot index and each value represents the frame range corresponding to that shot index. For example, for the shot with index 1 (the second shot), the value captures the shot frame range [20, 30], where 20 is the start frame and 29 is the end frame (i.e. the end of the range is exclusive while the start is inclusive).
Using this data, we then materialized individual clip files (e.g. clip0.mp4, clip1.mp4, etc) corresponding to each shot so that they can be processed in Step 2.
Step 2
This step works with the individual files produced in Step 1 and the list of shot boundaries. We first extract a representation (aka embedding) of each file using a video encoder (i.e. an algorithm that converts a video to a fixed-size vector) and use that embedding to identify and remove duplicate shots.
In the following example SB_deduped is the result of deduplicating SB:
# the second shot (index 1) was removed and so was clip1.mp4
SB_deduped = {0: [0, 20], 2: [30, 85], …}
SB_deduped along with the surviving files are passed along to step 3.
Step 3
We compute another representation per shot, depending on the flavor of match cutting.
Step 4
We enumerate all pairs and compute a score for each pair of representations. These scores are stored along with the shot metadata:
[
# shots with indices 12 and 729 have a high matching score
{shot1: 12, shot2: 729, score: 0.96},
# shots with indices 58 and 419 have a low matching score
{shot1: 58, shot2: 410, score: 0.02},
…
]
Step 5
Finally, we sort the results by score in descending order and surface the top-K pairs, where K is a parameter.
The problems we faced
This pattern works well for a single flavor of match cutting and finding matches within the same title. As we started venturing beyond single-title and added more flavors, we quickly faced a few problems.
Lack of standardization
The representations we extract in Steps 2 and Step 3 are sensitive to the characteristics of the input video files. In some cases such as instance segmentation, the output representation in Step 3 is a function of the dimensions of the input file.
Not having a standardized input file format (e.g. same encoding recipes and dimensions) created matching quality issues when representations across titles with different input files needed to be processed together (e.g. multi-title match cutting).
Wasteful repeated computations
Segmentation at the shot level is a common task used across many media ML pipelines. Also, deduplicating similar shots is a common step that a subset of those pipelines shares.
We realized that memoizing these computations not only reduces waste but also allows for congruence between algo pipelines that share the same preprocessing step. In other words, having a single source of truth for shot boundaries helps us guarantee additional properties for the data generated downstream. As a concrete example, knowing that algo A and algo B both used the same shot boundary detection step, we know that shot index i has identical frame ranges in both. Without this knowledge, we’ll have to check if this is actually true.
Gaps in media-focused pipeline triggering and orchestration
Our stakeholders (i.e. video editors using match cutting) need to start working on titles as quickly as the video files land. Therefore, we built a mechanism to trigger the computation upon the landing of new video files. This triggering logic turned out to present two issues:
- Lack of standardization meant that the computation was sometimes re-triggered for the same video file due to changes in metadata, without any content change.
- Many pipelines independently developed similar bespoke components for triggering computation, which created inconsistencies.
Additionally, decomposing the pipeline into modular pieces and orchestrating computation with dependency semantics did not map to existing workflow orchestrators such as Conductor and Meson out of the box. The media machine learning domain needed to be mapped with some level of coupling between media assets metadata, media access, feature storage, feature compute and feature compute triggering, in a way that new algorithms could be easily plugged with predefined standards.
This is where Amber comes in, offering a Media Machine Learning Feature Development and Productization Suite, gluing all aspects of shipping algorithms while permitting the interdependency and composability of multiple smaller parts required to devise a complex system.
Each part is in itself an algorithm, which we call an Amber Feature, with its own scope of computation, storage, and triggering. Using dependency semantics, an Amber Feature can be plugged into other Amber Features, allowing for the composition of a complex mesh of interrelated algorithms.
Match Cutting across titles
Step 4 entails a computation that is quadratic in the number of shots. For instance, matching across a series with 10 episodes with an average of 2K shots per episode translates into 200M comparisons. Matching across 1,000 files (across multiple shows) would take approximately 200 trillion computations.
Setting aside the sheer number of computations required momentarily, editors may be interested in considering any subset of shows for matching. The naive approach is to pre-compute all possible subsets of shows. Even assuming that we only have 1,000 video files, this means that we have to pre-compute 2¹⁰⁰⁰ subsets, which is more than the number of atoms in the observable universe!
Ideally, we want to use an approach that avoids both issues.
Where we landed
The Media Machine Learning Infrastructure provided many of the building blocks required for overcoming these hurdles.

Standardized video encodes
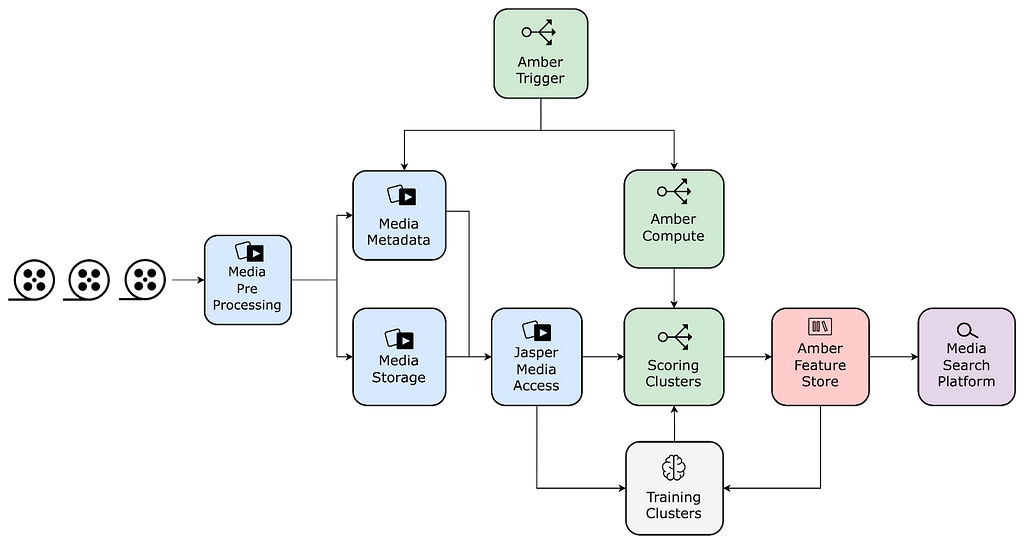
The entire Netflix catalog is pre-processed and stored for reuse in machine learning scenarios. Match Cutting benefits from this standardization as it relies on homogeneity across videos for proper matching.

Shot segmentation and deduplication reuse
Videos are matched at the shot level. Since breaking videos into shots is a very common task across many algorithms, the infrastructure team provides this canonical feature that can be used as a dependency for other algorithms. With this, we were able to reuse memoized feature values, saving on compute costs and guaranteeing coherence of shot segments across algos.

Orchestrating embedding computations
We have used Amber’s feature dependency semantics to tie the computation of embeddings to shot deduplication. Leveraging Amber’s triggering, we automatically initiate scoring for new videos as soon as the standardized video encodes are ready. Amber handles the computation in the dependency chain recursively.

Feature value storage
We store embeddings in Amber, which guarantees immutability, versioning, auditing, and various metrics on top of the feature values. This also allows other algorithms to be built on top of the Match Cutting output as well as all the intermediate embeddings.

Compute pairs and sink to Marken
We have also used Amber’s synchronization mechanisms to replicate data from the main feature value copies to Marken, which is used for serving.

Media Search Platform
Used to serve high-scoring pairs to video editors in internal applications via Marken.
The following figure depicts the new pipeline using the above-mentioned components:

Conclusion and Future Work
The intersection of media and ML holds numerous prospects for innovation and impact. We examined some of the unique challenges that media ML practitioners face and presented some of our early efforts in building a platform that accommodates the scaling of ML solutions.
In addition to the promotional media use cases we discussed, we are extending the infrastructure to facilitate a growing set of use cases. Here are just a few examples:
- ML-based VFX tooling
- Improving recommendations using a suite of content understanding models
- Enriching content understanding ML and creative tooling by leveraging personalization signals and insights
In future posts, we’ll dive deeper into more details about the solutions built for each of the components we have briefly described in this post.
If you’re interested in media ML, we’re always looking for engineers and ML researchers and practitioners to join us!
Acknowledgments
Special thanks to Ben Klein, Fernando Amat Gil, Varun Sekhri, Guru Tahasildar, and Burak Bacioglu for contributing to ideas, designs, and discussions.
![]()
Scaling Media Machine Learning at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.