Large language models (LLMs) have significantly improved the state of the art for solving tasks specified using natural language, often reaching performance close to that of people. As these models increasingly enable assistive agents, it could be beneficial for them to learn effectively from each other, much like people do in social settings, which would allow LLM-based agents to improve each other’s performance.
To discuss the learning processes of humans, Bandura and Walters described the concept of social learning in 1977, outlining different models of observational learning used by people. One common method of learning from others is through a verbal instruction (e.g., from a teacher) that describes how to engage in a particular behavior. Alternatively, learning can happen through a live model by mimicking a live example of the behavior.
Given the success of LLMs mimicking human communication, in our paper “Social Learning: Towards Collaborative Learning with Large Language Models”, we investigate whether LLMs are able to learn from each other using social learning. To this end, we outline a framework for social learning in which LLMs share knowledge with each other in a privacy-aware manner using natural language. We evaluate the effectiveness of our framework on various datasets, and propose quantitative methods that measure privacy in this setting. In contrast to previous approaches to collaborative learning, such as common federated learning approaches that often rely on gradients, in our framework, agents teach each other purely using natural language.
Social learning for LLMs
To extend social learning to language models, we consider the scenario where a student LLM should learn to solve a task from multiple teacher entities that already know that task. In our paper, we evaluate the student’s performance on a variety of tasks, such as spam detection in short text messages (SMS), solving grade school math problems, and answering questions based on a given text.
 |
| A visualization of the social learning process: A teacher model provides instructions or few-shot examples to a student model without sharing its private data. |
Language models have shown a remarkable capacity to perform tasks given only a handful of examples–a process called few-shot learning. With this in mind, we provide human-labeled examples of a task that enables the teacher model to teach it to a student. One of the main use cases of social learning arises when these examples cannot be directly shared with the student due, for example, to privacy concerns.
To illustrate this, let’s look at a hypothetical example for a spam detection task. A teacher model is located on device where some users volunteer to mark incoming messages they receive as either “spam” or “not spam”. This is useful data that could help train a student model to differentiate between spam and not spam, but sharing personal messages with other users is a breach of privacy and should be avoided. To prevent this, a social learning process can transfer the knowledge from the teacher model to the student so it learns what spam messages look like without needing to share the user’s personal text messages.
We investigate the effectiveness of this social learning approach by analogy with the established human social learning theory that we discussed above. In these experiments, we use PaLM 2-S models for both the teacher and the student.
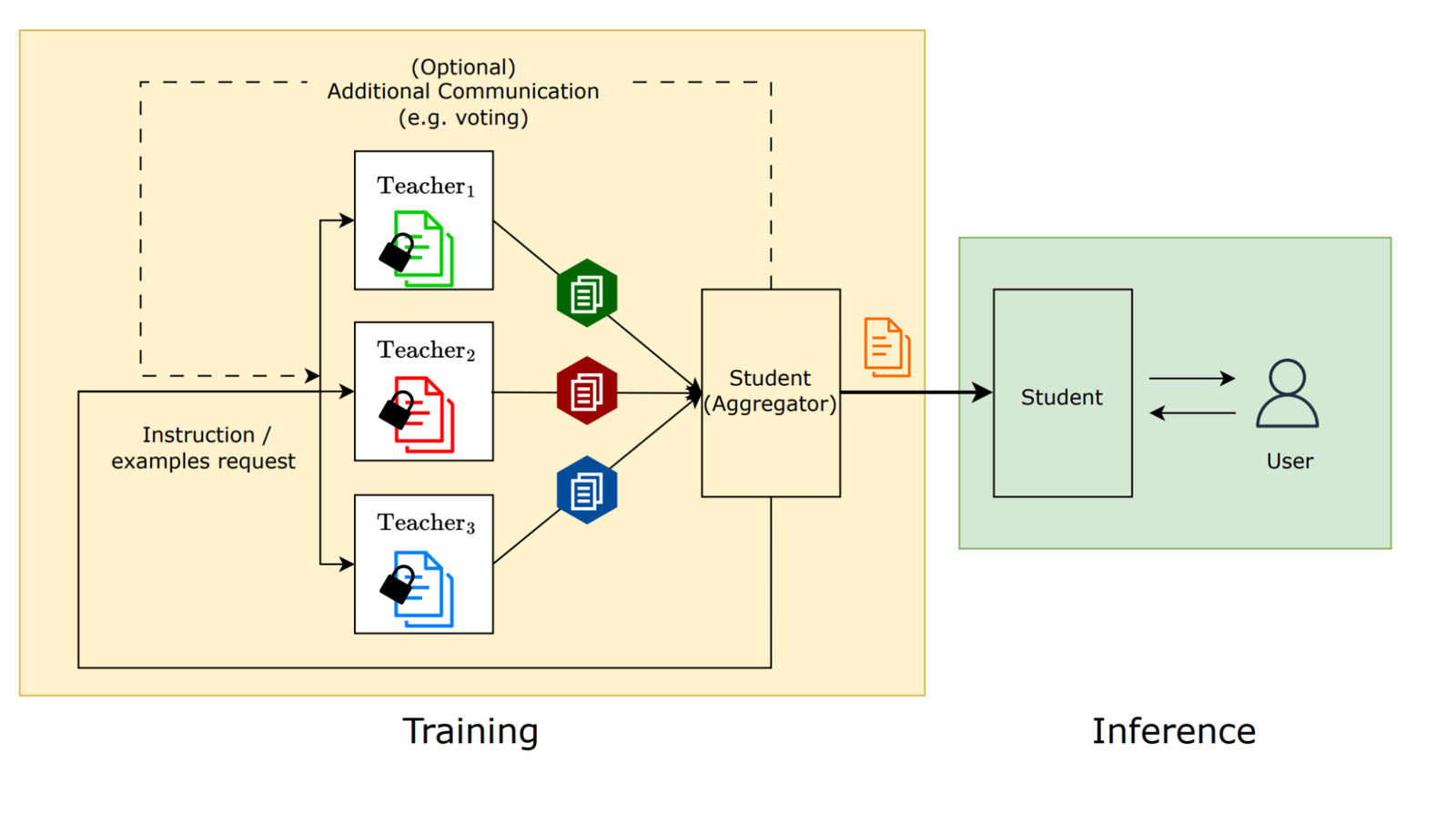
 |
| A systems view of social learning: At training time, multiple teachers teach the student. At inference time, the student is using what it learned from the teachers. |
Synthetic examples
As a counterpart to the live teaching model described for traditional social learning, we propose a learning method where the teachers generate new synthetic examples for the task and share them with the student. This is motivated by the idea that one can create a new example that is sufficiently different from the original one, but is just as educational. Indeed, we observe that our generated examples are sufficiently different from the real ones to preserve privacy while still enabling performance comparable to that achieved using the original examples.
 |
| The 8 generated examples perform as well as the original data for several tasks (see our paper). |
We evaluate the efficacy of learning through synthetic examples on our task suite. Especially when the number of examples is high enough, e.g., n = 16, we observe no statistically significant difference between sharing original data and teaching with synthesized data via social learning for the majority of tasks, indicating that the privacy improvement does not have to come at the cost of model quality.
 |
| Generating 16 instead of just 8 examples further reduces the performance gap relative to the original examples. |
The one exception is spam detection, for which teaching with synthesized data yields lower accuracy. This may be because the training procedure of current models makes them biased to only generate non-spam examples. In the paper, we additionally look into aggregation methods for selecting good subsets of examples to use.
Synthetic instruction
Given the success of language models in following instructions, the verbal instruction model can also be naturally adapted to language models by having the teachers generate an instruction for the task. Our experiments show that providing such a generated instruction effectively improves performance over zero-shot prompting, reaching accuracies comparable to few-shot prompting with original examples. However, we did find that the teacher model may fail on certain tasks to provide a good instruction, for example due to a complicated formatting requirement of the output.
For Lambada, GSM8k, and Random Insertion, providing synthetic examples performs better than providing generated instructions, whereas in the other tasks generated instruction obtains a higher accuracy. This observation suggests that the choice of the teaching model depends on the task at hand, similar to how the most effective method for teaching people varies by task.
 |
| Depending on the task, generating instructions can work better than generating new examples. |
Memorization of the private examples
We want teachers in social learning to teach the student without revealing specifics from the original data. To quantify how prone this process is to leaking information, we used Secret Sharer, a popular method for quantifying to what extent a model memorizes its training data, and adapted it to the social learning setting. We picked this method since it had previously been used for evaluating memorization in federated learning.
To apply the Secret Sharer method to social learning, we design “canary” data points such that we can concretely measure how much the training process memorized them. These data points are included in the datasets used by teachers to generate new examples. After the social learning process completes, we can then measure how much more confident the student is in the secret data points the teacher used, compared to similar ones that were not shared even with the teachers.
In our analysis, discussed in detail in the paper, we use canary examples that include names and codes. Our results show that the student is only slightly more confident in the canaries the teacher used. In contrast, when the original data points are directly shared with the student, the confidence in the included canaries is much higher than in the held-out set. This supports the conclusion that the teacher does indeed use its data to teach without simply copying it over.
Conclusion and next steps
We introduced a framework for social learning that allows language models with access to private data to transfer knowledge through textual communication while maintaining the privacy of that data. In this framework, we identified sharing examples and sharing instructions as basic models and evaluated them on multiple tasks. Furthermore, we adapted the Secret Sharer metric to our framework, proposing a metric for measuring data leakage.
As next steps, we are looking for ways of improving the teaching process, for example by adding feedback loops and iteration. Furthermore, we want to investigate using social learning for modalities other than text.
Acknowledgements
We would like to acknowledge and thank Matt Sharifi, Sian Gooding, Lukas Zilka, and Blaise Aguera y Arcas, who are all co-authors on the paper. Furthermore, we would like to thank Victor Cărbune, Zachary Garrett, Tautvydas Misiunas, Sofia Neata and John Platt for their feedback, which greatly improved the paper. We’d also like to thank Tom Small for creating the animated figure.