Text Summarization with Scikit-LLM
In a
In a
The idea of building your own AI agent used to feel like something only big tech companies could pull off.
FastAPI has become one of the most popular ways to serve machine learning models because it is lightweight, fast, and easy to use.
A stateless AI agent has no memory of previous calls.
Zero-shot text classification is a way to label text without first training a classifier on your own task-specific dataset.
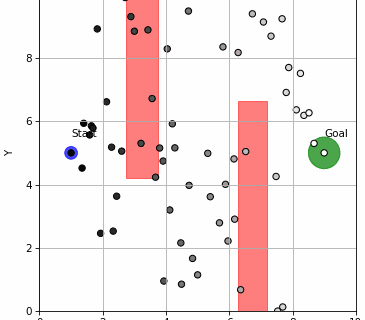
GRASP is a new gradient-based planner for learned dynamics (a “world model”) that makes long-horizon planning practical by (1) lifting the trajectory into virtual states so optimization is parallel across time, (2) adding stochasticity directly to the state iterates for exploration, and (3) reshaping gradients so actions get clean signals while we avoid brittle “state-input” …
Read more “Gradient-based Planning for World Models at Longer Horizons”
Calling a large language model API at scale is expensive and slow.
You’ve probably written a decorator or two in your Python career.
Language models (LMs), at their core, are text-in and text-out systems.