Enterprises are seeking to quickly unlock the potential of generative AI by providing access to foundation models (FMs) to different lines of business (LOBs). IT teams are responsible for helping the LOB innovate with speed and agility while providing centralized governance and observability. For example, they may need to track the usage of FMs across teams, chargeback costs and provide visibility to the relevant cost center in the LOB. Additionally, they may need to regulate access to different models per team. For example, if only specific FMs may be approved for use.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
A software as a service (SaaS) layer for foundation models can provide a simple and consistent interface for end-users, while maintaining centralized governance of access and consumption. API gateways can provide loose coupling between model consumers and the model endpoint service, and flexibility to adapt to changing model, architectures, and invocation methods.
In this post, we show you how to build an internal SaaS layer to access foundation models with Amazon Bedrock in a multi-tenant (team) architecture. We specifically focus on usage and cost tracking per tenant and also controls such as usage throttling per tenant. We describe how the solution and Amazon Bedrock consumption plans map to the general SaaS journey framework. The code for the solution and an AWS Cloud Development Kit (AWS CDK) template is available in the GitHub repository.
Challenges
An AI platform administrator needs to provide standardized and easy access to FMs to multiple development teams.
The following are some of the challenges to provide governed access to foundation models:
- Cost and usage tracking – Track and audit individual tenant costs and usage of foundation models, and provide chargeback costs to specific cost centers
- Budget and usage controls – Manage API quota, budget, and usage limits for the permitted use of foundation models over a defined frequency per tenant
- Access control and model governance – Define access controls for specific allow listed models per tenant
- Multi-tenant standardized API – Provide consistent access to foundation models with OpenAPI standards
- Centralized management of API – Provide a single layer to manage API keys for accessing models
- Model versions and updates – Handle new and updated model version rollouts
Solution overview
In this solution, we refer to a multi-tenant approach. A tenant here can range from an individual user, a specific project, team, or even an entire department. As we discuss the approach, we use the term team, because it’s the most common. We use API keys to restrict and monitor API access for teams. Each team is assigned an API key for access to the FMs. There can be different user authentication and authorization mechanisms deployed in an organization. For simplicity, we do not include these in this solution. You may also integrate existing identity providers with this solution.
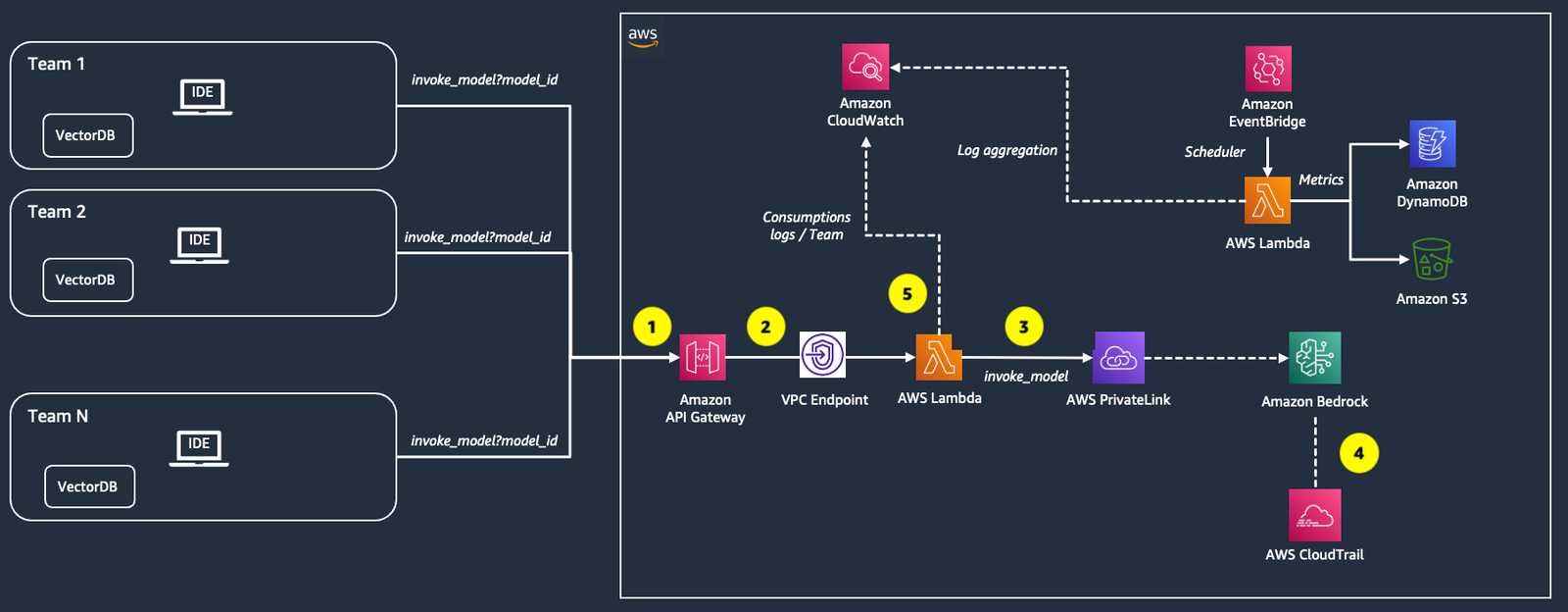
The following diagram summarizes the solution architecture and key components. Teams (tenants) assigned to separate cost centers consume Amazon Bedrock FMs via an API service. To track consumption and cost per team, the solution logs data for each individual invocation, including the model invoked, number of tokens for text generation models, and image dimensions for multi-modal models. In addition, it aggregates the invocations per model and costs by each team.

You can deploy the solution in your own account using the AWS CDK. AWS CDK is an open source software development framework to model and provision your cloud application resources using familiar programming languages. The AWS CDK code is available in the GitHub repository.
In the following sections, we discuss the key components of the solution in more detail.
Capturing foundation model usage per team
The workflow to capture FM usage per team consists of the following steps (as numbered in the preceding diagram):
- A team’s application sends a POST request to Amazon API Gateway with the model to be invoked in the
model_idquery parameter and the user prompt in the request body. - API Gateway routes the request to an AWS Lambda function (
bedrock_invoke_model) that’s responsible for logging team usage information in Amazon CloudWatch and invoking the Amazon Bedrock model. - Amazon Bedrock provides a VPC endpoint powered by AWS PrivateLink. In this solution, the Lambda function sends the request to Amazon Bedrock using PrivateLink to establish a private connection between the VPC in your account and the Amazon Bedrock service account. To learn more about PrivateLink, see Use AWS PrivateLink to set up private access to Amazon Bedrock.
- After the Amazon Bedrock invocation, Amazon CloudTrail generates a CloudTrail event.
- If the Amazon Bedrock call is successful, the Lambda function logs the following information depending on the type of invoked model and returns the generated response to the application:
- team_id – The unique identifier for the team issuing the request.
- requestId – The unique identifier of the request.
- model_id – The ID of the model to be invoked.
- inputTokens – The number of tokens sent to the model as part of the prompt (for text generation and embeddings models).
- outputTokens – The maximum number of tokens to be generated by the model (for text generation models).
- height – The height of the requested image (for multi-modal models and multi-modal embeddings models).
- width – The width of the requested image (for multi-modal models only).
- steps – The steps requested (for Stability AI models).
Tracking costs per team
A different flow aggregates the usage information, then calculates and saves the on-demand costs per team on a daily basis. By having a separate flow, we ensure that cost tracking doesn’t impact the latency and throughput of the model invocation flow. The workflow steps are as follows:
- An Amazon EventBridge rule triggers a Lambda function (
bedrock_cost_tracking) daily. - The Lambda function gets the usage information from CloudWatch for the previous day, calculates the associated costs, and stores the data aggregated by
team_idandmodel_idin Amazon Simple Storage Service (Amazon S3) in CSV format.
To query and visualize the data stored in Amazon S3, you have different options, including S3 Select, and Amazon Athena and Amazon QuickSight.
Controlling usage per team
A usage plan specifies who can access one or more deployed APIs and optionally sets the target request rate to start throttling requests. The plan uses API keys to identify API clients who can access the associated API for each key. You can use API Gateway usage plans to throttle requests that exceed predefined thresholds. You can also use API keys and quota limits, which enable you to set the maximum number of requests per API key each team is permitted to issue within a specified time interval. This is in addition to Amazon Bedrock service quotas that are assigned only at the account level.
Prerequisites
Before you deploy the solution, make sure you have the following:
- An AWS account. If you are new to AWS, see Creating an AWS account.
- The AWS Command Line Interface (AWS CLI) installed in your development environment and an AWS CLI profile configured with AWS Identity and Access Management (IAM) permissions to deploy the resources used in this solution.
- Python 3 installed in your development environment.
- AWS CDK installed in your development environment.
Deploy the AWS CDK stack
Follow the instructions in the README file of the GitHub repository to configure and deploy the AWS CDK stack.
The stack deploys the following resources:
- Private networking environment (VPC, private subnets, security group)
- IAM role for controlling model access
- Lambda layers for the necessary Python modules
- Lambda function
invoke_model - Lambda function
list_foundation_models - Lambda function
cost_tracking - Rest API (API Gateway)
- API Gateway usage plan
- API key associated to the usage plan
Onboard a new team
For providing access to new teams, you can either share the same API key across different teams and track the model consumptions by providing a different team_id for the API invocation, or create dedicated API keys used for accessing Amazon Bedrock resources by following the instructions provided in the README.
The stack deploys the following resources:
- API Gateway usage plan associated to the previously created REST API
- API key associated to the usage plan for the new team, with reserved throttling and burst configurations for the API
For more information about API Gateway throttling and burst configurations, refer to Throttle API requests for better throughput.
After you deploy the stack, you can see that the new API key for team-2 is created as well.

Configure model access control
The platform administrator can allow access to specific foundation models by editing the IAM policy associated to the Lambda function invoke_model. The
IAM permissions are defined in the file setup/stack_constructs/iam.py. See the following code:
Invoke the service
After you have deployed the solution, you can invoke the service directly from your code. The following
is an example in Python for consuming the invoke_model API for text generation through a POST request:
Output: Amazon Bedrock is an internal technology platform developed by Amazon to run and operate many of their services and products. Some key things about Bedrock …
The following is another example in Python for consuming the invoke_model API for embeddings generation through a POST request:
model_id = "amazon.titan-embed-text-v1" #the model id for the Amazon Titan Embeddings Text model
prompt = "What is Amazon Bedrock?"
response = requests.post(
f"{api_url}/invoke_model?model_id={model_id}",
json={"inputs": prompt, "parameters": model_kwargs},
headers={
"x-api-key": api_key, #key for querying the API
"team_id": team_id #unique tenant identifier,
"embeddings": "true" #boolean value for the embeddings model
}
)
text = response.json()[0]["embedding"]
Output: 0.91796875, 0.45117188, 0.52734375, -0.18652344, 0.06982422, 0.65234375, -0.13085938, 0.056884766, 0.092285156, 0.06982422, 1.03125, 0.8515625, 0.16308594, 0.079589844, -0.033935547, 0.796875, -0.15429688, -0.29882812, -0.25585938, 0.45703125, 0.044921875, 0.34570312 …
Access denied to foundation models
The following is an example in Python for consuming the invoke_model API for text generation through a POST request with an access denied response:
<Response [500]> “Traceback (most recent call last):n File ”/var/task/index.py”, line 213, in lambda_handlern response = _invoke_text(bedrock_client, model_id, body, model_kwargs)n File ”/var/task/index.py”, line 146, in _invoke_textn raise en File ”/var/task/index.py”, line 131, in _invoke_textn response = bedrock_client.invoke_model(n File ”/opt/python/botocore/client.py”, line 535, in _api_calln return self._make_api_call(operation_name, kwargs)n File ”/opt/python/botocore/client.py”, line 980, in _make_api_calln raise error_class(parsed_response, operation_name)nbotocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the InvokeModel operation: Your account is not authorized to invoke this API operation.n”
Cost estimation example
When invoking Amazon Bedrock models with on-demand pricing, the total cost is calculated as the sum of the input and output costs. Input costs are based on the number of input tokens sent to the model, and output costs are based on the tokens generated. The prices are per 1,000 input tokens and per 1,000 output tokens. For more details and specific model prices, refer to Amazon Bedrock Pricing.
Let’s look at an example where two teams, team1 and team2, access Amazon Bedrock through the solution in this post. The usage and cost data saved in Amazon S3 in a single day is shown in the following table.
The columns input_tokens and output_tokens store the total input and output tokens across model invocations per model and per team, respectively, for a given day.
The columns input_cost and output_cost store the respective costs per model and per team. These are calculated using the following formulas:
input_cost = input_token_count * model_pricing["input_cost"] / 1000
output_cost = output_token_count * model_pricing["output_cost"] / 1000
| team_id | model_id | input_tokens | output_tokens | invocations | input_cost | output_cost |
| Team1 | amazon.titan-tg1-large | 24000 | 2473 | 1000 | 0.0072 | 0.00099 |
| Team1 | anthropic.claude-v2 | 2448 | 4800 | 24 | 0.02698 | 0.15686 |
| Team2 | amazon.titan-tg1-large | 35000 | 52500 | 350 | 0.0105 | 0.021 |
| Team2 | ai21.j2-grande-instruct | 4590 | 9000 | 45 | 0.05738 | 0.1125 |
| Team2 | anthropic.claude-v2 | 1080 | 4400 | 20 | 0.0119 | 0.14379 |
End-to-end view of a functional multi-tenant serverless SaaS environment
Let’s understand what an end-to-end functional multi-tenant serverless SaaS environment might look like. The following is a reference architecture diagram.

This architecture diagram is a zoomed-out version of the previous architecture diagram explained earlier in the post, where the previous architecture diagram explains the details of one of the microservices mentioned (foundational model service). This diagram explains that, apart from foundational model service, you need to have other components as well in your multi-tenant SaaS platform to implement a functional and scalable platform.
Let’s go through the details of the architecture.
Tenant applications
The tenant applications are the front end applications that interact with the environment. Here, we show multiple tenants accessing from different local or AWS environments. The front end applications can be extended to include a registration page for new tenants to register themselves and an admin console for administrators of the SaaS service layer. If the tenant applications require a custom logic to be implemented that needs interaction with the SaaS environment, they can implement the specifications of the application adaptor microservice. Example scenarios could be adding custom authorization logic while respecting the authorization specifications of the SaaS environment.
Shared services
The following are shared services:
- Tenant and user management services –These services are responsible for registering and managing the tenants. They provide the cross-cutting functionality that’s separate from application services and shared across all of the tenants.
- Foundation model service –The solution architecture diagram explained at the beginning of this post represents this microservice, where the interaction from API Gateway to Lambda functions is happening within the scope of this microservice. All tenants use this microservice to invoke the foundations models from Anthropic, AI21, Cohere, Stability, Meta, and Amazon, as well as fine-tuned models. It also captures the information needed for usage tracking in CloudWatch logs.
- Cost tracking service –This service tracks the cost and usage for each tenant. This microservice runs on a schedule to query the CloudWatch logs and output the aggregated usage tracking and inferred cost to the data storage. The cost tracking service can be extended to build further reports and visualization.
Application adaptor service
This service presents a set of specifications and APIs that a tenant may implement in order to integrate their custom logic to the SaaS environment. Based on how much custom integration is needed, this component can be optional for tenants.
Multi-tenant data store
The shared services store their data in a data store that can be a single shared Amazon DynamoDB table with a tenant partitioning key that associates DynamoDB items with individual tenants. The cost tracking shared service outputs the aggregated usage and cost tracking data to Amazon S3. Based on the use case, there can be an application-specific data store as well.
A multi-tenant SaaS environment can have a lot more components. For more information, refer to Building a Multi-Tenant SaaS Solution Using AWS Serverless Services.
Support for multiple deployment models
SaaS frameworks typically outline two deployment models: pool and silo. For the pool model, all tenants access FMs from a shared environment with common storage and compute infrastructure. In the silo model, each tenant has its own set of dedicated resources. You can read about isolation models in the SaaS Tenant Isolation Strategies whitepaper.
The proposed solution can be adopted for both SaaS deployment models. In the pool approach, a centralized AWS environment hosts the API, storage, and compute resources. In silo mode, each team accesses APIs, storage, and compute resources in a dedicated AWS environment.
The solution also fits with the available consumption plans provided by Amazon Bedrock. AWS provides a choice of two consumptions plan for inference:
- On-Demand – This mode allows you to use foundation models on a pay-as-you-go basis without having to make any time-based term commitments
- Provisioned Throughput – This mode allows you to provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment
For more information about these options, refer to Amazon Bedrock Pricing.
The serverless SaaS reference solution described in this post can apply the Amazon Bedrock consumption plans to provide basic and premium tiering options to end-users. Basic could include On-Demand or Provisioned Throughput consumption of Amazon Bedrock and could include specific usage and budget limits. Tenant limits could be enabled by throttling requests based on requests, token sizes, or budget allocation. Premium tier tenants could have their own dedicated resources with provisioned throughput consumption of Amazon Bedrock. These tenants would typically be associated with production workloads that require high throughput and low latency access to Amazon Bedrock FMs.
Conclusion
In this post, we discussed how to build an internal SaaS platform to access foundation models with Amazon Bedrock in a multi-tenant setup with a focus on tracking costs and usage, and throttling limits for each tenant. Additional topics to explore include integrating existing authentication and authorization solutions in the organization, enhancing the API layer to include web sockets for bi-directional client server interactions, adding content filtering and other governance guardrails, designing multiple deployment tiers, integrating other microservices in the SaaS architecture, and many more.
The entire code for this solution is available in the GitHub repository.
For more information about SaaS-based frameworks, refer to SaaS Journey Framework: Building a New SaaS Solution on AWS.
About the Authors
 Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS. He has over 15 years of combined work experience in machine learning, software development and data science on the cloud. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS. He has over 15 years of combined work experience in machine learning, software development and data science on the cloud. In his spare time, Hasan loves to explore nature and spend time with friends and family.
 Anastasia Tzeveleka is a Senior AI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers across EMEA build foundation models and create scalable generative AI and machine learning solutions using AWS services.
Anastasia Tzeveleka is a Senior AI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers across EMEA build foundation models and create scalable generative AI and machine learning solutions using AWS services.
 Bruno Pistone is a Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
Bruno Pistone is a Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
 Vikesh Pandey is a Generative AI/ML Solutions architect, specialising in financial services where he helps financial customers build and scale Generative AI/ML platforms and solution which scales to hundreds to even thousands of users. In his spare time, Vikesh likes to write on various blog forums and build legos with his kid.
Vikesh Pandey is a Generative AI/ML Solutions architect, specialising in financial services where he helps financial customers build and scale Generative AI/ML platforms and solution which scales to hundreds to even thousands of users. In his spare time, Vikesh likes to write on various blog forums and build legos with his kid.