Exploring self-distilled reasoning for supervised fine-tuning with Amazon Nova
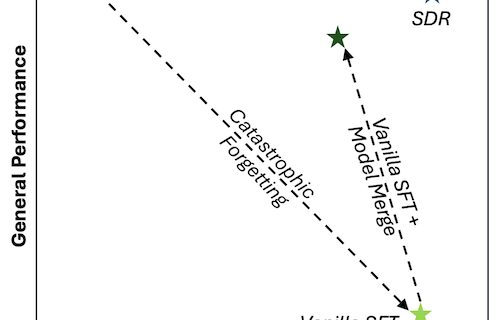
When you fine-tune a model using Supervised Fine-Tuning (SFT), creating high-quality chain-of-thought (CoT) reasoning traces for your training data is often impractical and can be prohibitively expensive. As a result, you might choose to skip reasoning during SFT and train with only inputs and outputs. However, reasoning is a key capability of the Amazon Nova …
Read more “Exploring self-distilled reasoning for supervised fine-tuning with Amazon Nova”