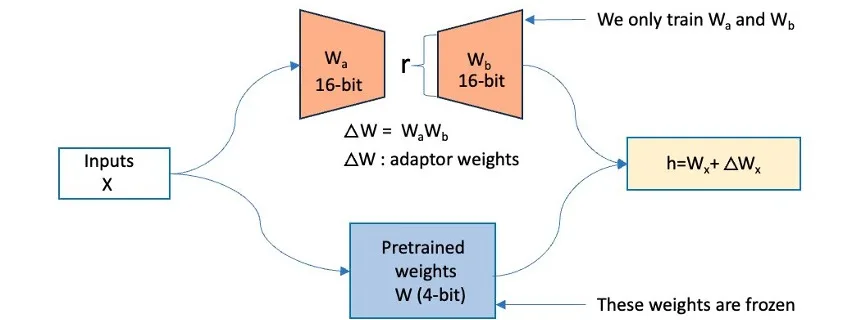
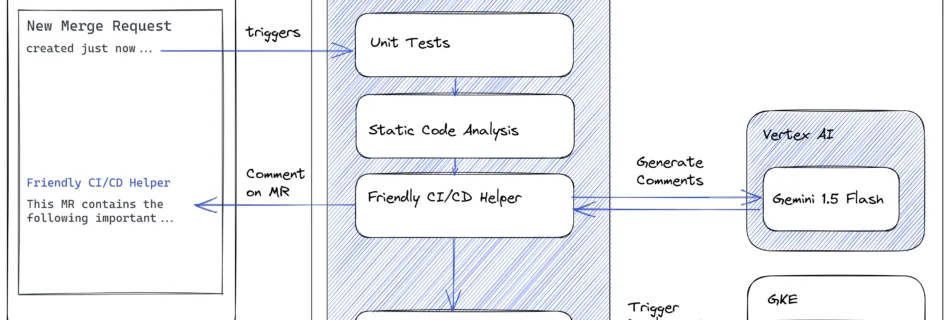
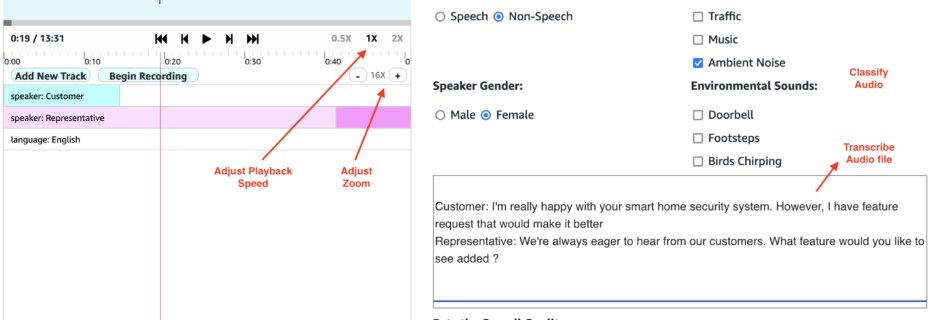
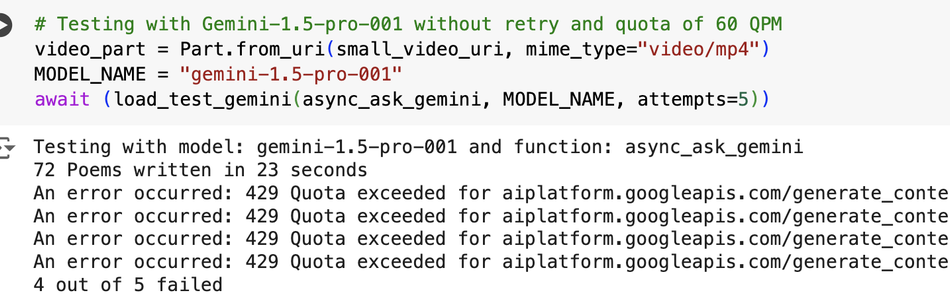
Multimodal Autoregressive Pre-Training of Large Vision Encoders
*Equal Contributors A dominant paradigm in large multimodal models is to pair a large language de- coder with a vision encoder. While it is well-known how to pre-train and tune language decoders for multimodal tasks, it is less clear how the vision encoder should be pre-trained. A de facto standard is to pre-train the vision …
Read more “Multimodal Autoregressive Pre-Training of Large Vision Encoders”