Customers tell us they see great potential in using large language models (LLMs) with their data to improve customer experiences, automate internal processes, access and find information, and create new content —just to name a few of the emerging generative AI use cases. There are many ways to leverage your data, so in this blog, we’ll discuss some of the main approaches and applications, and what you need to know to get started.
Methods to bring your data to foundation models
Before we get started visualizing a generative AI application, we need to understand the ways in which LLMs and other foundation models can interact with your data.
Prompt engineering
The easiest way to facilitate interactions between a model and your data is to include the data in the instructions, or system prompt, sent to the model. In this approach, the model doesn’t need to be changed or adapted — which is very powerful and attractive, but also potentially limiting for some use cases. For example, whereas static information could be easily added to a system prompt and used to steer interactions, the same isn’t true for information that is frequently updated, such as sports scores or airline prices.
Retrieval augmented generation (RAG)
Retrieval augmented generation, or RAG, helps ensure model outputs are grounded on your data. Instead of relying on the model’s training knowledge, AI apps architected for RAG can search your data for information relevant to a query, then pass that information into the prompt. This is similar to prompt engineering, except that the system can find and retrieve new context from your data with each interaction.
The RAG approach supports fresh data that’s constantly updated, private data that you connect, large-scale and multimodal data, and more — and it’s supported by an increasingly robust ecosystem of products, from simple integrations with databases to embedding APIs and other components for bespoke systems.
Supervised fine-tuning (SFT)
If you want to give a model specific instructions for a well-defined task, you might consider SFT, also often referred to as Parameter Efficient Fine Tuning (PEFT). This can work well for tasks like classification, or creating structured outputs from free text.
To perform supervised fine tuning, you need to have the model learn from input-output pairs that you provide the model. For example, if you want to classify meeting transcripts into different categories (for example, “marketing,” “legal.” “customer-support”), then you’ll need to provide the supervised tuning process multiple transcripts along with the categories of the meetings. The tuning process will learn what you consider to be the right classification for your meetings.
Reinforcement Learning from Human Feedback (RLHF)
What if your goal is not well described into categories or isn’t easy to quantify? For example, suppose you want a model to have a certain tone (perhaps to have a brand voice, or to be formal in specific ways). Reinforcement Learning from Human Feedback, or RLHF, is a technique that creates a model that is tuned to your specific needs, enhanced by a human’s preferences.
The algorithm looks like the following in a nutshell: You provide your data in the form of input prompts and output responses, but the output responses have to be in pairs: two plausible responses but one that you prefer over the other. For example, one might be correct but generic while the other is both correct and uses a language style that you want in your outputs.
Distillation
The clever technique of distillation combines two goals: creating a smaller model that is faster and quicker to process data, and making that model more specific to your tasks. It works by using a larger foundation model to “teach” a smaller model, and by focusing that teaching on your data and task. For example, imagine you want to double-check all your emails to make them more formal—and you want to do this with a smaller model. To achieve this, you give the input (the original text and the instruction “make this email more formal”) to the large model, and it gives you the output (the re-written email). Now, equipped with your inputs and the large model outputs, you can train a small specialized model to learn to reproduce this specific task. In addition to the foundation models input/output pairs, you can provide your own as well.
Which one to go for?
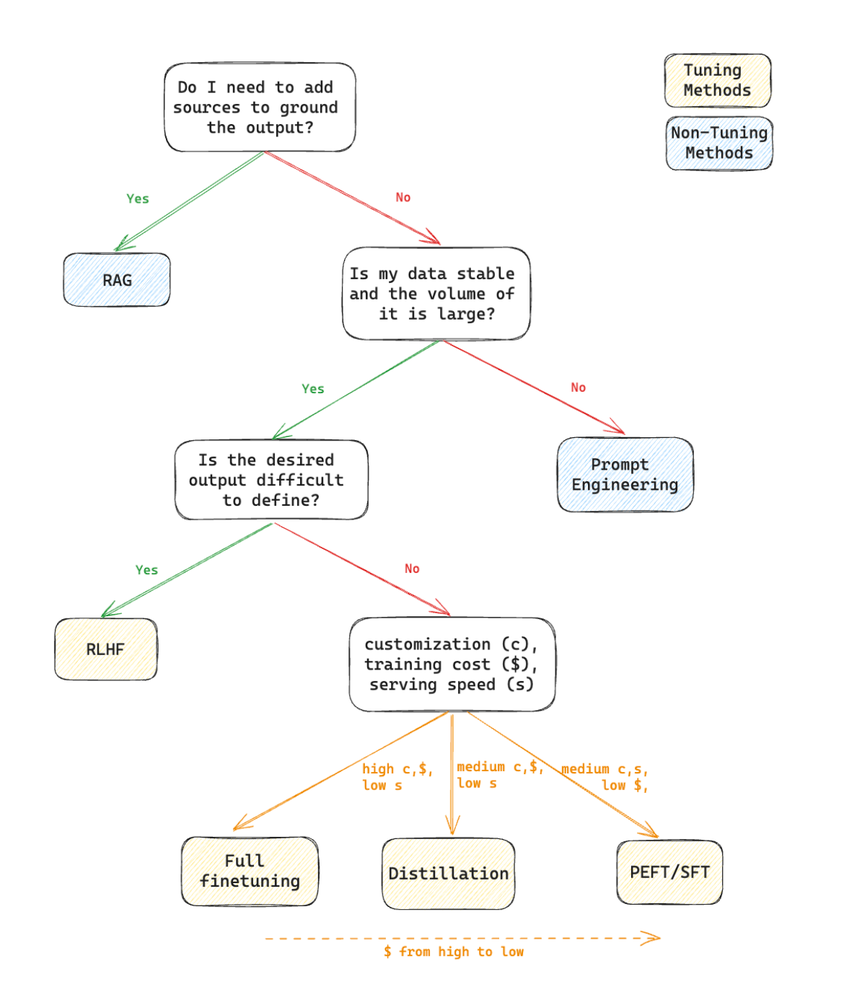
The first question to consider is: do you need the model to always give a citation of a source grounded in your data? If yes, you will need to use RAG. RAG also has the benefit that you can control who has access to which grounding data (based on who’s calling the model). That will help you combat hallucinations and enhance interpretability of the results.
If you don’t have those requirements, you’ll need to decide if prompt engineering is enough, or if you need to tune the model. If you have only a small amount of data, then prompt engineering may suffice — and with context windows continuing to grow, as evidenced by Gemini 1.5’s 1 million-token window, prompt engineering is becoming viable for large amounts of data as well..
If you choose tuning, then you’ll need to consider tuning options in accordance with how specific and difficult to quantify your desired model’s behavior is. In cases where your desired model produces an output that’s difficult to describe, human involvement is probably needed, so RLHF is the way to go. Otherwise, different tuning methods could be chosen considering how much personalization you need for your model, your budget, and how fast serving speed you require.
This decision tree is a simplified version of the reasoning we describe:

Why not combine methods?
You may ask: why can’t I use more methods? For example: I want to fine-tune my model to have my brand voice and I also want it to use only my data to generate answers (RAG). That is also possible and often the best option! You can tune a model and then use it to perform another task. Or you can also tune an LLM and then perform in-context prompt engineering on it to make sure the model behaves as desired. To sum up, you can freely combine the aforementioned methods at your convenience.
Get started!
Start simple. Not only that will speed you up, it will also give you a baseline from where to experiment and test what works best for your application.
You can try out all these capabilities on Google Cloud! Try Prompt Engineering, Vertex AI Agent Builder’s implementation of RAG, or if you would like to go for your own implementation of RAG, try our Embeddings or Multimodal Embeddings API to create them, and Vector Search to store them. Furthermore, experiment with Supervised Fine Tuning, Tuning with RLHF, and Distillation. And you can have a look at our code samples to help you.