
Transfer Learning: Object Detection in Satellite Imagery

Object detection in satellite imagery is a critical component of many complex commercial and government workflows. At Palantir, we’ve worked with customers across a wide variety of use cases to improve the ability of their models to detect relevant context more accurately.
On the commercial front, these models are often a critical component of emergency response coordination to natural disasters. Their ability to detect buildings and assess damage allows for critical services to be delivered faster, whether allowing for better coordination of emergency response crews or aiding insurance companies in quickly processing claims. But this technology is not only useful in crisis — it can also used by financial firms to forecast retailer demand based on the number of vehicles detected in retailer’s parking lots. For government users, the application is straightforward: knowing the position or movement over time of friendly and enemy equipment such as aircrafts, ships and vehicles empowers critical strategic decision making.
For all categories of use cases, determining how best to train object detection models to maximize utility can be a challenge. Below, we unpack the challenges of training accurate models, and publish the findings of our own experiment using two different pre-trained models on the same set of images. We hope that our learnings can aid other users in identifying successful strategies to pre-train their own models more effectively.
The Challenges of Training Accurate Models
Training accurate object detection models to enable these use cases requires vast amounts of labeled datasets. In the case of satellite imagery, the complexity of this training is even more potent: the images are large, especially in comparison to the small size of the objects we need to detect. Coupled with variations in hardware and image processing software leveraged across the different satellite operators, collecting the perfectly labeled dataset to train a generalizable object detection model is hard. This reality, along with the pressure to enable end-to-end user workflows as quickly as possible, often leads our customers to ask us for help solving a critical question: how can one build the best possible object detection model on a limited training dataset and in a short amount of time?
At Palantir, we’ve seen that the best possible results are not often produced by users trying to train an object detection model from scratch on a limited dataset. There are many techniques used to address this problem, the most popular of which is transfer learning. In transfer learning, we first pre-train the object detection model on one or more proxy datasets and then leverage the trained weights to initialize the model when it trains on the actual limited downstream dataset we really care about.
The most popular pre-training datasets for object detection tasks are ImageNet [1] and COCO [2]. Their popularity stems from the fact that they specifically focus on object detection problems, as well as the wide availability of models pre-trained on these datasets within the academic community. Even though pre-training on ImageNet and COCO datasets can improve model accuracy on downstream datasets, additional boosts to performance can be realized if models are further pre-trained on datasets that are similar to the downstream task. In general, the more similar the pre-training dataset is to the downstream dataset we care about, the higher the accuracy lift we can expect from pre-training. For instance, when considering the problem of object detection in satellite imagery, ImageNet and/or COCO pre-training might not be enough as these datasets are very different than a typical satellite object detection dataset (i.e., size of objects, types of objects, image background characteristics and more). In these cases, pre-training on open-source satellite object detection datasets would be necessary to further improve the performance of the final model.
In this blog, we quantify the impact of pre-training on the DOTA 2 dataset [3], an open-source aerial imagery dataset for object detection, on the quality of a commercial satellite object detection model Palantir trained on a smaller labeled dataset. We’re publishing our results here in hopes that they can be used by the wider academic community looking to address similar challenges.
Building our Own Dataset
In order to demonstrate the efficacy of transfer learning for object detection, Palantir has built a labeled dataset for object detection in satellite imagery. The dataset is comprised of EO Satellite imagery from two satellite providers and its detailed characteristics can be seen in Table 1. The training dataset includes approximately 7.5k images (1000×1000 pixels each) sourced from two different commercial satellite providers. In total, we have annotated approximately 130k objects of interest in these images focusing on 3 main classes: vehicles, aircrafts (including helicopters) and ships.
The dataset has been properly split into training and validation datasets to avoid overfitting during training. Our goal is to maximize F1 score for each one of the 3 targeted classes.

As a proxy dataset to the task of object detection in satellite imagery, we leverage DOTA 2, an open-source aerial imagery dataset for object detection [3]. The dataset contains satellite images that were collected from Google Earth, GF-2 and JL-1 satellites, and aerial images provided by CycloMedia B.V. All the images from Google Earth and CycloMedia are RGB, while the images from GF-2 and JL-1 satellites are grayscale.
The DOTA dataset has labeled an extensive list of objects of interest that goes beyond the 3 classes we are targeting in our in-house dataset. We pre-processed the DOTA labels to create a dataset that has the same classes as our internal dataset. We did so by merging all different vehicle, aircraft and ship sub-classes when necessary into a single parent class (vehicle, aircraft and ship) while ignoring the rest of the labeled classes. We pre-trained our models on only these 3 derived parent classes.
Experimental Results
Table 2 shows the per-class F1 score for two different architectures, a traditional Faster-RCNN like model [4] and a more modern transformer-based architecture for object detection [5]. The F1 scores shown are calculated on our internal validation set. Each model was trained twice: once using ImageNet pre-trained weights, and once using pre-trained weights from the DOTA dataset. Pre-training on the DOTA dataset leveraged ImageNet pre-trained weights for initialization.
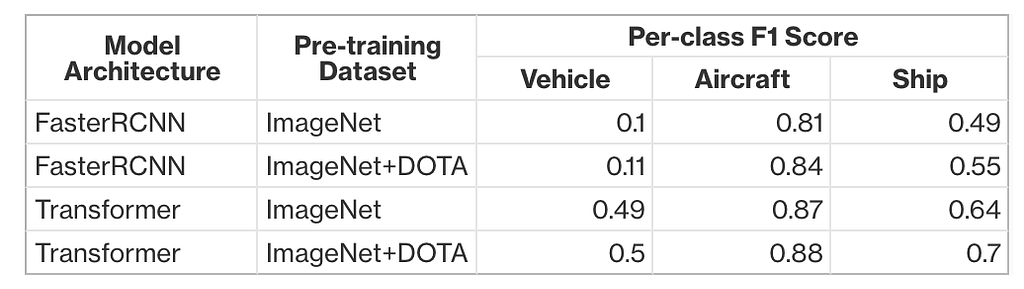
Across both architectures, pre-training on both ImageNet and DOTA consistently achieves higher F1 scores across all classes. In the case of the FasterRCNN architecture, pre-training on DOTA improves F1 scores for vehicle, aircraft and ship by 1%, 3% and 6% respectively. In the case of transformer architectures, we also observe significant, but less dramatic improvement compared to the FasterRCNN architecture, when we leverage DOTA pre-training. In particular, vehicle, aircraft and ship F1 scores increase by 1%, 1% and 6% respectively.
Note that the performance gap can be significantly larger or smaller depending on the quality of the downstream dataset. In this case, we are leveraging a downstream dataset with thousands of images and hundreds of thousands of annotations. For larger datasets, the impact of pre-training might be smaller, and for smaller datasets, the opposite can be true.
The Same Results, Visualized
In order to understand what this looks like in practice, below, we provide a series of visualizations of transformer-based architecture results on Palantir’s internal dataset to underscore the differences in detection. On the left, you’ll see the results of detection based on ImageNet pre-training, while the right reflects both ImageNet and DOTA pre-training. Across all images, the model pre-trained on both ImageNet and DOTA is able to detect more objects of interest more reliably than the model pre-trained on ImageNet only.






Conclusion
Pre-training satellite object detection models on ImageNet or similar open-source object detection datasets has been shown to increase accuracy leading to detection of more objects of interest. In this experiment, we relied on ImageNet pre-trained models, but one can also rely on COCO pre-trained models, or even combinations of these and additional datasets. As demonstrated above, further pre-training of the object detection model on a dataset that is similar to the task we care about is an effective strategy for further improving model performance.
References
[1] Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248–255).
[2] COCO: Common Objects in Context: https://cocodataset.org/#home
[3] DOTA: A Large-Scale Benchmark and Challenges for Object Detection in Aerial Images: https://captain-whu.github.io/DOTA/dataset.html
[4] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems (NIPS).
[5] Dosovitskiy, A., Beyer, L, Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehgani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In 2021 ICLR.
![]()
Transfer Learning was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.