BigQuery’s integrated speech-to-text functionality offers a powerful tool for unlocking valuable insights hidden within audio data. This service transcribes audio files, such as customer review calls, into text format, making them ready for analysis within BigQuery’s robust data platform. By combining speech-to-text with BigQuery’s analytics capabilities, you can delve into customer sentiment, identify recurring product issues, and gain a better understanding of the voice of your customer.
BigQuery speech-to-text transforms audio data into actionable insights, offering potential benefits across industries and enabling a deeper understanding of customer interactions across multiple channels. You can also use BigQuery ML to leverage Gemini 1.0 Pro to gain additional insights & data formatting such as entity extraction and sentiment analysis to the text extracted from audio files using BigQuery ML’s native speech-to-text capability. Below are some use cases and the business value for specific industries:
Using advanced AI features such as BigQuery ML, you still have access to all of the built-in governance features of BigQuery, which give you the ability to have access control passthrough, so you can restrict insights from customer audio files based upon row-level security you have on your BigQuery Object Table.
Ready to turn your audio data into insights? Let’s dive into how you can use speech-to-text in BigQuery:
Imagine you have a collection of customer feedback calls stored as audio files in a Google Cloud Storage bucket. BigQuery’s ML.TRANSCRIBE function, connected to a pre-trained speech-to-text model hosted on Google’s Vertex AI platform, lets you automatically convert these audio files into readable text within BigQuery. Think of it as a specialized translator for audio data. You tell the ML.TRANSCRIBE function where your audio files are located (in your object table) and which speech-to-text model to use. It then handles the transcription process, using the power of machine learning, and delivers the text results directly into BigQuery. This makes it easy to analyze customer conversations alongside other business data.
Let’s walk through the process together in BigQuery.
Setup instructions:
Before starting, choose your Google Cloud project, link a billing account, and enable the necessary API, full instructions here
Create a recognizer, a recognizer stores the configuration for speech recognition and is optional to create
Create a cloud resource connection and get the connection’s service account, full guide here
Grant access to the service account by following the steps here.
Create a dataset that will contain the model and the object table by following the steps here
Download and store the audio files in the Google Cloud Storage
Download 5 audio files from here
Create a bucket in Google Cloud Storage and a folder within the bucket
Upload the downloaded audio files in the folder
Create a model
Create a remote model with a REMOTE_SERVICE_TYPE of CLOUD_AI_SPEECH_TO_TEXT_V2. A model makes the speech to text API available within BigQuery.
Syntax:
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE MODELrn`PROJECT_ID.DATASET_ID.MODEL_NAME`rnREMOTE WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID`rnOPTIONS (rn REMOTE_SERVICE_TYPE = ‘CLOUD_AI_SPEECH_TO_TEXT_V2’,rn SPEECH_RECOGNIZER = ‘projects/PROJECT_NUMBER/locations/LOCATION/recognizers/RECOGNIZER_ID’rn);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09d400>)])]>
Example query:
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE MODELrn`demo_project.speech_to_text_demo_dataset.speech_to_text_bq_model`rnREMOTE WITH CONNECTION `demo_project.us.speech_to_text_demo`rnOPTIONS (rn REMOTE_SERVICE_TYPE = ‘CLOUD_AI_SPEECH_TO_TEXT_V2’rn);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09dc40>)])]>
Create an object table to reference the audio files
Syntax:
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE EXTERNAL TABLE `PROJECT_ID.DATASET_ID.TABLE_NAME`rnWITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID`rnOPTIONS(rn object_metadata = ‘SIMPLE’,rn uris = [‘BUCKET_PATH'[,…]],rn max_staleness = STALENESS_INTERVAL,rn metadata_cache_mode = ‘CACHE_MODE’);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09dca0>)])]>
Sample code:
Please replace 'BUCKET_PATH' with your Google Cloud Storage bucket/folder path where audio files are stored
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE EXTERNAL TABLE `demo_project.speech_to_text_demo_dataset.demo_obj_tb`rnWITH CONNECTION `demo_project.us.speech_to_text_demo`rnOPTIONS(rn object_metadata = ‘SIMPLE’,rn uris = [‘BUCKET_PATH’],rn max_staleness = INTERVAL 1 DAY,rn metadata_cache_mode = ‘AUTOMATIC’);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09dd30>)])]>
Transcribe audio files using BigQuery ML
Syntax:
- code_block
- <ListValue: [StructValue([(‘code’, “SELECT *rnFROM ML.TRANSCRIBE(rn MODEL `PROJECT_ID.DATASET_ID.MODEL_NAME`,rn TABLE `PROJECT_ID.DATASET_ID.OBJECT_TABLE_NAME`,rn RECOGNITION_CONFIG => ( JSON ‘recognition_config’)rn);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09dc10>)])]>
Sample query:
- code_block
- <ListValue: [StructValue([(‘code’, ‘SELECT *rnFROM ML.TRANSCRIBE(rn MODEL `demo_project.speech_to_text_demo_dataset.speech_to_text_bq_model`,rn TABLE `demo_project.speech_to_text_demo_dataset.demo_obj_tb`,rn RECOGNITION_CONFIG =>( JSON ‘{“language_codes”: [“en-US” ],”model”: “telephony”,”auto_decoding_config”: {}}’)rn);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e122c09ddc0>)])]>
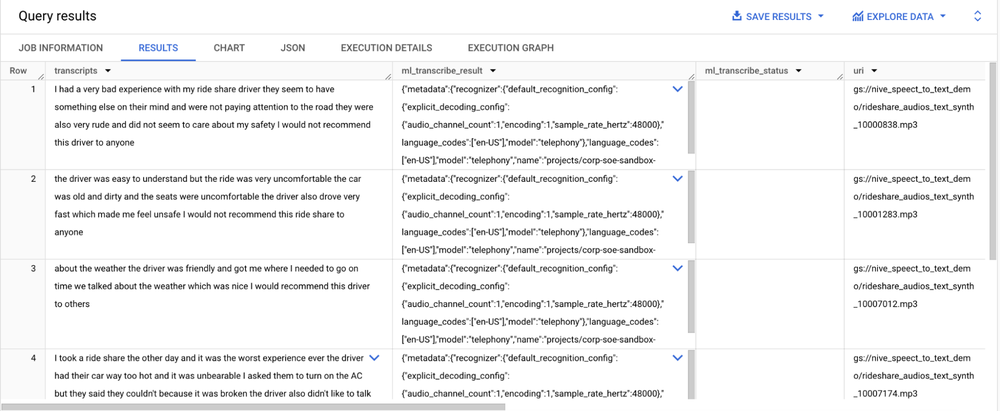
Result:
The results of ML.TRANSCRIBE include these columns:
transcripts: Contains the text transcription of the processed audio files
ml_transcribe_result: JSON value that contains the result from the Speech-to-Text API
ml_transcribe_status: Contains a string value that indicates the success or failure of the transcription process for each row. It will be empty if the process is successful
The object table columns

The ML.TRANSCRIBE function eliminates the need for manual transcription, saving time and effort. Transcribed text becomes easily searchable and analyzable within BigQuery, enabling you to extract valuable insights from your audio data.
Follow-up Ideas
Take the text extracted from the audio files, and use Gemini 1.0 Pro with BigQuery ML’s ML.generate_text function, to extract entities such as product names, stock prices, or other types of entity data you are looking to extract and structure them in JSON.
Use Gemini 1.0 Pro with BigQuery ML to measure sentiment analysis of the extracted text, and structure positive & negative sentiments in JSON.
Join customer feedback verbatims & sentiment scores with Customer Lifetime Total Value score or other relevant customer data to see how quantitative data & qualitative data relate to each other.
Generate embeddings over the extracted text, and use vector search to search the audio files for specific content.
Curious to learn more? The official Google Cloud documentation on ML.TRANSCRIBE has all the details. Please also check out the blog on Gemini 1.0 Pro support for BigQuery ML to see other GenAI use cases as outlined in the Follow-up ideas.