The rise of generative AI has brought forth exciting possibilities, but it also has its limitations. Large language models (LLMs), the workhorses of generative AI, often lack access to specific data and real-time information, which can hinder their performance in certain scenarios. Retrieval augmented generation (RAG) is a technique within natural language processing that uses a two-step process to provide more informative and accurate answers. First, relevant documents or data points are retrieved from a larger dataset based on their similarity to the posed question. Then, a generative language model uses this retrieved information to formulate its response. As such, RAG comes in very handy in data analytics, leveraging vector search in datastores like BigQuery to enhance LLM capabilities. Add to that functionality found in BigQuery ML, and you can do all of this from a single platform, without moving any data!
In this blog, we take a deeper look at LLMs and how RAG can help improve their results, as well as the basics of how RAG works. We then walk you through an example of using RAG and vector search inside BigQuery, to show the power of these technologies working together.
The trouble with LLMs
LLMs work have a lot of general knowledge and can answering general questions, as they are usually trained on a massive corpus of publicly available data. However, unless the model has been trained on a specific domain or discipline, they have limited domain knowledge. This limits their ability to generate relevant and accurate responses in specialized contexts. In addition, since they are trained on static datasets, they lack real-time information, making them unaware of recent events or updates. This can lead to outdated and inaccurate responses. Furthermore,
in many enterprise use cases, it’s crucial to understand the source of information used by LLMs to generate responses. LLMs often struggle to provide citations for their outputs, making it difficult to verify their accuracy and trustworthiness.
How RAG can help
Simply put, RAG equips large language models (LLMs) with external knowledge. Instead of relying solely on their training data, LLMs can access and reference relevant information from external sources like databases or knowledge graphs. This leads to more accurate, reliable, and contextually relevant responses.
RAG shines when working with massive datasets, especially when you can’t fit an entire corpus into a standard language model’s context window due to length limitations. RAG injects additional supporting information into a prompt, leveraging data from multiple types of sources, effectively augmenting LLMs with an information retrieval system. The key to RAG lies in the retrieval query. This query determines how the LLM fetches relevant information from the external knowledge source.
Vector search is a powerful technique for finding similar items within large datasets based on their semantic meaning rather than exact keyword matches. It leverages machine learning models to convert data (like text, images, or audio) into high-dimensional numerical vectors called embeddings. These embeddings capture the semantic essence of the data, allowing BigQuery to efficiently search for similar items by measuring the distance between their vectors. As a result, vector search plays a crucial role in efficiently retrieving relevant information. By converting text and data into vectors, we can find similar pieces of information based on their proximity in the vector space a high-dimensional mathematical representation where each data point (like a piece of text, image, or audio) is encoded as a numerical vector, also known as an embedding. These vectors capture the semantic meaning and relationships between data points, allowing BigQuery to perform similarity searches based on the proximity of vectors within this space. This allows the LLM to quickly identify the most relevant documents or knowledge graph nodes related to the user’s query, leading to more accurate, reliable, and contextually relevant responses.
RAG basics
As mentioned earlier RAG is a technique within natural language processing that uses a two-step process to retrieve relevant information from a knowledge base, followed by a generative model that synthesizes answers based on this information, thereby providing more informative and accurate responses. A RAG system is usually broken down into two major parts, each with two components:
Retrieve and select: Employ semantic search to pinpoint the most relevant portions of your large dataset based on the query. This can be done via:
Vector search:
Your data (documents, articles, etc.) is converted into vectors, mathematical representations capturing their semantic meaning.
These vectors are stored in a specialized database like BigQuery, optimized for vector similarity search.
Querying:
When a user submits a query, it is also converted into a vector.
The vector search engine then compares this query vector to the stored document vectors, identifying the most similar documents based on their semantic closeness.
Augment and answer: Feed the extracted relevant parts to the language model, enhancing its answer generation process.
3. Augmenting the prompt:
The most relevant documents retrieved through vector search are appended to the original user query, creating an augmented prompt.
This augmented prompt, containing both the user query and relevant contextual information, is fed to the LLM.
4. Enhanced response generation:
With access to additional context, the LLM can now generate more accurate, relevant, and informed responses.
Additionally, the retrieved documents can be used to provide citations and source transparency for the generated outputs.
RAGs challenges
Given the number of moving parts, traditionally RAG systems require a number of frameworks and applications to come together. There are many RAG implementations and most of these stay as POCs or MVPs, given how daunting a task it is to meet all the challenges above. Solutions often end up being too convoluted and challenging to manage, undermining organizations’ confidence in bringing it into production within enterprise systems. You can end up needing an entire team to manage RAG across multiple systems, each of them with different owners, etc.!
BigQuery to the rescue
BigQuery simplifies RAG in a number of ways: its ability to do vector search, querying the data and the vector, augmenting the prompt and then enhancing response generation — all within the same data platform. You can apply the same access rules across the RAG system, or in different parts of it in a straightforward fashion. You can join the data, whether it is coming from your core enterprise data platform, e.g., BigQuery, or if it is coming from vector search through BigQuery and an LLM. This means security and governance are maintained, and that you don’t lose control of access policies. Furthermore, when complemented with BigQuery ML, you can get to production with less than 50 lines of code.
In short, using RAG with BigQuery vector search and with BigQuery ML offers several benefits:
Improved accuracy and relevance: By providing LLMs with relevant context, RAG significantly improves the accuracy and relevance of generated responses. Users can augment the knowledge within the LLMs with their enterprise data without data leaving the system they are operating in.
Real-time information access: Vector search allows LLMs to access and utilize real-time information, ensuring that responses are up-to-date and reflect the latest knowledge.
Source transparency: The retrieved documents can be used to provide citations and source information, enhancing the trustworthiness and verifiability of LLM outputs.
Scalability and efficiency: BigQuery offers a scalable and efficient platform for storing and searching large volumes of vectorized data, making it ideal for supporting RAG workflows.
RAG in action
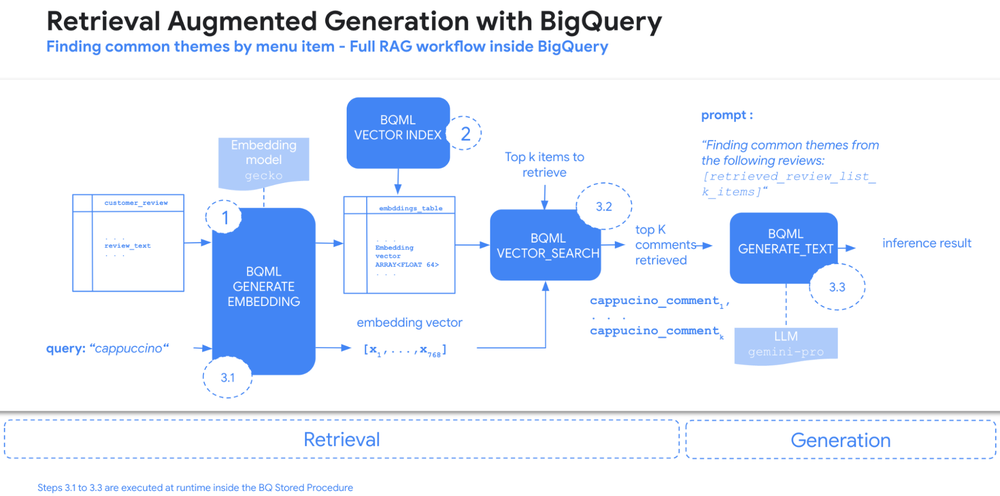
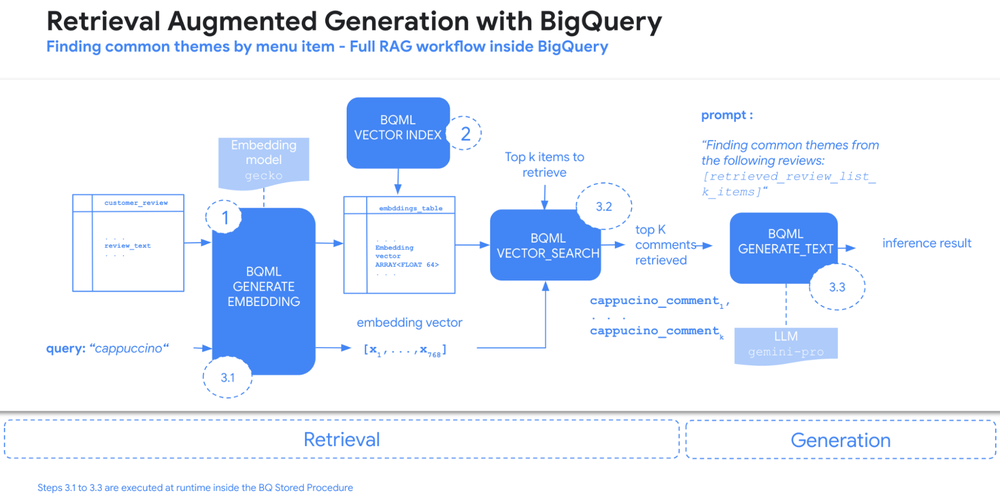
Lets showcase the integration of RAG and vector search within BigQuery with a pipeline that extracts common themes from product reviews for Data Beans, a fictional coffee franchise that we have used in previous demos. This process has three main stages:
Generating embeddings: BigQuery ML’s text embedding model generates vector representations for each customer review.
Vector index creation: A vector index is created in the embedding column for efficient retrieval.
RAG pipeline execution, with the runtime inside a BigQuery stored procedure
3.1 Query embedding: The user’s query, such as “cappuccino,” is also converted into a vector representation using the same embedding model.
3.2 Vector search: BigQuery’s vector search functionality identifies the top K reviews that are most similar to the query based on their vector representations.
3.3 Theme extraction with Gemini: The retrieved reviews are then fed into Gemini, which extracts the common themes and presents them to the user.
You can find more about the Data Beans demo here.
In this example below, we have customer reviews as text within the BigQuery table. Customer reviews are free text by definition, but what if we were to try to extract the common themes for each of our menu items, for example common feedback about the cappuccino and the espresso?

This problem requires some data from enterprise data platform, products and combines it with text information coming directly from customer interactions; each of the menu items are stored in a BigQuery table. This problem is a good candidate for RAG within BigQuery, and can be solved in just three steps.
Step 1 – We start by generating the embeddings directly within BigQuery using the ML.GENERATE_TEXT_EMBEDDING function. This lets us embed text that’s stored in BigQuery tables; in other words, we are creating a dense vector representation of a piece of text. For example, if two pieces of text are semantically similar, then their respective embeddings are located near each other in the embedding vector space.
- code_block
- <ListValue: [StructValue([(‘code’, ‘CREATE OR REPLACE TABLE `rndata_beans.customer_review_embedded`rnasrnSELECT *rnFROMrn ML.GENERATE_TEXT_EMBEDDING(rn MODEL `rndata_beans.gecko_embedding_model`,rn (select review_text as content from `rndata_beans.customer_review` )rn);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e2f275bd280>)])]>
Step 2 – Once we have the embedding table we can generate a vector index with the CREATE OR REPLACE VECTOR INDEX statements in BigQuery.
- code_block
- <ListValue: [StructValue([(‘code’, “CREATE OR REPLACE VECTOR INDEX `data_beans.reviews_index`rnON `data_beans.customer_review_embedded`(text_embedding)rnOPTIONS(distance_type=’COSINE’, index_type=’IVF’);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e2f275bd070>)])]>
Step 3 – In the final step, we write the RAG logic and wrap everything into a BigQuery stored procedure. By combining vector search, query embedding and extracting the themes in a single stored procedure, RAG can be implemented in less than 20 lines of SQL. This allows us to pass the terms that we would like to retrieve into BigQuery through a single function call:
- code_block
- <ListValue: [StructValue([(‘code’, ‘CREATE OR REPLACE PROCEDURE data_beans.common_themes_by_item_type(item STRING, OUT themes STRING)rnBEGINrn–Step 3.3 Augmentation subqueryrnSELECTrn ml_generate_text_llm_result AS generatedrnFROMrn ML.GENERATE_TEXT( MODEL `data_beans.gemini_llm_model`,rn (rn SELECTrn CONCAT(‘Extract common themes from the following reviews: ‘, STRING_AGG(FORMAT(“review text: %s”, base.content), ‘,\n’)) AS prompt,rn FROMrn–Step 3.2 Retrieval sub queryrn VECTOR_SEARCH( TABLE `data_beans.customer_review_embedded`,rn ‘text_embedding’,rn (rn SELECTrn text_embedding,rn content AS queryrn FROMrn–Step 3.1 Embedding of our query (e.g. cappuccino)rn ML.GENERATE_TEXT_EMBEDDING( MODEL `data_beans.emb_model`,rn (rn SELECTrn CAST(item AS STRING) AS content)) ),rn top_k => 5) ),rn STRUCT(0.4 AS temperature,rn 300 AS max_output_tokens,rn 0.5 AS top_p,rn 5 AS top_k,rn TRUE AS flatten_json_output));rnEND’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e2f275bde50>)])]>
Finally we can call our procedure and get the results back:
- code_block
- <ListValue: [StructValue([(‘code’, “DECLARE themes STRING;rnCALL data_beans.common_themes_by_item_type(‘cappuccino’,themes);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e2f275bd370>)])]>
With this approach, data always stays within a single environment, and teams do not need to manage a number of application frameworks.

This example demonstrates how to perform RAG entirely within BigQuery, leveraging its built-in capabilities for text embedding, vector search, and generative AI. To summarize the technical aspects of the de,o:
Text embedding: BigQuery ML’s ML.GENERATE_TEXT_EMBEDDINGS was used to generate text embedding vectors for customer reviews.
Vector index: We created a vector index on the embedding column for efficient similarity search.
RAG implementation: A stored procedure was created to encapsulate the entire RAG process, including query embedding, vector search, and generation using Gemini.
Takeaways
BigQuery offers a powerful and unified platform for implementing RAG, eliminating the need for complex multi-service architectures.
Vector indexes enable efficient similarity search within BigQuery, facilitating effective retrieval of relevant information.
Stored procedures can streamline and automate complex AI processes within BigQuery.
Conclusions and resources
RAG, combined with vector search and BigQuery, offers a powerful solution for overcoming the limitations of LLMs, allowing them to access domain-specific knowledge, real-time information, and source transparency, and paving the way for more accurate, relevant, and trustworthy generative AI applications. By leveraging this powerful trio, businesses can unlock the full potential of generative AI and develop innovative solutions across various domains.
And while larger context windows in LLMs like Gemini may reduce the need for RAG in some cases, RAG remains essential for handling massive or specialized datasets, and providing up-to-date information. Hybrid approaches combining both may offer the best of both worlds, depending on specific use cases and cost-benefit tradeoffs.
To learn more about BigQuery’s new RAG and vector search features, check out the documentation. Use this tutorial to apply Google’s best-in-class AI models to your data, deploy models and operationalize ML workflows without moving data from BigQuery. You can also watch a demonstration on how to build an end-to-end data analytics and AI application directly from BigQuery while harnessing the potential of advanced models like Gemini.
Googlers Adam Paternostro, Navjot Singh, Skander Larbi and Manoj Gunti contributed to this blog post. Many Googlers contributed to make these features a reality.