
Training large language models (LLMs) with billions of parameters can be challenging. In addition to designing the model architecture, researchers need to set up state-of-the-art training techniques for distributed training like mixed precision support, gradient accumulation, and checkpointing. With large models, the training setup is even more challenging because the available memory in a single accelerator device bounds the size of models trained using only data parallelism, and using model parallel training requires additional level of modifications to the training code. Libraries such as DeepSpeed (an open-source deep learning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training.
In this post, we set up training on the Intel Habana Gaudi-based Amazon Elastic Compute Cloud (Amazon EC2) DL1 instances and quantify the benefits of using a scaling framework such as DeepSpeed. We present scaling results for an encoder-type transformer model (BERT with 340 million to 1.5 billion parameters). For the 1.5-billion-parameter model, we achieved a scaling efficiency of 82.7% across 128 accelerators (16 dl1.24xlarge instances) using DeepSpeed ZeRO stage 1 optimizations. The optimizer states were partitioned by DeepSpeed to train large models using the data parallel paradigm. This approach has been extended to train a 5-billion-parameter model using data parallelism. We also used Gaudi’s native support of the BF16 data type for reduced memory size and increased training performance compared to using the FP32 data type. As a result, we achieved pre-training (phase 1) model convergence within 16 hours (our target was to train a large model within a day) for the BERT 1.5-billion-parameter model using the wikicorpus-en dataset.
Training setup
We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. Each dl1.24xlarge instance has eight Habana Gaudi accelerators, each with 32 GB of memory and a full mesh RoCE network between cards with a total bi-directional interconnect bandwidth of 700 Gbps each (see Amazon EC2 DL1 instances Deep Dive for more information). The dl1.24xlarge cluster also used four AWS Elastic Fabric Adapters (EFA), with a total of 400 Gbps interconnect between nodes.
The distributed training workshop illustrates the steps to set up the distributed training cluster. The workshop shows the distributed training setup using AWS Batch and in particular, the multi-node parallel jobs feature to launch large-scale containerized training jobs on fully managed clusters. More specifically, a fully managed AWS Batch compute environment is created with DL1 instances. The containers are pulled from Amazon Elastic Container Registry (Amazon ECR) and launched automatically into the instances in the cluster based on the multi-node parallel job definition. The workshop concludes by running a multi-node, multi-HPU data parallel training of a BERT (340 million to 1.5 billion parameters) model using PyTorch and DeepSpeed.
BERT 1.5B pre-training with DeepSpeed
Habana SynapseAI v1.5 and v1.6 support DeepSpeed ZeRO1 optimizations. The Habana fork of the DeepSpeed GitHub repository includes the modifications necessary to support the Gaudi accelerators. There is full support of distributed data parallel (multi-card, multi-instance), ZeRO1 optimizations, and BF16 data types.
All these features are enabled on the BERT 1.5B model reference repository, which introduces a 48-layer, 1600-hidden dimension, and 25-head bi-directional encoder model, derived from a BERT implementation. The repository also contains the baseline BERT Large model implementation: a 24-layer, 1024-hidden, 16-head, 340-million-parameter neural network architecture. The pre-training modeling scripts are derived from the NVIDIA Deep Learning Examples repository to download the wikicorpus_en data, preprocess the raw data into tokens, and shard the data into smaller h5 datasets for distributed data parallel training. You can adopt this generic approach to train your custom PyTorch model architectures using your datasets using DL1 instances.
Pre-training (phase 1) scaling results
For pre-training large models at scale, we mainly focused on two aspects of the solution: training performance, as measured by the time to train, and cost-effectiveness of arriving at a fully converged solution. Next, we dive deeper into these two metrics with BERT 1.5B pre-training as an example.
Scaling performance and time to train
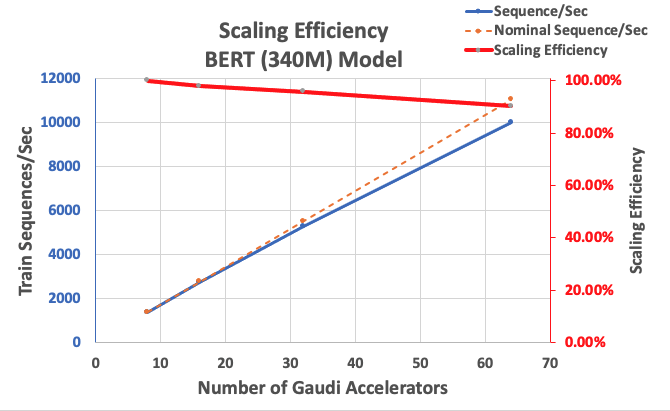
We start by measuring the performance of the BERT Large implementation as a baseline for scalability. The following table lists the measured throughput of sequences per second from 1-8 dl1.24xlarge instances (with eight accelerator devices per instance). Using the single-instance throughput as baseline, we measured the efficiency of scaling across multiple instances, which is an important lever to understand the price-performance training metric.
| Number of Instances | Number of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Efficiency |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
The following figure illustrates the scaling efficiency.
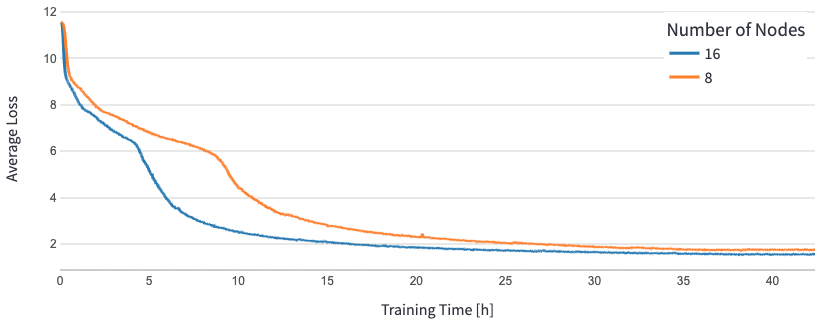
For BERT 1.5B, we modified the hyperparameters for the model in the reference repository to guarantee convergence. The effective batch size per accelerator was set to 384 (for maximum memory utilization), with micro-batches of 16 per step and 24 steps of gradient accumulation. Learning rates of 0.0015 and 0.003 were used for 8 and 16 nodes, respectively. With these configurations, we achieved convergence of the phase 1 pre-training of BERT 1.5B across 8 dl1.24xlarge instances (64 accelerators) in approximately 25 hours, and 15 hours across 16 dl1.24xlarge instances (128 accelerators). The following figure shows the average loss as a function of number of training epochs, as we scale up the number of accelerators.
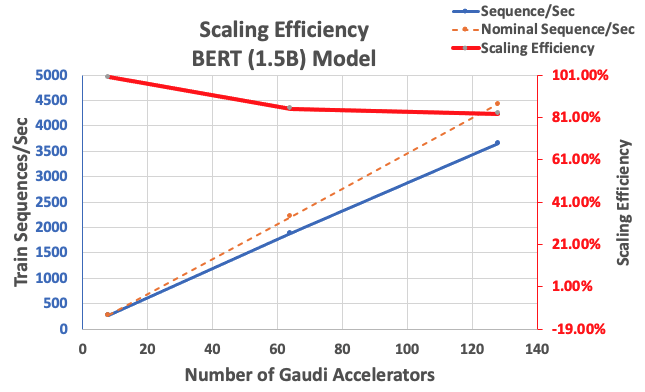
With the configuration described earlier, we obtained 85% strong scaling efficiency with 64 accelerators and 83% with 128 accelerators, from a baseline of 8 accelerators in a single instance. The following table summarizes the parameters.
| Number of Instances | Number of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Efficiency |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
The following figure illustrates the scaling efficiency.
Conclusion
In this post, we evaluated support for DeepSpeed by Habana SynapseAI v1.5/v1.6 and how it helps scale LLM training on Habana Gaudi accelerators. Pre-training of a 1.5-billion-parameter BERT model took 16 hours to converge on a cluster of 128 Gaudi accelerators, with 85% strong scaling. We encourage you to take a look at the architecture demonstrated in the AWS workshop and consider adopting it to train custom PyTorch model architectures using DL1 instances.
About the authors
 Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics-infused deep learning, building, and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics-infused deep learning, building, and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
 RJ is an engineer in Search M5 team leading the efforts for building large scale deep learning systems for training and inference. Outside of work he explores different cuisines of food and plays racquet sports.
RJ is an engineer in Search M5 team leading the efforts for building large scale deep learning systems for training and inference. Outside of work he explores different cuisines of food and plays racquet sports.
 Sundar Ranganathan is the Head of Business Development, ML Frameworks on the Amazon EC2 team. He focuses on large-scale ML workloads across AWS services like Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
Sundar Ranganathan is the Head of Business Development, ML Frameworks on the Amazon EC2 team. He focuses on large-scale ML workloads across AWS services like Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
 Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference.
Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference.
 Pierre-Yves Aquilanti is Head of Frameworks ML Solutions at Amazon Web Services where he helps develop the industry’s best cloud based ML Frameworks solutions. His background is in High Performance Computing and prior to joining AWS, Pierre-Yves was working in the Oil & Gas industry. Pierre-Yves is originally from France and holds a Ph.D. in Computer Science from the University of Lille.
Pierre-Yves Aquilanti is Head of Frameworks ML Solutions at Amazon Web Services where he helps develop the industry’s best cloud based ML Frameworks solutions. His background is in High Performance Computing and prior to joining AWS, Pierre-Yves was working in the Oil & Gas industry. Pierre-Yves is originally from France and holds a Ph.D. in Computer Science from the University of Lille.