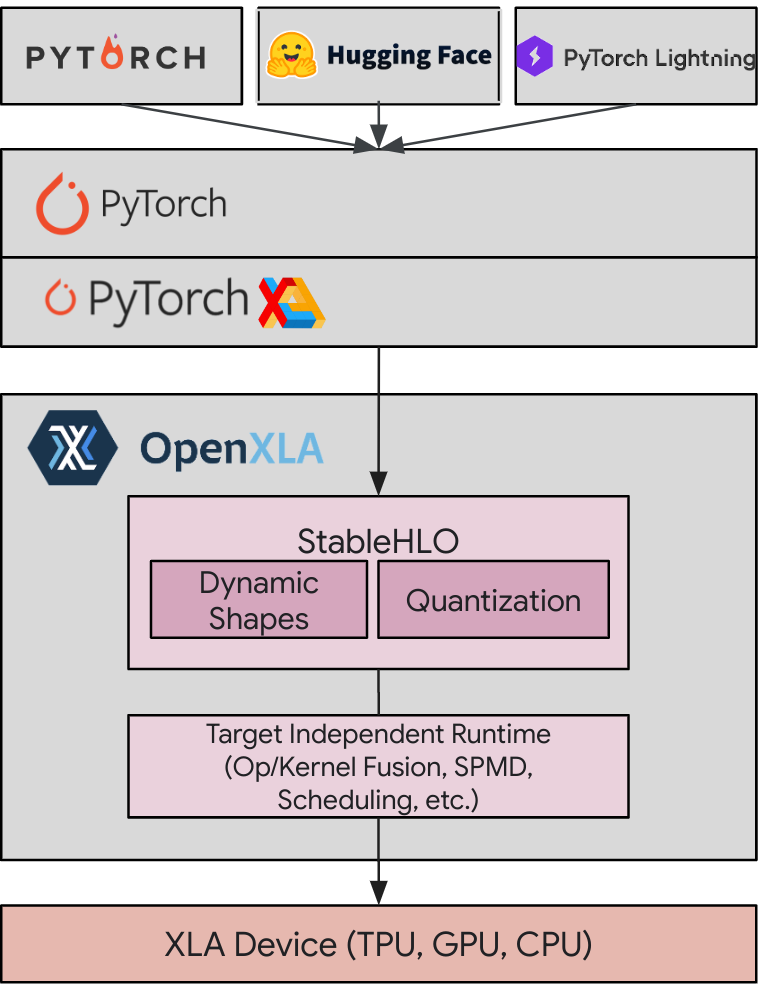
PyTorch’s flexibility and dynamic nature make it a popular choice for deep learning researchers and practitioners. Developed by Google, XLA is a specialized compiler designed to optimize linear algebra computations – the foundation of deep learning models. PyTorch/XLA offers the best of both worlds: the user experience and ecosystem advantages of PyTorch, with the compiler performance of XLA.
PyTorch/XLA stack diagram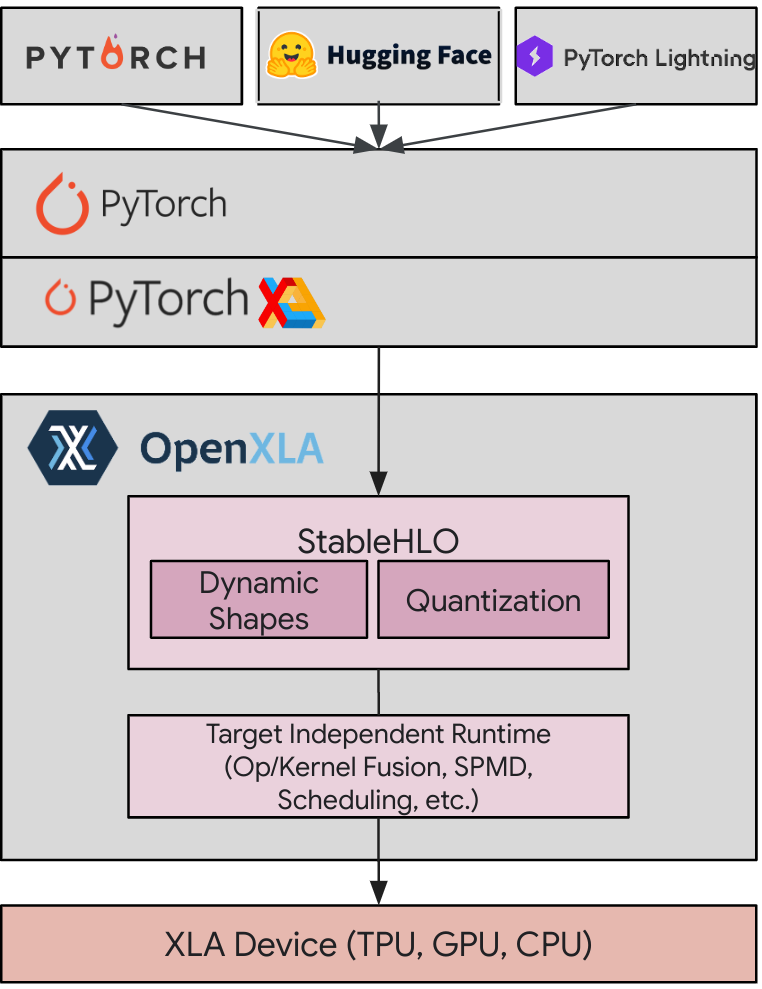
We are excited to launch PyTorch/XLA 2.3 this week. The 2.3 release brings with it even more productivity, performance and usability improvements.
Why PyTorch/XLA?
Before we get into the release updates, here’s a short overview of why PyTorch/XLA is great for model training, fine-tuning and serving. The combination of PyTorch and XLA provides key advantages:
Easy Performance: Retain PyTorch’s intuitive, pythonic flow while gaining significant and easy performance improvements through the XLA compiler. For example, PyTorch/XLA produces a throughput of 5000 tokens/second while finetuning Gemma and Llama 2 7B models and reduces the cost of serving down to $0.25 per million tokens.
Ecosystem advantage: Seamlessly access PyTorch’s extensive resources, including tools, pretrained models, and its large community.
These benefits underscore the value of PyTorch/XLA. Lightricks shares the following feedback on their experience with PyTorch/XLA 2.2:
“By leveraging Google Cloud’s TPU v5p, Lightricks has achieved a remarkable 2.5X speedup in training our text-to-image and text-to-video models compared to TPU v4. With the incorporation of PyTorch XLA’s gradient checkpointing, we’ve effectively addressed memory bottlenecks, leading to improved memory performance and speed. Additionally, autocasting to bf16 has provided crucial flexibility, allowing certain parts of our graph to operate on fp32, optimizing our model’s performance. The XLA cache feature, undoubtedly the highlight of PyTorch XLA 2.2, has saved us significant development time by eliminating compilation waits. These advancements have not only streamlined our development process, making iterations faster but also enhanced video consistency significantly. This progress is pivotal in keeping Lightricks at the forefront of the generative AI sector, with LTX Studio showcasing these technological leaps.” – Yoav HaCohen, Research team lead, Lightricks
What’s in the 2.3 release: Distributed training, dev experience, and GPUs
PyTorch/XLA 2.3 keeps us current with PyTorch Foundation’s 2.3 release from earlier this week, and offers notable upgrades from PyTorch/XLA 2.2. Here’s what to expect:
1. Distributed training improvements
SPMD with FSDP: Fully Sharded Data Parallel (FSDP) support enables you to scale large models. The new Single Program, Multiple Data (SPMD) implementation in 2.3 integrates compiler optimizations for faster, more efficient FSDP.
Pallas integration: For maximum control, PyTorch/XLA + Pallas lets you write custom kernels specifically tuned for TPUs.
2. Smoother development
- SPMD auto-sharding: SPMD automates model distribution across devices. Auto-sharding further simplifies this process, eliminating the need for manual tensor distribution. In this release, this feature is experimental, supporting XLA:TPU and single-host training.
PyTorch/XLA autosharding architecture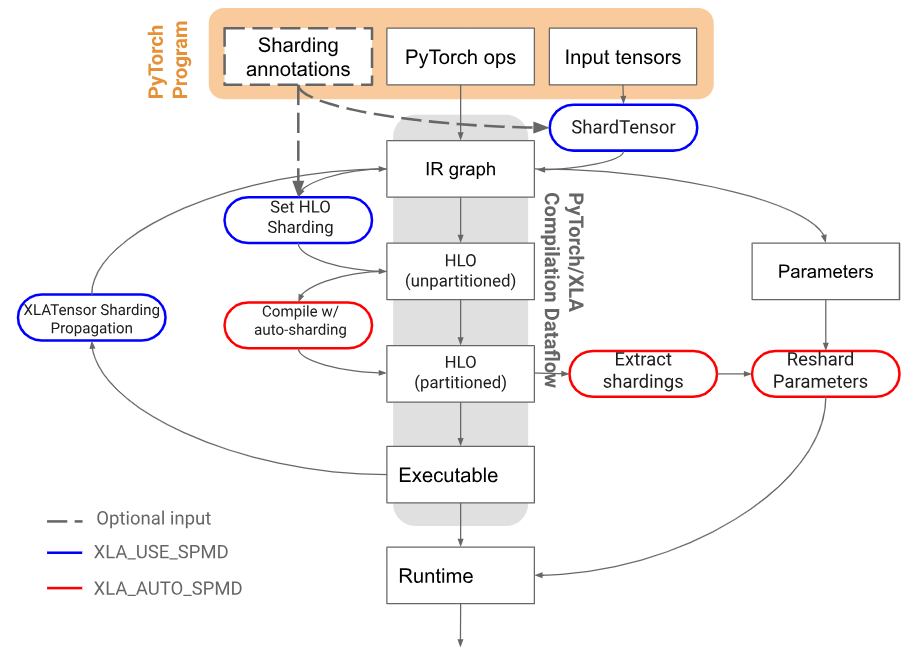
Distributed checkpointing: This makes long training sessions less risky. Asynchronous checkpointing saves your progress in the background, protecting against potential hardware failures.
3. Hello, GPUs!
SPMD XLA: GPU support: We have extended the benefits of SPMD parallelization to GPUs, making scaling easier, especially when handling large models or datasets.
Start planning your upgrade
PyTorch/XLA continues to evolve, streamlining the creation and deployment of powerful deep learning models. The 2.3 release emphasizes improved distributed training, a smoother development experience, and broader GPU support. If you’re in the PyTorch ecosystem and seeking performance optimization, PyTorch/XLA 2.3 is worth exploring!
Stay up-to-date, find installation instructions or get support on the official PyTorch/XLA repository on GitHub: https://github.com/pytorch/xla
PyTorch/XLA is also well-integrated into the AI Hypercomputer stack that optimizes AI training, fine-tuning and serving performance end-to-end at every layer of the stack:
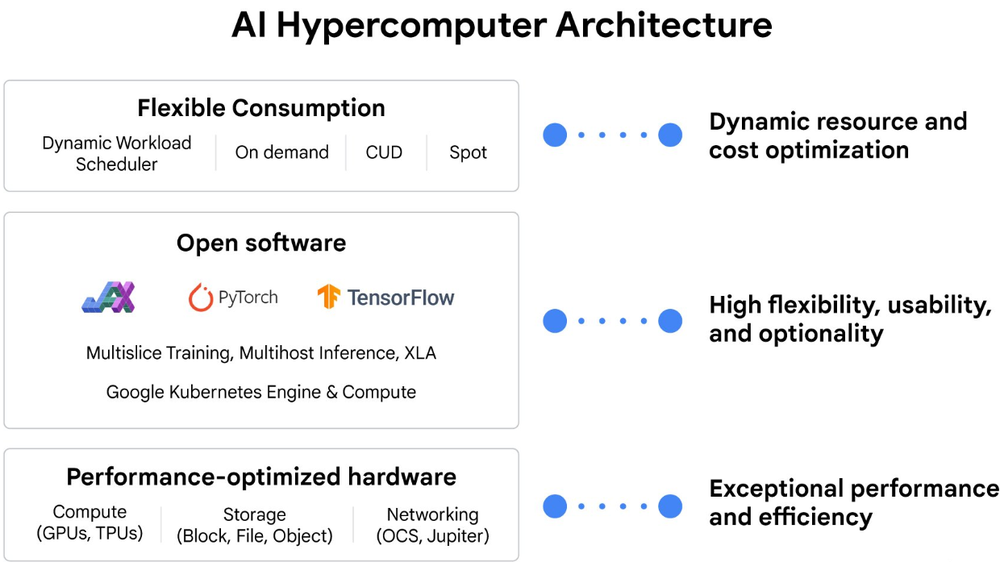
Ask your sales representative about how you can apply these capabilities within your own organization.