Large language model (LLM) training has become increasingly popular over the last year with the release of several publicly available models such as Llama2, Falcon, and StarCoder. Customers are now training LLMs of unprecedented size ranging from 1 billion to over 175 billion parameters. Training these LLMs requires significant compute resources and time as hundreds to thousands of graphics processing units (GPUs) must be used to handle today’s vast training datasets and model sizes. One bottleneck in distributed training can be GPU communication handled by the NVIDIA Collective Communication Library (NCCL). In some large-distributed training jobs, more time can be spent on inter-GPU communication than actual GPU computation. To alleviate the GPU communication bottleneck and enable faster training, Amazon SageMaker is excited to announce an optimized AllGather collective operation as part of the SageMaker distributed data parallel library (SMDDP). AllGather is the most used collective operation in popular memory-efficient data parallelism solutions like DeepSpeed Zero Redundancy Optimizer (ZeRO) and Fully Sharded Data Parallelism (FSDP), and it is the main contributor to GPU communication overhead. In this post, we show a high-level overview of how SMDDP works, how you can enable SMDDP in your Amazon SageMaker training scripts, and the performance improvements you can expect.
Solution overview
Traditional data parallel training involves replicating an entire model across multiple GPUs, with each model training on different shards of data from the dataset. During the backward pass, gradients are averaged among GPU workers so that each model replica is updated with the same gradient values despite them being trained with different data shards. This technique allows much faster training on vast datasets by parallelizing the consumption of training data. However, some of today’s large models (e.g., Llama2 70B) are far too large to fit entirely within GPU memory, which makes traditional data parallelism unusable. To continue reaping the benefits of data parallelism while overcoming limited GPU memory, sharded data parallel solutions such as DeepSpeed ZeRO, PyTorch FSDP, and the Amazon SageMaker model parallelism library have grown in popularity.
In sharded data parallelism, rather than replicating the entire model on GPU workers, the model parameters, gradients, and optimizer states are broken up and distributed (i.e., sharded) across GPUs in the training job. To perform forward and backward pass computation, parameters are gathered from shards on other GPU workers to form one or more model layers. After computation is performed, these layers are then freed from memory to allow for the next set of layers to be gathered. Note that there are variants of sharded data parallelism where only the optimizer states and gradients are sharded, but not the model parameters. AllGather is still used in this type of sharded data parallelism, but only prior to forward pass computation in order to gather model parameters that have been updated by different gradient or optimizer state shards from other GPU workers. Refer to the different DeepSpeed ZeRO stages and the SHARD_GRAD_OP FSDP sharding strategy for more detail.
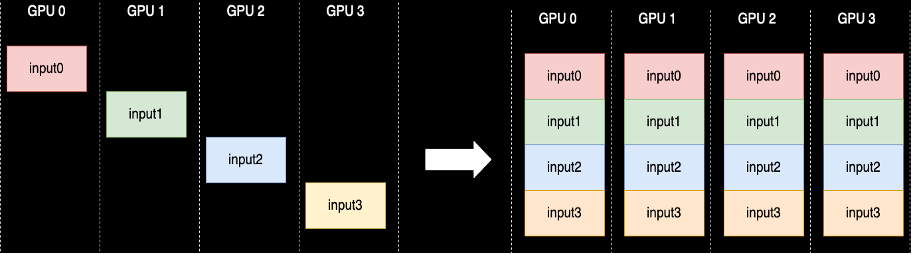
An AllGather collective operation is performed each time parameters are unsharded—NCCL provides the standard open-source implementation of this routine. As shown in the following, each GPU worker involved in the AllGather starts off with an input buffer and ends up with all of the input buffers from other workers concatenated together. When AllGather is used in sharded data parallelism, the input buffers contain the model parameter shards and the large output buffers contain one or more model layers materialized from the other shards.

Although NCCL is typically used for AllGather in distributed training, its underlying low-level implementation isn’t tailored to the networking infrastructure of Amazon Elastic Compute Cloud (Amazon EC2) instances, and thus its performance can slow down end-to-end training. The SMDDP library is a collective communication library for NVIDIA GPUs that serves as a drop-in replacement for NCCL and provides better performance for distributed training jobs with PyTorch. Specifically, SMDDP provides an optimized implementation of AllGather for p4d/p4de instance types.
Since collective operations like AllGather block forward and backward pass computation, faster execution of these operations directly translates into shorter end-to-end training time with no side effects on convergence. Other collective operations that’re used less frequently in sharded data parallel training are handled by falling back to NCCL.
Walkthrough
AWS-optimized AllGather
AWS-optimized AllGather uses the following techniques to achieve better performance on AWS infrastructure compared to NCCL:
- We move data between instances via Elastic Fabric Adapter (EFA) network with an all-to-all communication pattern. EFA is AWS’s low-latency and high-throughput network solution, and an all-to-all pattern for inter-node network communication is more tailored to the characteristics of EFA and AWS’ network infrastructure by requiring fewer packet hops compared to NCCL’s ring or tree communication pattern.
- GDRCopy to coordinate local NVLink and EFA network traffic. GDRCopy is a library that provides low-latency communication between CPU processes and GPU CUDA kernels. With this technology, we’re able to pipeline the intra-node and inter-node data movement.
- Reduced usage of GPU streaming multiprocessors to give back more compute power to model kernels. AWS P4d/P4de instances are equipped with NVIDIA A100 GPUs each of which has 108 streaming multiprocessors. While NCCL takes up to 24 streaming multiprocessors to execute collectives, SMDDP Collectives only use up to nine streaming multiprocessors. The saved streaming multiprocessors can be picked up by model compute kernels for quicker execution.
Usage
SMDDP collectives natively integrates with PyTorch through the process group abstraction in the torch.distributed module. A process group defines the interfaces for common collective operations such as AllGather, ReduceScatter, AllReduce, etc. Users can write generic distributed code and then choose the underlying backend, which provides the implementation for these operations based on the compute device used. CPU training jobs often use the gloo or mpi backend while NVIDIA GPUs use the nccl backend.
The SMDDP library comes into the picture by registering itself as a custom backend in the process group abstraction. This is done by the import statement, which is shown in the following code snippets. Then, when selecting the backend for your GPU-based distributed training job, just replace nccl with smddp. The smddp backend abides by the same semantics as the nccl backend and supports the same training scenarios.
DeepSpeed
import smdistributed.dataparallel.torch.torch_smddp
deepspeed.init_distributed(dist_backend="smddp") # replacing "nccl"
FSDP
import smdistributed.dataparallel.torch.torch_smddp
dist.init_process_group(backend="smddp") # replacing "nccl"Benchmarks
We benchmarked standalone AllGather performance where the collective operation is run in isolation without any model training. Below is a sample result on 32 p4d instances comparing NCCL and SMDDP AllGather. The X-axis represents the output size of AllGather, and the Y-axis represents the network utilization rate of p4d’s 400 Gbps EFA network. The 4 sub-graphs represent the common communication group patterns where we have 1, 2, 4, and 8 ranks per p4d instance participating in the AllGather operation, respectively.

These microbenchmarks show that SMDDP outperforms NCCL with two key characteristics:
- The peak performance of SMDDP (approximately 90% bandwidth utilization) is higher than that of NCCL (approximately 80% bandwidth utilization) in all configurations.
- SMDDP reaches the peak performance at much smaller buffer sizes than NCCL. This particularly improves training speeds for smaller models or when the user sets a small AllGather buffer size in DeepSpeed (where AllGather size need not be equal to layer size).
Model training benchmarks
In large-scale training jobs where GPU communication is a significant bottleneck, SMDDP can markedly improve training speeds, as measured by model TFLOPS/GPU.
| Configuration | Performance | ||||
| Model/Training | Cluster | Sharded Data Parallelism Solution | Model TFLOPS/GPU with NCCL | Model TFLOPS/GPU with SMDDP | % speedup |
| 13B Llama2 Seq length: 4096 Global batch size: 4M tokens | 64 p4d.24xlarge nodes (512 NVIDIA A100 GPUs) | PyTorch FSDP | 97.89 | 121.85 | 24.40% |
| 65B GPT-NeoX Seq length: 2048 Global batch size: 4M tokens | 64 p4d.24xlarge nodes (512 NVIDIA A100 GPUs) | DeepSpeed ZeRO Stage 3* | 99.23 | 108.66 | 9.50% |
*EleutherAI’s Megatron-DeepSpeed repository was used. Tensor parallelism was also enabled with a tensor-parallel degree of eight.
Note: Model TFLOPS/GPU is based on the Model FLOPS Utilization calculation defined in the paper here and benchmark figures elsewhere may cite hardware TFLOPS/GPU as the performance metric. Hardware TFLOPS/GPU can be approximated as 4/3 x model TFLOPS/GPU.
Conclusion
In this post, we showed you how to significantly speed up sharded data parallel training jobs on Amazon SageMaker with just two lines of code change. Large-scale distributed training is becoming increasingly ubiquitous with the emergence or LLMs, but with this scale comes high costs. By reducing the communication bottleneck between GPUs, SMDDP helps you train faster at scale and save on compute resources. You can find more SMDDP examples with sharded data parallel training in the Amazon SageMaker Examples GitHub repository.
About the Authors
 Apoorv Gupta is a Software Development Engineer at AWS, focused on building optimal deep learning systems for AWS infrastructure and hardware. He is interested in distributed computing, deep learning systems, and ML accelerators. Outside of work, Apoorv enjoys traveling, hiking, and video games.
Apoorv Gupta is a Software Development Engineer at AWS, focused on building optimal deep learning systems for AWS infrastructure and hardware. He is interested in distributed computing, deep learning systems, and ML accelerators. Outside of work, Apoorv enjoys traveling, hiking, and video games.
 Karan Dhiman is a Software Development Engineer at AWS, based in Toronto, Canada. He is very passionate about the machine learning space and building solutions for accelerating distributed computed workloads.
Karan Dhiman is a Software Development Engineer at AWS, based in Toronto, Canada. He is very passionate about the machine learning space and building solutions for accelerating distributed computed workloads.
 Ruhan Prasad is a Software Development Engineer at AWS who is working on making distributed deep learning training faster, cheaper, and easier to use on SageMaker. Outside of work, Ruhan enjoys playing tennis, traveling, and cooking.
Ruhan Prasad is a Software Development Engineer at AWS who is working on making distributed deep learning training faster, cheaper, and easier to use on SageMaker. Outside of work, Ruhan enjoys playing tennis, traveling, and cooking.
 Zhaoqi Zhu is a Senior Software Development Engineer at AWS, passionate about distributed systems and low level optimizations. He enjoys watching soccer matches while drinking (non-diet) soda.
Zhaoqi Zhu is a Senior Software Development Engineer at AWS, passionate about distributed systems and low level optimizations. He enjoys watching soccer matches while drinking (non-diet) soda.