Typically, data scientists retrain models at regular intervals to keep them fresh and relevant. This practice may turn out to be costly if the model is trained too often or inefficient if the model training isn’t frequent enough to serve the business. Ideally, data scientists prefer to continuously evaluate the models and intentionally retrain models when the model performance starts to degrade. At scale, continuous model evaluation would require a standard and efficient evaluation process and system.
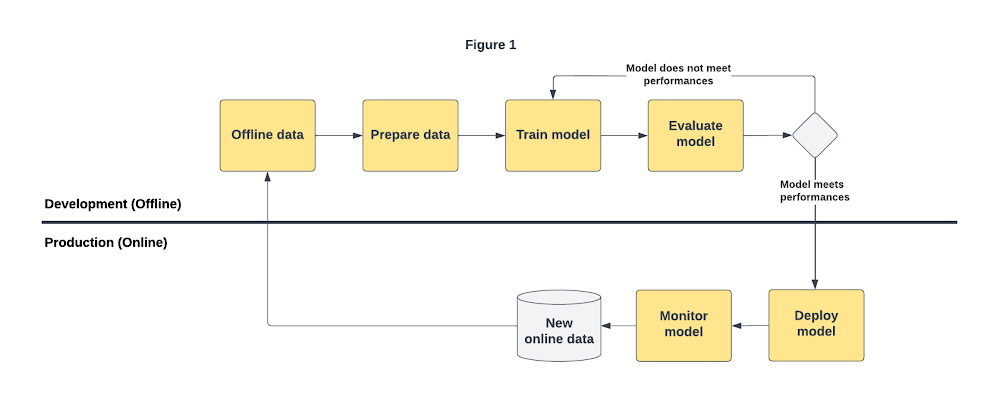
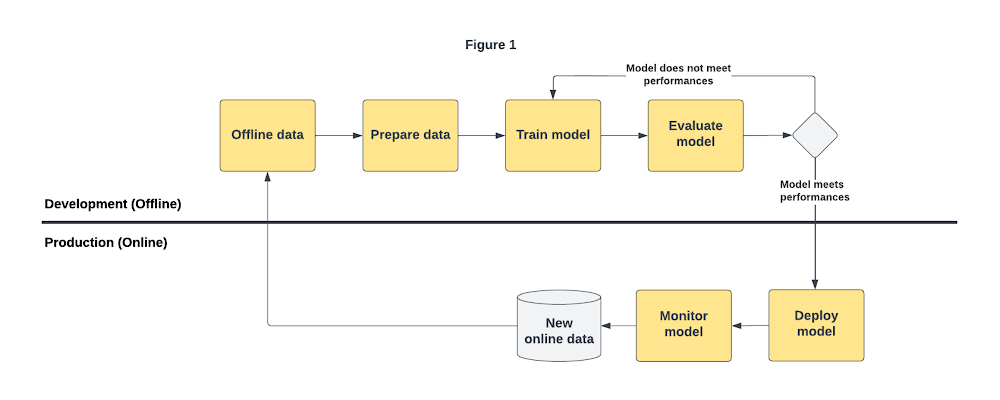
In fact, after training a model, data scientists and ML engineers use an offline dataset of historical examples from the production environment to evaluate model performance across several model experiments. If the evaluation metrics meet some predefined thresholds, data scientists and ML engineers can proceed to deploy the model, either manually or by using a ML pipeline. This process serves to find the best model (approach and configuration) to go to production. Figure 1 illustrates a basic workflow in which data scientists and ML engineers gather new data and retrain the model at regular intervals.
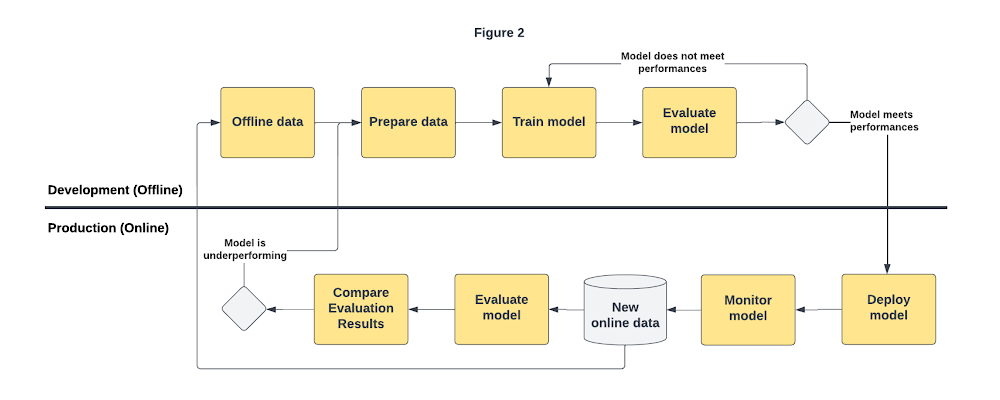
Depending on use cases, continuous model evaluation might be required. Once deployed, the model is monitored in production by detecting skew and drift both in features and target distributions. When a change in those distributions is detected, because the model could start underperforming, you need to evaluate it by using production data. Figure 2 illustrates an advanced workflow where teams gather new data and continuously evaluate the model. Based on the outcome of continuous evaluation, the model is retrained with new data.
At scale, building this continuous evaluation system can be a challenging task. There are several factors that contribute to making it difficult including getting access to production data, provisioning computational resources, standardizing the model evaluation process, and guaranteeing its reproducibility. With the intent to simplify and accelerate the entire process of defining and running ML evaluations, Vertex AI Model Evaluation enables you to iteratively assess and compare model performance at scale.
With Vertex AI Model Evaluation, you define a test dataset, a model, and an evaluation configuration as inputs and it will return model performance metrics whether you are training your model using your notebook, running a training job, or an ML pipeline on Vertex AI.
Vertex AI Model Evaluation is integrated with the following products:
- Vertex AI Model Registrywhich provides a new view to get access to different evaluation jobs and the resulting metrics they produce after the model training job completes.
- Model Builder SDKwhich introduces a new evaluate method to get classification, regression, and forecasting metrics for a model trained locally.
- Managed Pipelines with a new evaluation component to generate and visualize metrics results within the Vertex AI Pipelines Console.
Now that you know the new features of Vertex AI Model Evaluation, let’s see how you can leverage them to improve your model quality at scale.
Evaluate performances of different models in Vertex AI Model Registry
As the decision maker who has to promote the model to production, you need to govern the model launching process.
To release the model, you need to easily retrieve, visualize, and compare the offline and online performance and explainability metrics of the trained models.
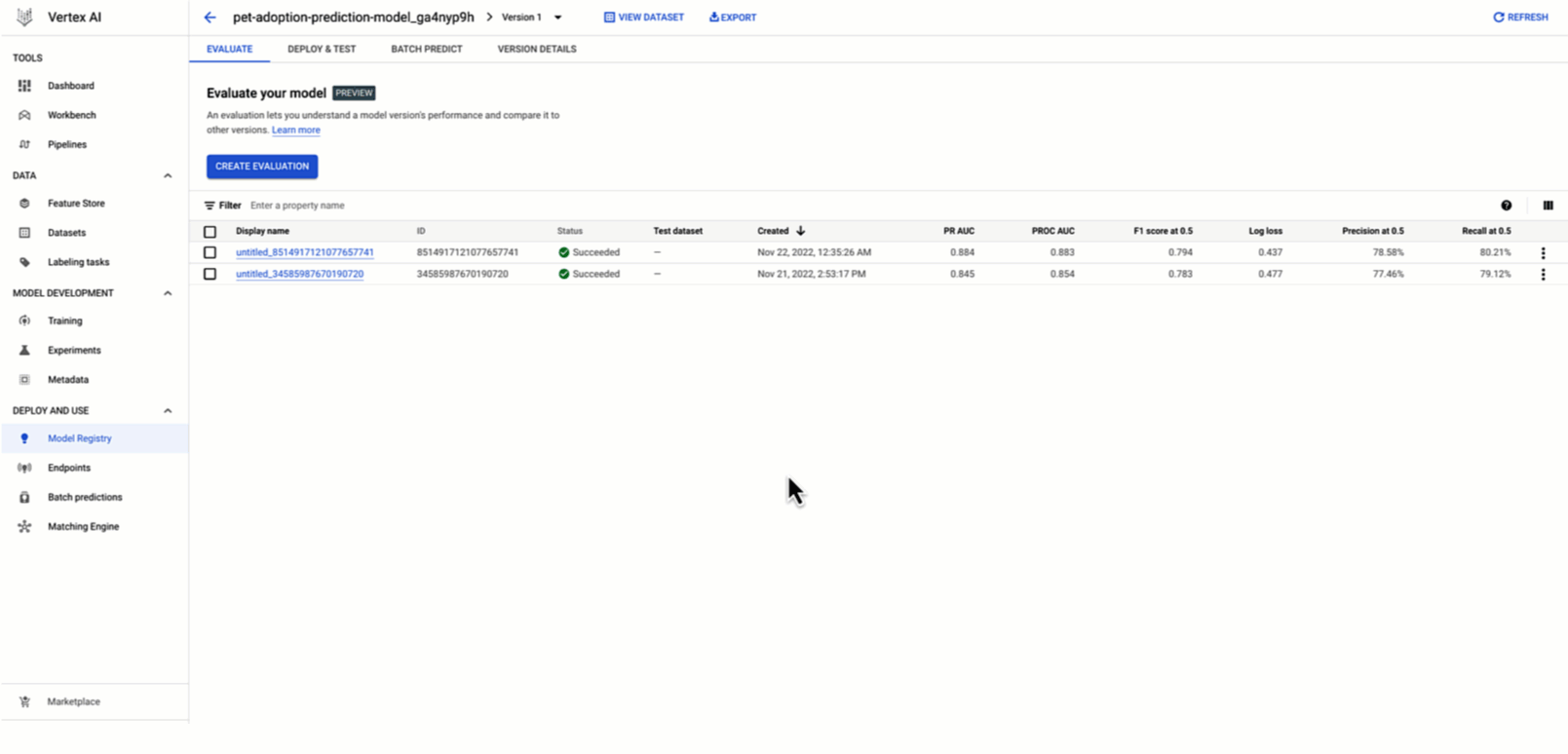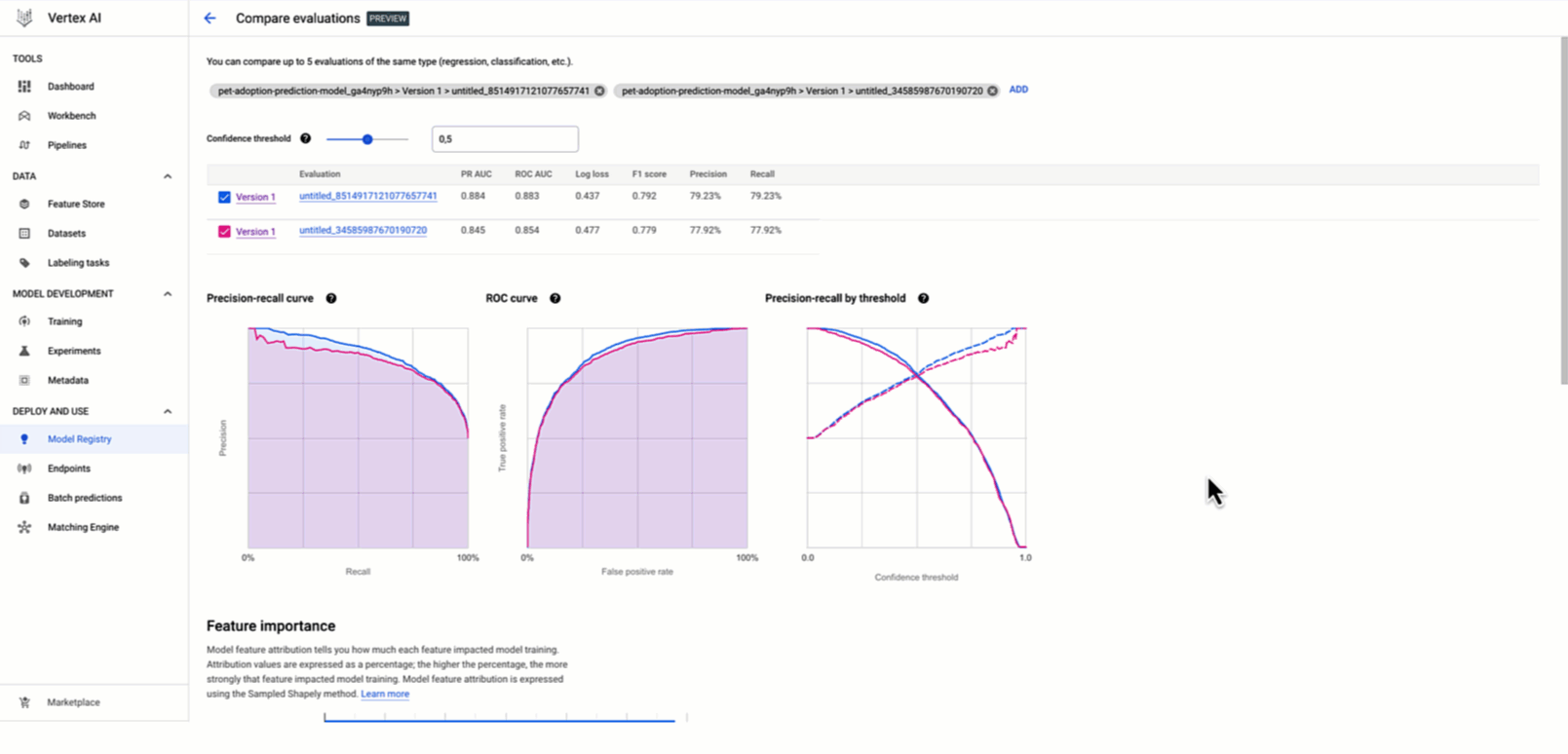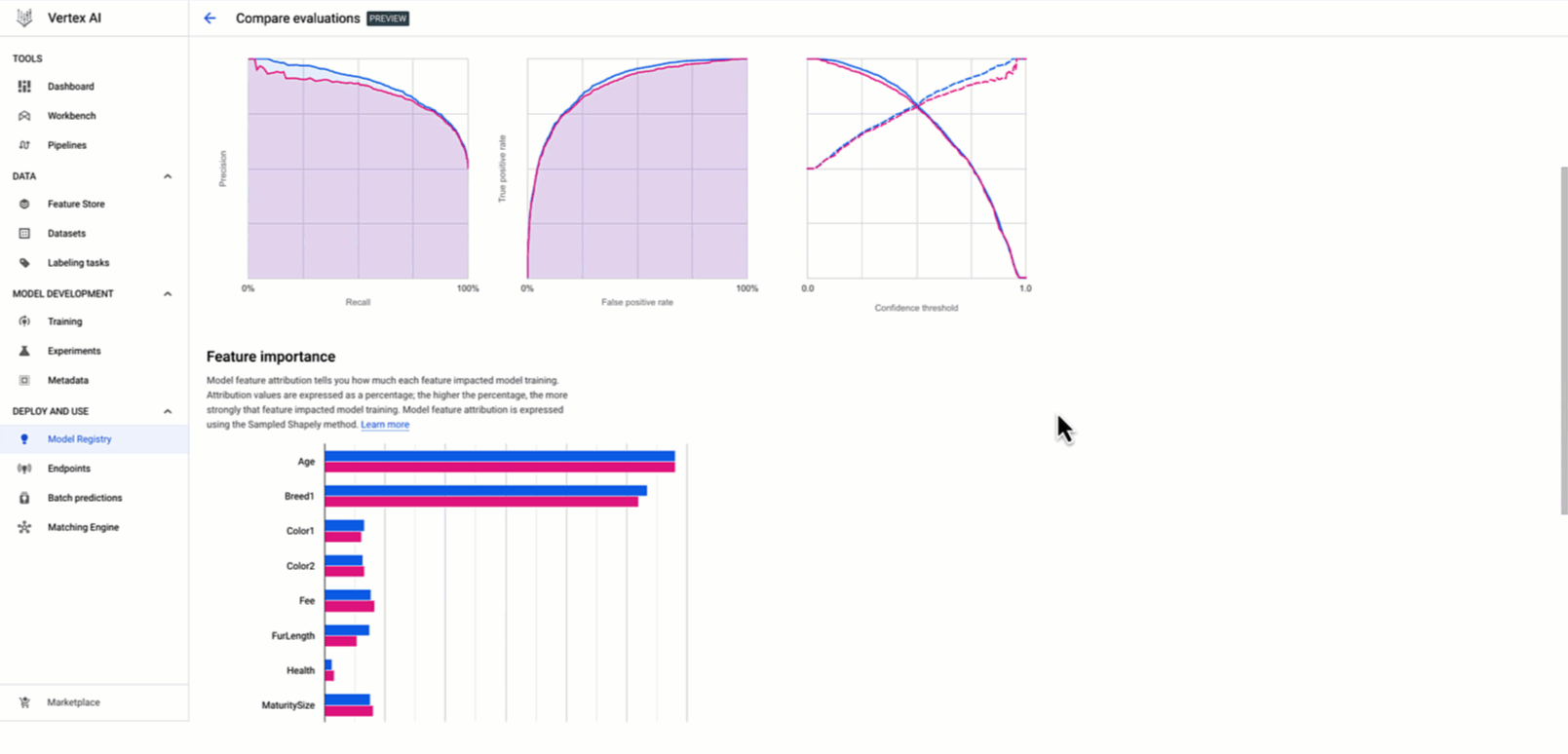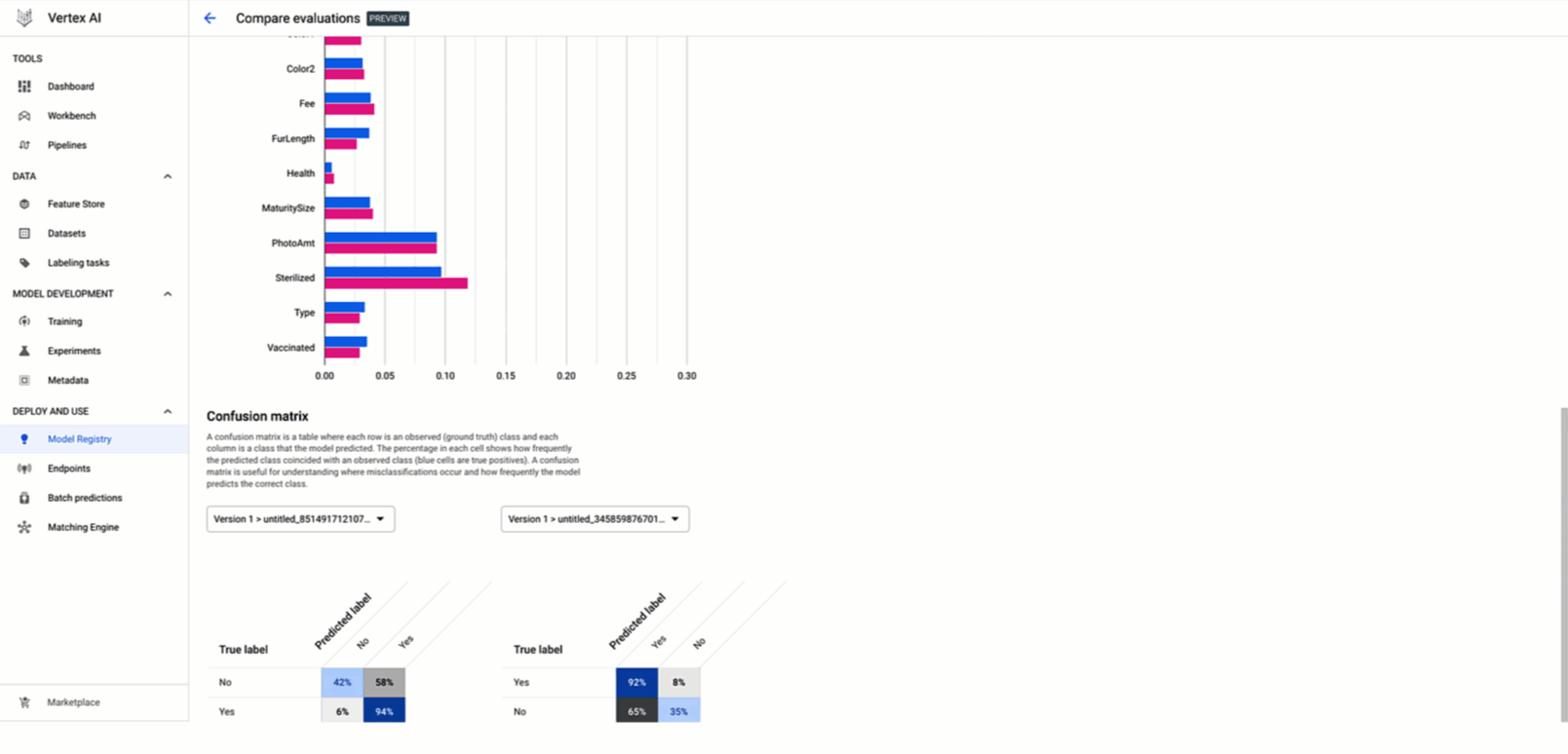
Thanks to the integration between Vertex AI Model Registry and Vertex AI Model evaluation, you can now view all historical evaluations of each model (BQML, AutoML and custom models). For each model version, the Vertex AI Model Registry console shows classification, regression, and forecasting metrics depending on the type of model.
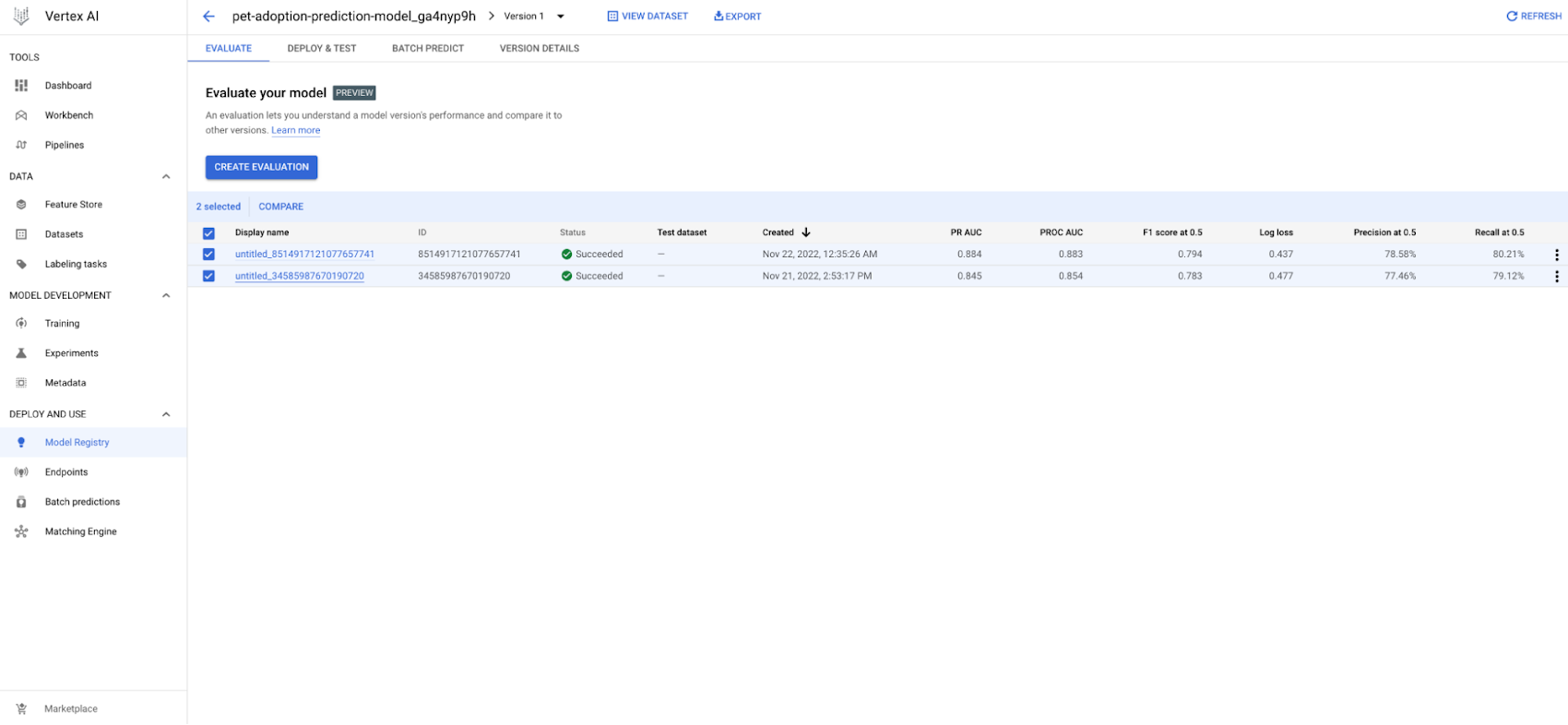
You can also compare those metrics across different model versions to identify and explain the best model version to deploy as an online experiment or directly to production.
Train and evaluate your model in your notebook using Model Builder SDK
During the model development phase, as a data scientist, you experiment with different models and parameters in your notebook. Then, you calculate measurements such as accuracy, precision, and recall, and build performance plots like confusion matrix and ROC on a validation/test dataset. Those indicators allow you and your team to review the candidate model’s performance and compare it with other model(s) to ultimately decide whether the model is ready to be formalized in a component of the production pipeline.
The new Vertex AI Model Builder SDK allows you to calculate those metrics and plots by leveraging Vertex AI. By providing the testing dataset, the model and the evaluation configuration, you can submit an evaluation job. After the evaluation task is completed, you are able to retrieve and visualize the results of the evaluation locally across different models and compare them side-by-side to decide whether or not to deploy it as an online experiment or directly into production.
Below is an example of how to run an evaluation job for a classification model.
- code_block
- [StructValue([(u’code’, u’# Upload the model as Vertex AI model resourcernvertex_model = aiplatform.Model.upload(rn display_name=”your-model”,rn artifact_uri=”gcs://your-bucket/your-model”,rn serving_container_image_uri=”your-serving-image”,rn)rn# Run an evaluation jobrneval_job = vertex_model.evaluate(rn gcs_source_uris=[“gcs://your-bucket/your-evaluate-data.csv”],rn prediction_type=”classification”,rn class_labels=[“class_1”, “class_2″],rn target_column_name=”target_column”,rn prediction_label_column=”prediction”,rn prediction_score_column=”prediction”,rn experiment=”your-experiment-name”rn)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e4dfb7c7490>)])]
Notice that all parameters and metrics of the evaluation job are tracked as part of the experiment to guarantee its reproducibility.
The Model Evaluation in the Vertex SDK is in Experimental release. To get access, please fill out this form.
Operationalize model evaluation with Vertex AI Pipelines
Once the model has been validated, ML engineers can proceed to deploy the model, either manually or from a pipeline. When the production pipeline is required, it has to include a formalized evaluation pipeline component that produces the model quality metrics. In this way, the model evaluation process can be replicated at scale and the evaluation metrics can be logged into downstream systems such as Experiments tracking and Model Registry services. At the end, decision makers can use those metrics to validate models and determine which model will be deployed.
Currently, building and maintaining an evaluation component requires time and resources. Instead you want to focus on solving new challenges and building new ML products. To simplify and accelerate the process of defining and running evaluations within ML pipelines, we are excited to announce the release of new operators for Vertex AI Pipelines that help make it easier to operationalize model evaluation in a Vertex AI Pipeline. Indeed those components automatically generate and track evaluation results to facilitate easy retrieval and model comparison. Below you have the main evaluation operators:
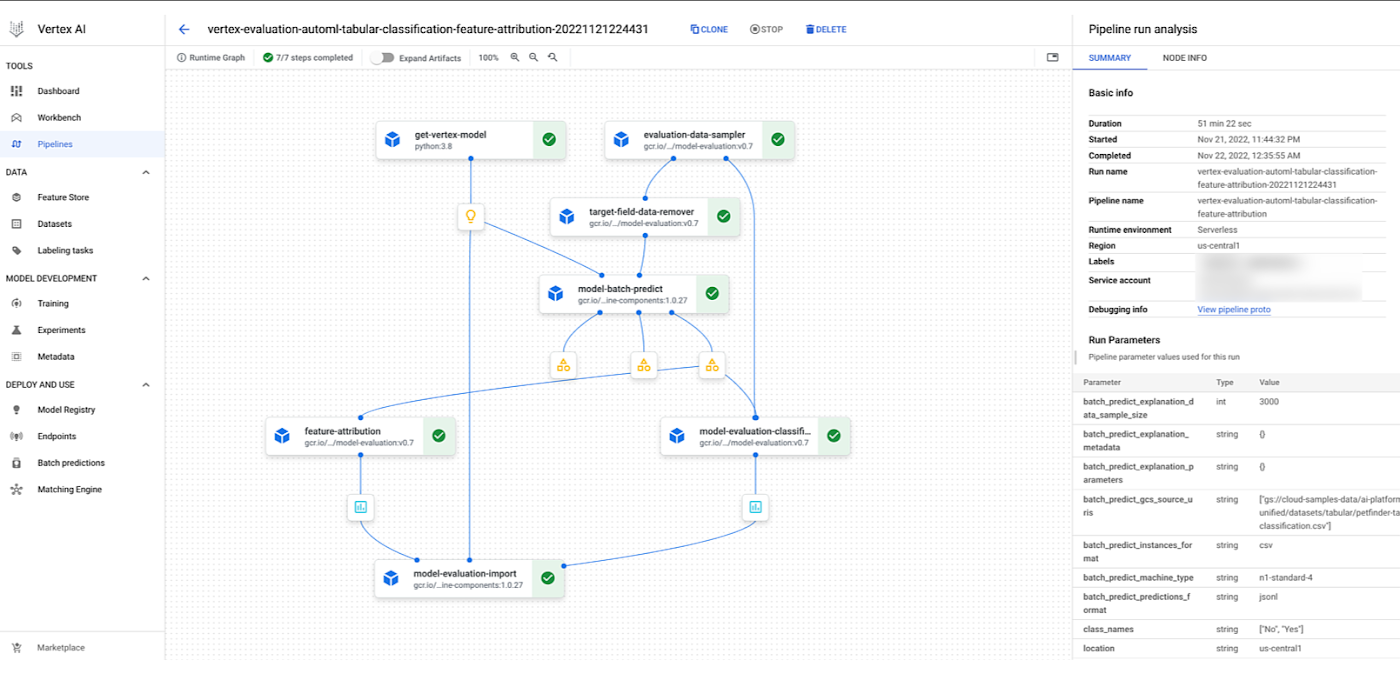
GetVertexModelOpto initialize the Vertex Model Artifact to evaluate.EvaluationDataSamplerOpto create an input dataset randomly with a specified size for computing Vertex XAI feature attributions.TargetFieldDataRemoverOpto remove the target field from the input dataset for supporting custom models for Vertex Batch PredictionModelBatchPredictOpto run a Google Cloud Vertex BatchPredictionJob and generate predictions for model evaluationModelEvaluationClassificationOpto compute evaluation metrics on a trained model’s batch prediction resultsModelEvaluationFeatureAttributionOpto generate feature attribution on a trained model’s batch explanation results.ModelImportEvaluationOpto store a model evaluation artifact as a resource of an existing Vertex model with ModelService.
With these components, you can define a training pipeline that starts from a model resource and generates the evaluation metrics and the feature attributions from a given dataset. Below you have an example of a Vertex AI pipeline using those components in combination with a Vertex AI AutoML model in a classification scenario.
Conclusion
Vertex AI Model Evaluation enables customers to accelerate and operationalize model performance analysis and validation steps required in an end-to-end MLOps workflow. Thanks to its native integration with other Vertex AI services, Vertex AI Model Evaluation allows you to run model evaluation jobs (measure model performance on a test dataset) regardless of which Vertex service used to train the model (AutoML, Managed Pipelines, Custom Training, etc.) and store and visualize the evaluation results across multiple models in Vertex AI Model Registry. With these capabilities, Vertex AI Model Evaluation enables users to decide which model(s) can progress to online testing or be put into production, and once in production, when models need to be retrained.
Now it’s your turn. Check out notebooks in the official Github repo and the resources below to get started with Vertex AI Model Evaluation. And remember…Always have fun!
Want to learn more?
Documentation:
Samples:
Thanks to Jing Qi, Kevin Naughton, Marton Balint, Sara Robinson, Soheila Zangeneh, Karen Lin and all Vertex AI Model Evaluation team for their support and feedback.