

It is often said that a picture is worth a thousand words — when it comes to describing data however, metadata can sometimes be those thousand words. Metadata is the characteristics that describe data itself, from when data was last updated, to what the attributes and classification are — the list goes on.
In this blog post, we explore why metadata should never be viewed as an afterthought, but rather as a central component to every data platform — both when it comes to looking at data, but also operationalizing it — and the role it plays in protecting data more widely.
The first step to a successful metadata strategy is ensuring that relevant and necessary metadata is properly captured; the second is enabling the ability to interact with the metadata. This is where metadata management comes in. This is the practice of actually operationalizing this information — making it accessible to users, better organizing it to make it usable, enabling search functions, surfacing it to users to augment their experience, and establishing it within the organization to properly manage entire data platforms. In short, this means that metadata should be curated, searchable, accessible, and analyzable by authorized users next to the data itself in a timely way to provide its full potential.
Why does it matter?
Imagine finding an unlabeled box on a walk. You do not know how long it’s been there, where it came from, how it got there, who left it, what’s inside, whether it’s dangerous, or of value to you, or even if someone intentionally put it there for you to find. In that moment in time, it’s just a box, but with some additional context and some labels, you could discover what it is, if you should take it, and potentially if it is dangerous to be around.
This is where metadata comes in. What makes metadata powerful is its ability to provide the necessary context about the data in question. Data on its own is just of one-dimensional value, but it’s the insight to its properties that make it relevant and meaningful, as well as ensure it is used appropriately. Metadata provides this insight to data in multiple ways — not only how it relates to other data and what kind of data it is — but also how it has changed over time. Without this context, data could potentially be misused or misinterpreted, which ultimately reduces trust in data.
When we further apply metadata to facilitate data protection and data governance, it gives data its markers or characteristics that can in turn become the key to understanding what kind of restrictions, controls, and handling requirements apply — at whatever granularity from a data source, dataset, or even down to cell level. In short, matching data protection requirements to data itself demands its metadata.
It is worth distinguishing that in this blogpost, while there are many types of metadata, we seek to focus on descriptive, administrative, and contextual metadata that describes characteristics of data that can be used for governance, structure, and understanding the data itself. It is also worth noting that when deciding what metadata for systems to capture, it is important to keep in mind general best practices for data privacy, such that systems only capture necessary metadata proportional to its authorized and justified purposes.
How do we think about?
At Palantir, we’ve invested in building tools for all types of users — data administrators, owners, consumers, as well as data producers, modelers, business analysts, executive audiences, and others. For people who have had to work with data, these questions will be familiar:
- Where did this data come from? What kind of data source is it?
- Who is the owner of — or subject matter expert — about this data in case I have questions?
- Who can provide permission to this data? Who knows what controls are necessary?
- Is this data stale? When was it last refreshed? When is it scheduled to refresh next?
- Are there limitations to how this data can be used?
- Are there concerns with its accuracy? Is anyone monitoring this data feed?
- Is there other data like this?
- What did this data look like before? How has it changed over time?
Allowing users to leverage metadata ensures not only that their data and analytics are built with as much context as possible, but can also reduce the chaos that often comes with growing volumes of data.
Now, making sure the necessary metadata is regularly captured as well as making it retrievable makes it both operational and often much more useful in how it can be leveraged. In light of this, we ensure metadata also satisfies the following:
- Comprehensive Capture — Every piece of data should come associated with a set of default metadata at the very minimum, to help users understand what it is, consistently recorded, and retrievable for access.
- Real-time Updates — As data changes, the metadata should change with it. Having metadata automatically captured, computed, and surfaced to users at the time of access ensures that users can use the metadata to inform their own understanding of the data as they are using it.
- Accessible for Review — In order to operationalize metadata, it must be retrievable by users, especially in bulk for authorized analysis. Many systems capture metadata, but store it in inaccessible tables or offline documents, which often reduces the utility of capturing it in the first place — as many users may not even know it’s there, or that it is something they can use. In addition to this, giving users tools to visualize their metadata provides yet another powerful way for them to understand their data.
- Dynamic Trend Analysis (if applicable) — Data is dynamic. The ability to operationalize metadata by tracking how the data changes gives users signal on the health and status of the data — this is vital for users who regularly depend on that data. Workflows like proactively alerting and tracking changes provides opportunities to detect issues early on before they become a problem.
When it comes to platforms with sensitive data, which can vary from confidential company data to personally identifiable data (PII), metadata can guide and help enforce data protection and governance workflows, which is a powerful way to operationalize it. This metadata provides context, and in turn tags the data it describes for relevant business rules, access control restrictions, and other relevant handling restrictions.
How does this work in Foundry?
While the uses of metadata are effectively boundless, below we describe some of the most critical uses we have seen. Palantir Foundry captures, curates, organizes, and shares the metadata to users, enabling better outcomes by answering common questions for user and platform administrators — right at their fingertips. While Foundry applications, models, code, and other resources and artifacts also carry important metadata, here we seek to focus on and highlight some of the metadata captured with Foundry datasets as governance and data protection requirements often tie to the underlying data itself.
Static Metadata for Reference
As mentioned above, capturing characteristics about data itself is the first step in understanding it. As an example, the view of a dataset in Foundry below provides a series of metadata that is available for every dataset. Some components are automatically generated, while others are manually tagged (such as tags and issues) and surfaced directly to users. Here’s a description of common metadata on Foundry datasets:
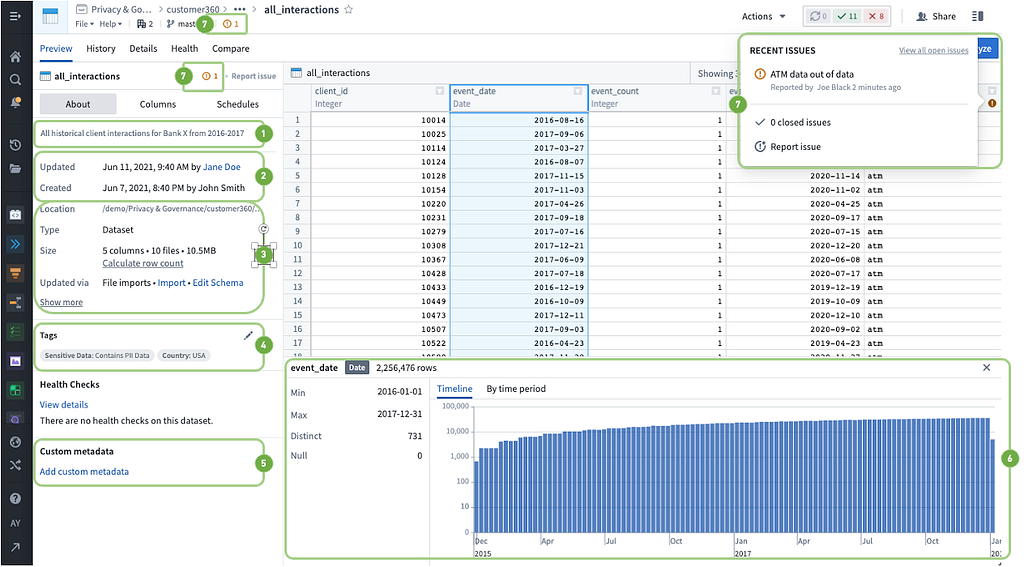
Any data contained herein is notional.
- Dataset Description — This provides a high-level overview and relevant annotations — often unstructured for flexibility — of what the dataset is, any additional notes from the data owner or preparer, and sometimes even links or details to learn more about how the dataset was prepared or can be used.
- Data Editors and Ownership — Provides visibility into who data editors are, who owns the data, who to contact for access or issues, and even who would be able to answer questions about the underlying data itself as subject matter experts.
- Data File Characteristics — Indicates general characteristics about the location, type, size, rows, data source, and more about the data. This allows not only an understanding of where data came from, but also how it might need to be processed.
- Data Tags — Identifies structured characteristics that might be particularly useful for data protection, data governance, or categories of data. For instance, data from specific countries may need to be handled or limited in where it can be hosted or accessed; PII may also need special handling or be subject to specific deletion requirements. By having these tags visible alongside the data, it allows users to quickly identify these characteristics and how they may tie to other requirements or restrictions.
- Custom Metadata — Enables flexibility to create more curated or unique metadata that tag datasets. This is particularly relevant as data assets grow and user groups are onboarded who do not need organization-wide standard metadata tags, but rather more temporary, granular, or configurable tags. For instance, this could include relevant variable retention policies, encryption methods, and data handling restrictions.
- Foundry Statistics — Provides a view and ability to understand the data profile and attributes, its type, and shape of datasets to give users a sense of what data they are working with. Statistics such as the date range of data to how many distinct values or individuals are represented in a dataset give users key expectations for what is represented in the dataset.
- Data Quality — Provides the ability to see how data changes over time, especially if there are data quality, latency, or other concerns that may affect the fidelity of the data itself or a user’s Trust in Data. This can then trigger Foundry Issues for a resolution workflow.
On top of presenting metadata alongside the data, users can then zoom out and review the metadata across all data on the platform using Foundry’s Data Lineage capability. The figure below shows how the same data pipeline can be visualized through the lens of varying metadata from resource types to permissions and access to build status to out-of-date data and more:

Dynamic Metadata for Trends and Analytics
On top of capturing point-in-time information about datasets, Foundry also provides trend reports for certain metadata as it is captured. This not only means that metadata is regularly captured, but it can then be analyzed and viewed alongside the data itself. Here are some examples of dynamic metadata associated with Foundry datasets:
- Data Processing Status Tracking — This provides views of how data is processed and can be highly informative to data engineers and users trying to understand key questions like how long it may take their dataset to update, whether there is an issue with the data or code being processed, or even how it varies over time. Being able to see these trends can quickly inform users of potential problems and expectations about their data.

Data Health — Captures specific metrics about metadata over time, which can also be used to alert data issues or changes. As an example, ‘issues’ (see mentioned in point 7 above) can be created automatically when data issues arise. This can then easily be analyzed by someone looking at the data to see why data might not conform to quality standards. In providing this context, users can get a better sense of what to expect as well as what they are currently seeing.
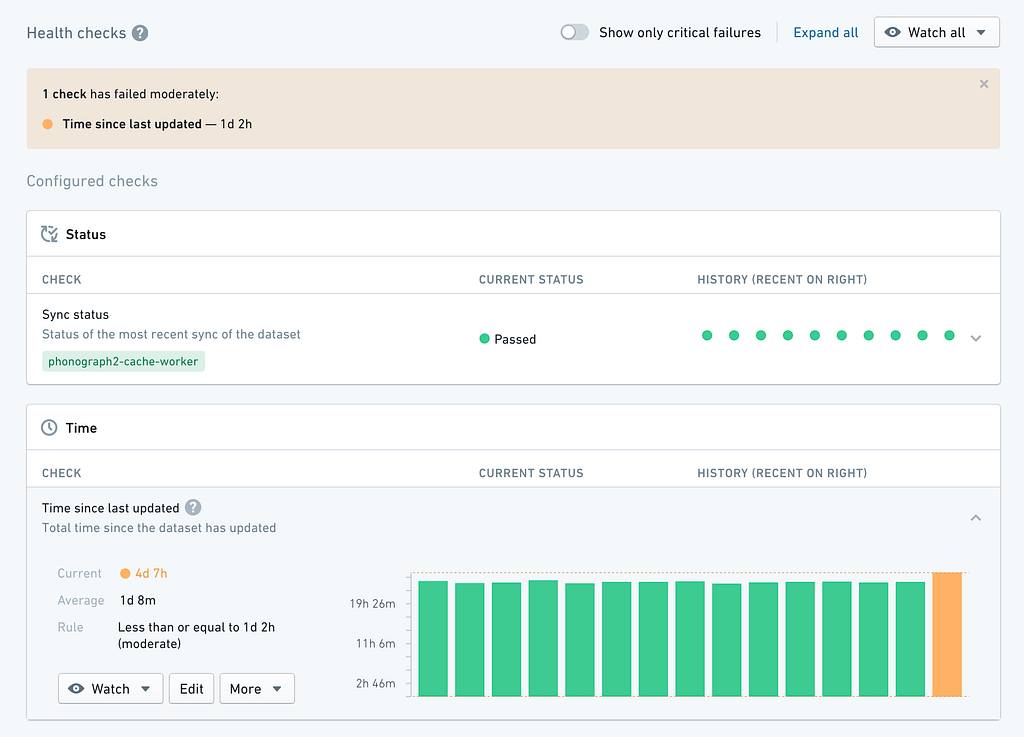
Visualizing Operational Metadata for Data Protection and Governance
Metadata can also be used for operational purposes such as for data governance and protection. This section provides a series of examples of how metadata in Foundry helps inform users when there is sensitive data and how they can easily use the available metadata to search and see that in the context of their other data.
- PII Tags — Whether using automated detection tools such as Foundry Inference or manually tagging, Foundry enables users and data owners to tag and label PII on the data itself, so it is apparent to all users when they are working with sensitive data. This can be via tools like security markings, which tag and propagate with the data or with metadata tags, such as in Figure 1 above.

Searchable Metadata — Foundry also enables users to easily search for columns, tags, descriptions, and other metadata across the platform. Users can even search for metadata such as columns across all datasets within a specific realm to know which datasets or resources contain sensitive data.

Operational Metadata for Review — This can also be done looking for Foundry issues as well — such as when PII might be detected — and triggers an issue for a Data Administrator to review:
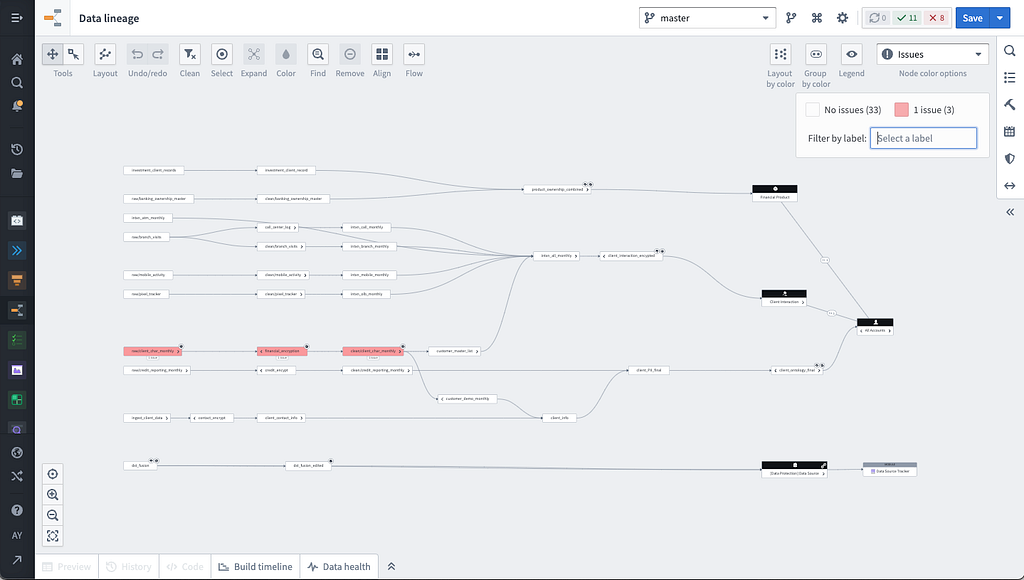
As we have learned over the last 20 years, data is of course critical, but metadata provides richness to the data to allow an understanding into different facets of the data itself. These facets can also be used to inform data protection and governance workflows that are often manual and tedious to upkeep, but necessary to enforce at scale and when used on a day-to-day basis. To fully take advantage of metadata, Foundry programmatically captures it, enables users with analysis tools to see trends, to further operationalize data protection and governance for users to ensure its responsible and accountable use.
It’s All in the Details
Palantir has worked with data in over 40 industries in its mission to solve the world’s hardest problems for vital institutions. Over time and across our customer base, we have learned that metadata can often be as valuable as the data itself, in providing transparency to the underlying information. The ability to capture, access, analyze, and operationalize metadata gives our users another dimension to understand the data itself and democratizes it by giving people the tools to understand the context around the data they need to use.
We built Foundry to empower our users — the true experts of their data — and our products seek to ensure those on the frontlines have the necessary details about their data to make the best decisions when they need it the most.
Author
Alice Yu, Privacy & Civil Liberties Commercial and Public Health Lead, Palantir Technologies
![]()
Metadata Management for Data Protection was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.