
Whether you are performing image recognition, language processing, regression analysis, or other machine learning demonstrations, the importance of rapid prototyping and deployment remains of utmost importance. These computations tend to have steps with various CPU and GPU requirements. Google Cloud introduced Batch, which is a fully managed service that handles infrastructure lifecycle management, queuing, and scheduling for batch workloads including those mentioned. In conjunction with TorchX, which is designed to run distributed PyTorch workloads with fast iteration time for training and productionizing ML pipelines, we are further simplifying the developer experience for machine learning application development.
Typically ML developers could build a custom platform using Open Source Software (OSS) or reduce complexity by leveraging a fully managed platform such as Vertex AI. There are instances where developers preferred one or the other based on their need for flexibility. When using self managed resources PyTorch users incurred several operational steps before they can begin training. The setup includes but is not limited to adding PyTorch and related torch packages in the docker container. Packages such as:
Pytorch DDP for distributed training capabilities like fault tolerance and dynamic capacity management
Torchserve makes it easy to deploy trained PyTorch models performantly at scale without having to write custom code
Gluing these together would require configuration, writing custom code, and initializing steps. TorchX puts together all this setup for you. To accelerate the path from research prototyping to production, TorchX enables ML developers to test development locally and within a few steps you can replicate the environment in the cloud. An ecosystem of tools exist for hyperparameter tuning, continuous integration and deployment, and common Python tools can be used to ease debugging along the way. TorchX can also convert production ready apps into a pipeline stage within supported ML pipeline orchestrators like Kubeflow, Airflow, and others.
Batch support in TorchX is introducing a new managed mechanism to run PyTorch workloads as batch jobs on Google Cloud Compute Engine VM instances with or without GPUs as needed. This integration combines Batch’s powerful features with the wide ecosystem of PyTorch tools.
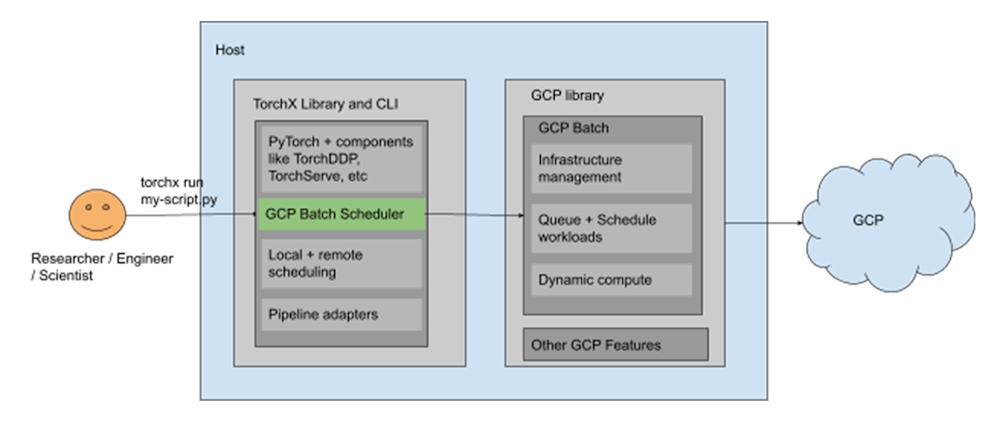
Putting it all together
With knowledge on these services under our belt, let’s take a look at an example architecture to train a simple model using the PyTorch framework with TorchX, Batch, and NVIDIA A100 GPUs.
Prerequisites
Setup needed for Batch
You need to have a Google Cloud project configured to use Batch by enabling and setting it up. See the prerequisite documentation for the IAM permissions needed.
Setup needed for TorchX
From a project within the Google Cloud Console you can access Cloud Shell or SSH into a Compute Engine VM instance to install TorchX on it, and check your installation. Once you have Python installed you can run the following commands:
- code_block
- [StructValue([(u’code’, u’$ pip install torchx[gcp_batch]rn$ torchx rn# this should print torchx help. If not, add torchx installation path to your system PATH’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2967e48150>)])]
Training the model
As a user, you only need to write your training script. Just call the TorchX CLI while specifying the Batch scheduler, which will set up and use the batch library to start running your job, and can stream back the logs to you. This helps decouple your training script from scheduler specific setup.
Accessing the CLI
Start by accessing the Cloud Shell CLI or by Login/SSH to the Compute Engine VM instance that you installed TorchX. Make sure the host has access to all enabled Cloud APIs in your project and ensure the Batch APIs are enabled like mentioned in the prerequisites.
Launching jobs on Batch
You can submit your TorchX app to Batch using the TorchX CLI or APIs.
TorchX supports various built-in components (a.k.a templetized app specs). All TorchX components can run on Batch. We will see how to launch them from the TorchX CLI in the examples below.
Syntax to run a TorchX component on Google Cloud Batch:
- code_block
- [StructValue([(u’code’, u’$ torchx run –scheduler gcp_batch -cfg project=<project-name> -cfg location=<location-name> <torchx-component-name> <torchx component arguments>’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2980b45a90>)])]
You can use scheduler config options to optionally configure the Google Cloud project name and location. By default Torchx uses the configured Google Cloud project in the environment and uses us-central1 as the location.
Examples:
Launch a simple job that runs python code
- code_block
- [StructValue([(u’code’, u’$ torchx run –scheduler gcp_batch utils.python -c ‘print(“Hello World”)’ rnrn#Launch on gpu. Make sure you have enough quotarntorchx run –scheduler gcp_batch utils.python –gpu 2 -c ‘print(“Hello World”)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2980b45350>)])]
Run distributed training scripts
TorchX launches the default torchx docker image when running distributed components. To run a distributed training script available inside the default docker image that computes the world size:
- code_block
- [StructValue([(u’code’, u’$ torchx run –scheduler gcp_batch dist.ddp -j 2×2 –script torchx/schedulers/test/train.py’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2980b45090>)])]
Syntax to run distributed scripts inside your custom docker image:
- code_block
- [StructValue([(u’code’, u”$ torchx run –scheduler gcp_batch dist.ddp –image <path-to>/image:latest -j 2×2 –script <path-to>/script.pyrnrn# docker image path in your GCP project’s artifact registry would look like: <gcp-location>-docker.pkg.dev/<gcp-project-name>/<artifact-registry-name>/<docker-image>:latest”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2980b45d10>)])]
- code_block
- [StructValue([(u’code’, u’$ torchx log <app_handle>’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e297951f810>)])]
TorchX also helps to get the job status, describe the job, cancel the job, and list all jobs that have been submitted with their respective status.
Take the next steps
In this blog we covered how to leverage Batch with TorchX to develop and deploy PyTorch applications rapidly at scale. To summarize the user experience for PyTorch development is improved by:
Lift and shift local development to the cloud
Managed infrastructure lifecycle and scheduling of the workload
Scalable compute resources provided by Google Cloud
Pre-packaging torch related dependencies in docker containers
Reducing the amount of code needed to get started
Leveraging torchelastic for fault tolerance and elastic distributed training
Easy integration of PyTorch ecosystem for MLOps, CI/CD, and observability
Now you are ready to start. See application examples for samples that can be used along with Batch.