
Today, companies are establishing feature stores to provide a central repository to scale ML development across business units and data science teams. As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring.
Amazon SageMaker Feature Store is a purpose-built feature management solution that helps data scientists and ML engineers securely store, discover, and share curated data used in training and prediction workflows. SageMaker Feature Store now supports Apache Iceberg as a table format for storing features. This accelerates model development by enabling faster query performance when extracting ML training datasets, taking advantage of Iceberg table compaction. Depending on the design of your feature groups and their scale, you can experience training query performance improvements of 10x to 100x by using this new capability.
By the end of this post, you will know how to create feature groups using the Iceberg format, execute Iceberg’s table management procedures using Amazon Athena, and schedule these tasks to run autonomously. If you are a Spark user, you’ll also learn how to execute the same procedures using Spark and incorporate them into your own Spark environment and automation.
SageMaker Feature Store and Apache Iceberg
Amazon SageMaker Feature Store is a centralized store for features and associated metadata, allowing features to be easily discovered and reused by data scientist teams working on different projects or ML models.
SageMaker Feature Store consists of an online and an offline mode for managing features. The online store is used for low-latency real-time inference use cases. The offline store is primarily used for batch predictions and model training. The offline store is an append-only store and can be used to store and access historical feature data. With the offline store, users can store and serve features for exploration and batch scoring and extract point-in-time correct datasets for model training.
The offline store data is stored in an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform big data processing for ML feature analysis and feature engineering use cases.
Table formats provide a way to abstract data files as a table. Over the years, many table formats have emerged to support ACID transaction, governance, and catalog use cases. Apache Iceberg is an open table format for very large analytic datasets. It manages large collections of files as tables, and it supports modern analytical data lake operations such as record-level insert, update, delete, and time travel queries. Iceberg tracks individual data files in a table instead of in directories. This allows writers to create data files in place (files are not moved or changed) and only add files to the table in an explicit commit. The table state is maintained in metadata files. All changes to the table state create a new metadata file version that atomically replaces the older metadata. The table metadata file tracks the table schema, partitioning configuration, and other properties.
Iceberg has integrations with AWS services. For example, you can use the AWS Glue Data Catalog as the metastore for Iceberg tables, and Athena supports read, time travel, write, and DDL queries for Apache Iceberg tables that use the Apache Parquet format for data and the AWS Glue catalog for their metastore.
With SageMaker Feature Store, you can now create feature groups with Iceberg table format as an alternative to the default standard Glue format. With that, customers can leverage the new table format to use Iceberg’s file compaction and data pruning features to meet their use case and optimization requirements. Iceberg also lets customers perform deletion, time-travel queries, high-concurrency transactions, and higher-performance queries.
By combining Iceberg as a table format and table maintenance operations such as compaction, customers get faster query performance when working with offline feature groups at scale, letting them more quickly build ML training datasets.
The following diagram shows the structure of the offline store using Iceberg as a table format.

In the next sections, you will learn how to create feature groups using the Iceberg format, execute Iceberg’s table management procedures using AWS Athena and use AWS services to schedule these tasks to run on-demand or on a schedule. If you are a Spark user, you will also learn how to execute the same procedures using Spark.
For step-by-step instructions, we also provide a sample notebook, which can be found in GitHub. In this post, we will highlight the most important parts.
Creating feature groups using Iceberg table format
You first need to select Iceberg as a table format when creating new feature groups. A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. This parameter accepts the values ICEBERG or GLUE (for the current AWS Glue format). The following code snippet shows you how to create a feature group using the Iceberg format and FeatureGroup.create API of the SageMaker SDK.
The table will be created and registered automatically in the AWS Glue Data Catalog.
Now that the orders_feature_group_iceberg is created, you can ingest features using your ingestion pipeline of choice. In this example, we ingest records using the FeatureGroup.ingest() API, which ingests records from a Pandas DataFrame. You can also use the FeatureGroup().put_record API to ingest individual records or to handle streaming sources. Spark users can also ingest Spark dataframes using our Spark Connector.
You can verify that the records have been ingested successfully by running a query against the offline feature store. You can also navigate to the S3 location and see the new folder structure.

Executing Iceberg table management procedures
Amazon Athena is a serverless SQL query engine that natively supports Iceberg management procedures. In this section, you will use Athena to manually compact the offline feature group you created. Note you will need to use Athena engine version 3. For this, you can create a new workgroup, or configure an existing workgroup, and select the recommended Athena engine version 3. For more information and instructions for changing your Athena engine version, refer to Changing Athena engine versions.
As data accumulates into an Iceberg table, queries may gradually become less efficient because of the increased processing time required to open additional files. Compaction optimizes the structural layout of the table without altering table content.
To perform compaction, you use the OPTIMIZE table REWRITE DATA compaction table maintenance command in Athena. The following syntax shows how to optimize the data layout of a feature group stored using the Iceberg table format. The sagemaker_featurestore represents the name of the SageMaker Feature Store database, and orders-feature-group-iceberg-post-comp-03-14-05-17-1670076334 is our feature group table name.
After running the optimize command, you use the VACUUM procedure, which performs snapshot expiration and removes orphan files. These actions reduce metadata size and remove files that are not in the current table state and are also older than the retention period specified for the table.
Note that table properties are configurable using Athena’s ALTER TABLE. For an example of how to do this, see the Athena documentation. For VACUUM, vacuum_min_snapshots_to_keep and vacuum_max_snapshot_age_seconds can be used to configure snapshot pruning parameters.
Let’s have a look at the performance impact of running compaction on a sample feature group table. For testing purposes, we ingested the same orders feature records into two feature groups, orders-feature-group-iceberg-pre-comp-02-11-03-06-1669979003 and orders-feature-group-iceberg-post-comp-03-14-05-17-1670076334, using a parallelized SageMaker processing job with Scikit-Learn, which results in 49,908,135 objects stored in Amazon S3 and a total size of 106.5 GiB.
We run a query to select the latest snapshot without duplicates and without deleted records on the feature group orders-feature-group-iceberg-pre-comp-02-11-03-06-1669979003. Prior to compaction, the query took 1hr 27mins.
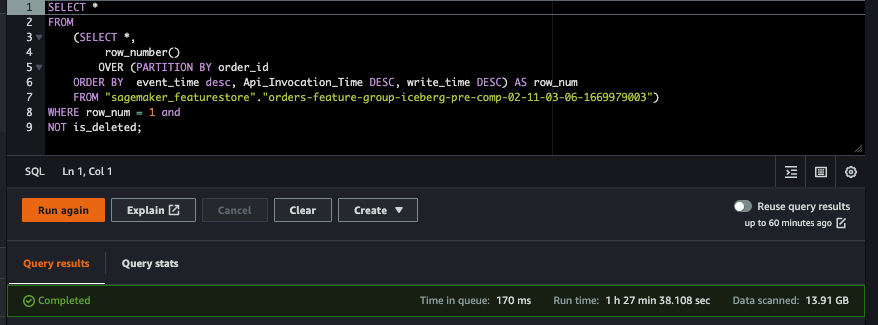
We then run compaction on orders-feature-group-iceberg-post-comp-03-14-05-17-1670076334 using the Athena OPTIMIZE query, which compacted the feature group table to 109,851 objects in Amazon S3 and a total size of 2.5 GiB. If we then run the same query after compaction, its runtime decreased to 1min 13sec.

With Iceberg file compaction, the query execution time improved significantly. For the same query, the run time decreased from 1h 27mins to 1min 13sec, which is 71 times faster.
Scheduling Iceberg compaction with AWS services
In this section, you will learn how to automate the table management procedures to compact your offline feature store. The following diagram illustrates the architecture for creating feature groups in Iceberg table format and a fully automated table management solution, which includes file compaction and cleanup operations.
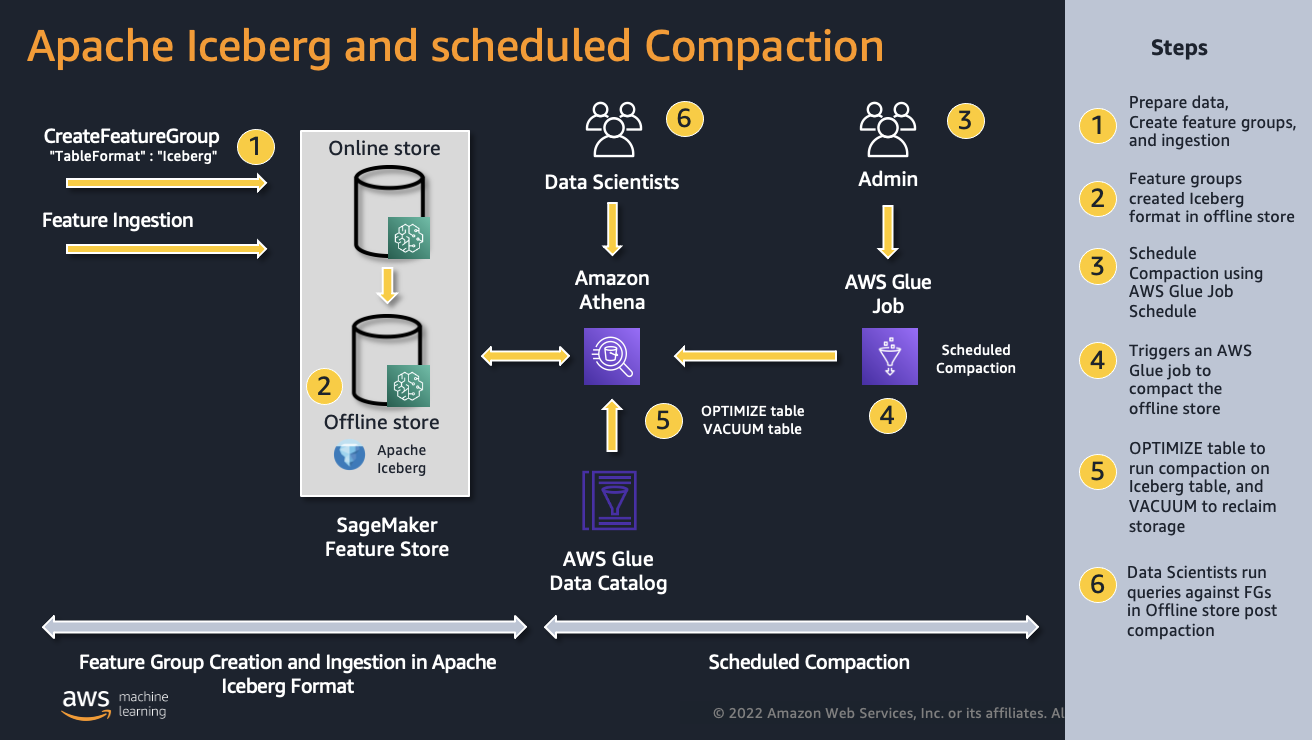
At a high level, you create a feature group using the Iceberg table format and ingest records into the online feature store. Feature values are automatically replicated from the online store to the historical offline store. Athena is used to run the Iceberg management procedures. To schedule the procedures, you set up an AWS Glue job using a Python shell script and create an AWS Glue job schedule.
AWS Glue Job setup
You use an AWS Glue job to execute the Iceberg table maintenance operations on a schedule. First, you need to create an IAM role for AWS Glue to have permissions to access Amazon Athena, Amazon S3, and CloudWatch.
Next, you need to create a Python script to run the Iceberg procedures. You can find the sample script in GitHub. The script will execute the OPTIMIZE query using boto3.
The script has been parametrized using the AWS Glue getResolvedOptions(args, options) utility function that gives you access to the arguments that are passed to your script when you run a job. In this example, the AWS Region, the Iceberg database and table for your feature group, the Athena workgroup, and the Athena output location results folder can be passed as parameters to the job, making this script reusable in your environment.
Finally, you create the actual AWS Glue job to run the script as a shell in AWS Glue.
- Navigate to the AWS Glue console.
- Choose the Jobs tab under AWS Glue Studio.
- Select Python Shell script editor.
- Choose Upload and edit an existing script. Click Create.
- The Job details button lets you configure the AWS Glue job. You need to select the IAM role you created earlier. Select Python 3.9 or the latest available Python version.
- In the same tab, you can also define a number of other configuration options, such as Number of retries or Job timeout. In Advanced properties, you can add job parameters to execute the script, as shown in the example screenshot below.
- Click Save.

In the Schedules tab, you can define the schedule to run the feature store maintenance procedures. For example, the following screenshot shows you how to run the job on a schedule of every 6 hours.

You can monitor job runs to understand runtime metrics such as completion status, duration, and start time. You can also check the CloudWatch Logs for the AWS Glue job to check that the procedures run successfully.

Executing Iceberg table management tasks with Spark
Customers can also use Spark to manage the compaction jobs and maintenance methods. For more detail on the Spark procedures, see the Spark documentation.
You first need to configure some of the common properties.
The following code can be used to optimize the feature groups via Spark.
You can then execute the next two table maintenance procedures to remove older snapshots and orphan files that are no longer needed.
You can then incorporate the above Spark commands into your Spark environment. For example, you can create a job that performs the optimization above on a desired schedule or in a pipeline after ingestion.
To explore the complete code example, and try it out in your own account, see the GitHub repo.
Conclusion
SageMaker Feature Store provides a purpose-built feature management solution to help organizations scale ML development across data science teams. In this post, we explained how you can leverage Apache Iceberg as a table format and table maintenance operations such as compaction to benefit from significantly faster queries when working with offline feature groups at scale and, as a result, build training datasets faster. Give it a try, and let us know what you think in the comments.
About the authors
 Arnaud Lauer is a Senior Partner Solutions Architect in the Public Sector team at AWS. He enables partners and customers to understand how best to use AWS technologies to translate business needs into solutions. He brings more than 17 years of experience in delivering and architecting digital transformation projects across a range of industries, including public sector, energy, and consumer goods. Arnaud holds 12 AWS certifications, including the ML Specialty Certification.
Arnaud Lauer is a Senior Partner Solutions Architect in the Public Sector team at AWS. He enables partners and customers to understand how best to use AWS technologies to translate business needs into solutions. He brings more than 17 years of experience in delivering and architecting digital transformation projects across a range of industries, including public sector, energy, and consumer goods. Arnaud holds 12 AWS certifications, including the ML Specialty Certification.
 Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience mostly in software architecture design and cloud engineering.
Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience mostly in software architecture design and cloud engineering.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
 Brandon Chatham is a software engineer with the SageMaker Feature Store team. He’s deeply passionate about building elegant systems that bring big data and machine learning to people’s fingertips.
Brandon Chatham is a software engineer with the SageMaker Feature Store team. He’s deeply passionate about building elegant systems that bring big data and machine learning to people’s fingertips.