Scaling LLM Post-Training at Netflix
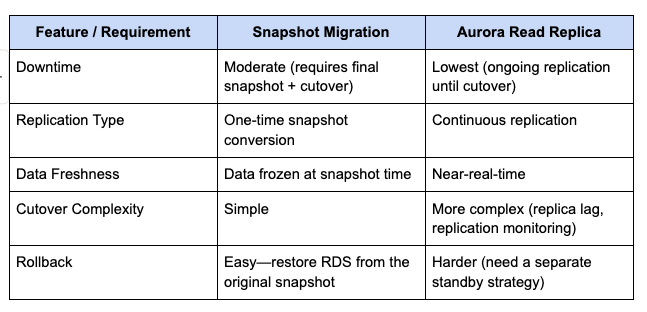
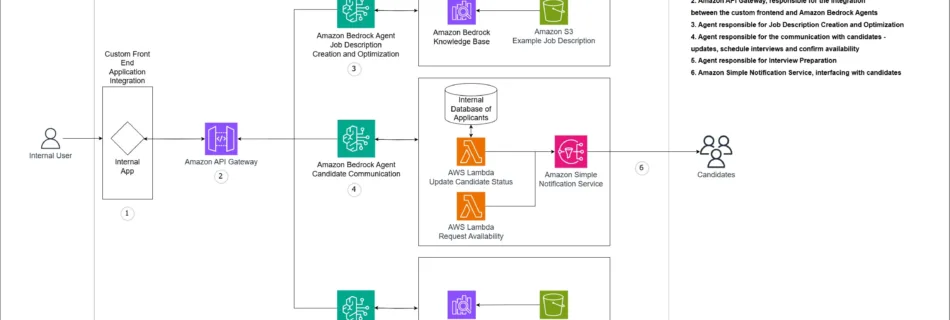
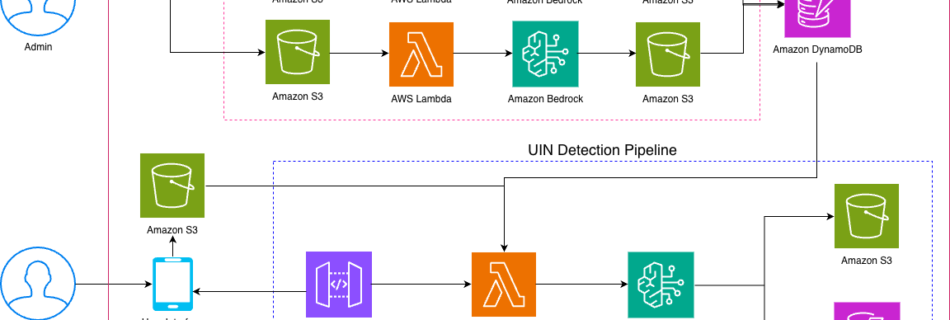
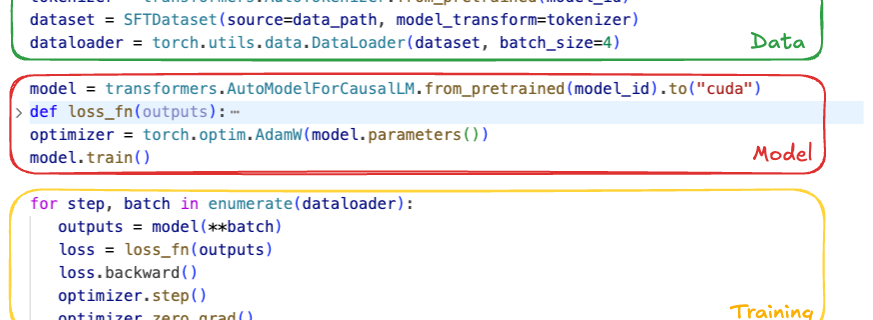
Baolin Li, Lingyi Liu, Binh Tang, Shaojing Li Introduction Pre-training gives Large Language Models (LLMs) broad linguistic ability and general world knowledge, but post-training is the phase that actually aligns them to concrete intents, domain constraints, and the reliability requirements of production environments. At Netflix, we are exploring how LLMs can enable new member experiences across …