

A grand vision in robot learning, going back to the SHRDLU experiments in the late 1960s, is that of helpful robots that inhabit human spaces and follow a wide variety of natural language commands. Over the last few years, there have been significant advances in the application of machine learning (ML) for instruction following, both in simulation and in real world systems. Recent Palm-SayCan work has produced robots that leverage language models to plan long-horizon behaviors and reason about abstract goals. Code as Policies has shown that code-generating language models combined with pre-trained perception systems can produce language conditioned policies for zero shot robot manipulation. Despite this progress, an important missing property of current “language in, actions out” robot learning systems is real time interaction with humans.
Ideally, robots of the future would react in real time to any relevant task a user could describe in natural language. Particularly in open human environments, it may be important for end users to customize robot behavior as it is happening, offering quick corrections (“stop, move your arm up a bit”) or specifying constraints (“nudge that slowly to the right”). Furthermore, real-time language could make it easier for people and robots to collaborate on complex, long-horizon tasks, with people iteratively and interactively guiding robot manipulation with occasional language feedback.
 |
| The challenges of open-vocabulary language following. To be successfully guided through a long horizon task like “put all the blocks in a vertical line”, a robot must respond precisely to a wide variety of commands, including small corrective behaviors like “nudge the red circle right a bit”. |
However, getting robots to follow open vocabulary language poses a significant challenge from a ML perspective. This is a setting with an inherently large number of tasks, including many small corrective behaviors. Existing multitask learning setups make use of curated imitation learning datasets or complex reinforcement learning (RL) reward functions to drive the learning of each task, and this significant per-task effort is difficult to scale beyond a small predefined set. Thus, a critical open question in the open vocabulary setting is: how can we scale the collection of robot data to include not dozens, but hundreds of thousands of behaviors in an environment, and how can we connect all these behaviors to the natural language an end user might actually provide?
In Interactive Language, we present a large scale imitation learning framework for producing real-time, open vocabulary language-conditionable robots. After training with our approach, we find that an individual policy is capable of addressing over 87,000 unique instructions (an order of magnitude larger than prior works), with an estimated average success rate of 93.5%. We are also excited to announce the release of Language-Table, the largest available language-annotated robot dataset, which we hope will drive further research focused on real-time language-controllable robots.
| Guiding robots with real time language. |
Real Time Language-Controllable Robots
Key to our approach is a scalable recipe for creating large, diverse language-conditioned robot demonstration datasets. Unlike prior setups that define all the skills up front and then collect curated demonstrations for each skill, we continuously collect data across multiple robots without scene resets or any low-level skill segmentation. All data, including failure data (e.g., knocking blocks off a table), goes through a hindsight language relabeling process to be paired with text. Here, annotators watch long robot videos to identify as many behaviors as possible, marking when each began and ended, and use freeform natural language to describe each segment. Importantly, in contrast to prior instruction following setups, all skills used for training emerge bottom up from the data itself rather than being determined upfront by researchers.
Our learning approach and architecture are intentionally straightforward. Our robot policy is a cross-attention transformer, mapping 5hz video and text to 5hz robot actions, using a standard supervised learning behavioral cloning objective with no auxiliary losses. At test time, new spoken commands can be sent to the policy (via speech-to-text) at any time up to 5hz.
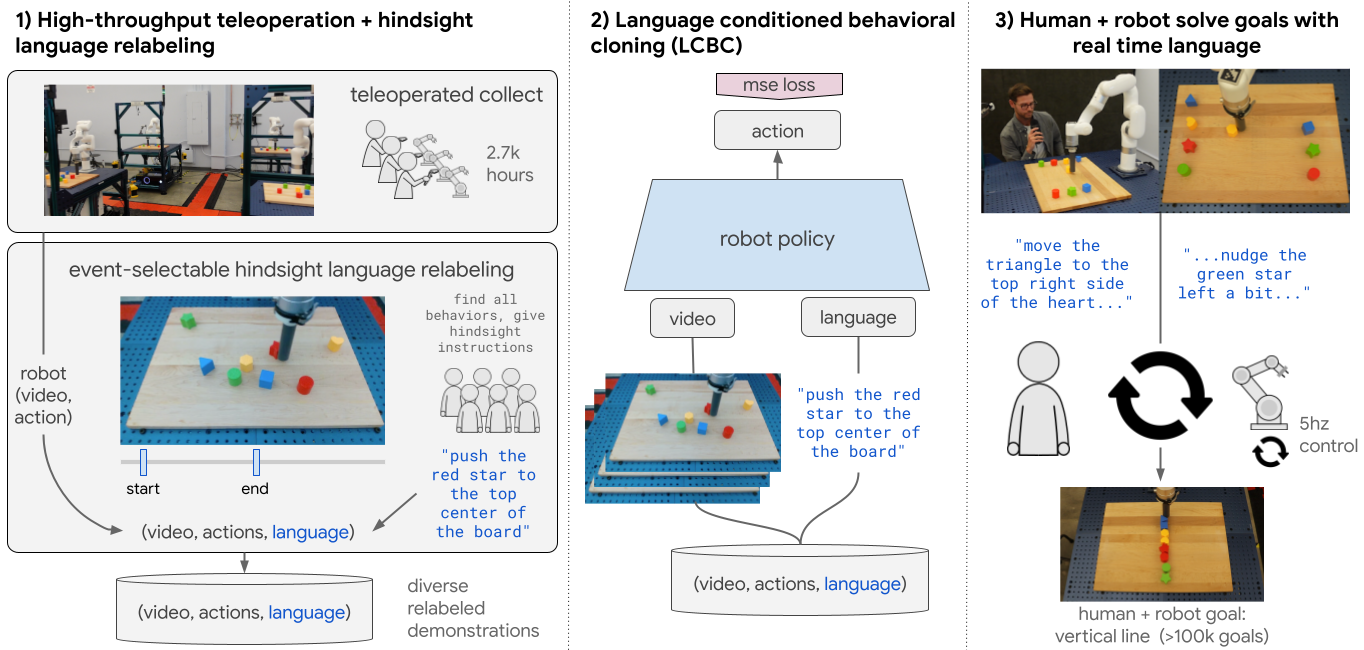 |
| Interactive Language: an imitation learning system for producing real time language-controllable robots. |
Open Source Release: Language-Table Dataset and Benchmark
This annotation process allowed us to collect the Language-Table dataset, which contains over 440k real and 180k simulated demonstrations of the robot performing a language command, along with the sequence of actions the robot took during the demonstration. This is the largest language-conditioned robot demonstration dataset of its kind, by an order of magnitude. Language-Table comes with a simulated imitation learning benchmark that we use to perform model selection, which can be used to evaluate new instruction following architectures or approaches.
| Dataset | # Trajectories (k) | # Unique (k) | Physical Actions | Real | Available |
| Episodic Demonstrations | |||||
| BC-Z | 25 | 0.1 | ✓ | ✓ | ✓ |
| SayCan | 68 | 0.5 | ✓ | ✓ | ❌ |
| Playhouse | 1,097 | 779 | ❌ | ❌ | ❌ |
| Hindsight Language Labeling | |||||
| BLOCKS | 30 | n/a | ❌ | ❌ | ✓ |
| LangLFP | 10 | n/a | ✓ | ❌ | ❌ |
| LOREL | 6 | 1.7 | ✓ | ✓ | ✓ |
| CALVIN | 20 | 0.4 | ✓ | ❌ | ✓ |
| Language-Table (real + sim) | 623 (442+181) | 206 (127+79) | ✓ | ✓ | ✓ |
| We compare Language-Table to existing robot datasets, highlighting proportions of simulated (red) or real (blue) robot data, the number of trajectories collected, and the number of unique language describable tasks. |
Learned Real Time Language Behaviors
 |
| Examples of short horizon instructions the robot is capable of following, sampled randomly from the full set of over 87,000. |
| Short-Horizon Instruction | Success |
| (87,000 more…) | … |
| push the blue triangle to the top left corner | 80.0% |
| separate the red star and red circle | 100.0% |
| nudge the yellow heart a bit right | 80.0% |
| place the red star above the blue cube | 90.0% |
| point your arm at the blue triangle | 100.0% |
| push the group of blocks left a bit | 100.0% |
| Average over 87k, CI 95% | 93.5% +- 3.42% |
| 95% Confidence interval (CI) on the average success of an individual Interactive Language policy over 87,000 unique natural language instructions. |
We find that interesting new capabilities arise when robots are able to follow real time language. We show that users can walk robots through complex long-horizon sequences using only natural language to solve for goals that require multiple minutes of precise, coordinated control (e.g., “make a smiley face out of the blocks with green eyes” or “place all the blocks in a vertical line”). Because the robot is trained to follow open vocabulary language, we see it can react to a diverse set of verbal corrections (e.g., “nudge the red star slightly right”) that might otherwise be difficult to enumerate up front.
 |
| Examples of long horizon goals reached under real time human language guidance. |
Finally, we see that real time language allows for new modes of robot data collection. For example, a single human operator can control four robots simultaneously using only spoken language. This has the potential to scale up the collection of robot data in the future without requiring undivided human attention for each robot.
 |
| One operator controlling multiple robots at once with spoken language. |
Conclusion
While currently limited to a tabletop with a fixed set of objects, Interactive Language shows initial evidence that large scale imitation learning can indeed produce real time interactable robots that follow freeform end user commands. We open source Language-Table, the largest language conditioned real-world robot demonstration dataset of its kind and an associated simulated benchmark, to spur progress in real time language control of physical robots. We believe the utility of this dataset may not only be limited to robot control, but may provide an interesting starting point for studying language- and action-conditioned video prediction, robot video-conditioned language modeling, or a host of other interesting active questions in the broader ML context. See our paper and GitHub page to learn more.
Acknowledgements
We would like to thank everyone who supported this research. This includes robot teleoperators: Alex Luong, Armando Reyes, Elio Prado, Eric Tran, Gavin Gonzalez, Jodexty Therlonge, Joel Magpantay, Rochelle Dela Cruz, Samuel Wan, Sarah Nguyen, Scott Lehrer, Norine Rosales, Tran Pham, Kyle Gajadhar, Reece Mungal, and Nikauleene Andrews; robot hardware support and teleoperation coordination: Sean Snyder, Spencer Goodrich, Cameron Burns, Jorge Aldaco, Jonathan Vela; data operations and infrastructure: Muqthar Mohammad, Mitta Kumar, Arnab Bose, Wayne Gramlich; and the many who helped provide language labeling of the datasets. We would also like to thank Pierre Sermanet, Debidatta Dwibedi, Michael Ryoo, Brian Ichter and Vincent Vanhoucke for their invaluable advice and support.