
Developers seeking to leverage the power of machine learning (ML) on their PostgreSQL data often find themselves grappling with complex integrations and steep learning curves. Cloud SQL for PostgreSQL now bridges this gap, allowing you to tap into cutting-edge ML models and vector generation techniques offered by Vertex AI, directly within your SQL queries. Now, you can easily generate vectors from textual data, perform efficient search over a large corpus of vectors, and fetch real-time predictions to drive intelligent applications and reduce operational complexity.
This blog expects a basic understanding of embeddings and vectors as used in ML. Refer to Vertex AI documentation for more information.
Cloud SQL for PostgreSQL’s google_ml_integration extension
The google_ml_integration extension provides a bridge to Google’s Vertex AI platform, enabling you to invoke ML models directly within your SQL environment. You can generate text embeddings for semantic analysis, perform real-time predictions, and leverage the vast knowledge and understanding of LLMs, all from within the comfort of your Cloud SQL for PostgreSQL database.
The Vertex AI integration provided by the google_ml_integration extension eliminates the need for any external pipelines to connect Cloud SQL for PostgreSQL instances to Vertex AI. This greatly simplifies embedding generation during long-running vector index generation and in transactional vector search queries.
Jump to the Sample Application section of this blog for instance setup instructions.
PostgreSQL’s pgvector extension
The pgvector extension adds support for vector types along with various Approximate Nearest Neighbour (ANN) index types such as IVFFLAT and HNSW. These allow you to design a vector store that is optimized for efficiency, speed, recall and performance. For more details refer to our previous blog post where we covered this in depth.
AI-powered apps with pgvector + google_ml_integration
Our earlier blog (and corresponding Colab) demonstrated building AI-enabled applications using Vertex AI and pgvector. Now, google_ml_integration further simplifies the development and maintenance of these applications, by removing the need for external pipelines to integrate your database with LLMs for embedding generation during indexing and search, all with the familiarity and transactional guarantees of SQL. Some of the key benefits that we demonstrate are:
Simplified application architecture, by eliminating the application-side “glue” to integrate Vertex AI
Faster development time
Easier index creation and maintenance through generated columns and integrated embedding generation
Better transactional guarantees in search queries utilizing embeddings generated by Vertex AI
Simplified control flow with native integration with Vertex AI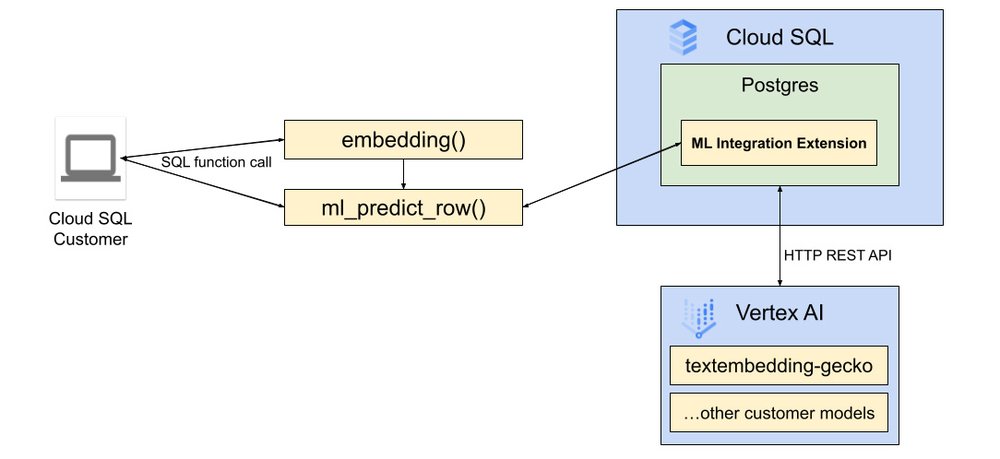
Building the sample application
The following sections give step-by-step instructions to build an application with pgvector and LLMs using the Vertex AI integration.
Enable database integration with Vertex AI
You need to create/patch a Cloud SQL for PostgreSQL instance with google_ml_integration extension.
--enable-google-ml-integrationto enable this feature–database-flags cloudsql.enable-google-ml-integration=onto enable the PostgreSQL extension
Grant the Cloud SQL service account Identity and Access Management (IAM) permissions to access Vertex AI. The relevant IAM role is aiplatform.user, and these changes may take up to five minutes to propagate.
Connect to the instance and install the google_ml_integration extension in a database of the primary Cloud SQL instance. This database contains data on which you want to run predictions.
- code_block
- <ListValue: [StructValue([(‘code’, ‘postgres=> CREATE EXTENSION IF NOT EXISTS google_ml_integration;rnpostgres=> CREATE EXTENSION IF NOT EXISTS vector;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3efa61769910>)])]>
Once the above steps are complete, you can start using the embedding and ml_predict_row methods to get text embeddings/predictions from Vertex AI and store/search them in the database
Loading the ‘toy’ dataset
Our earlier blog on building AI-powered apps with PostgreSQL and LLMs has covered this in detail in the “Loading our ‘toy’ dataset” section. Please follow the instructions there before proceeding.
Generating the vector embeddings using Vertex AI integration
We use the Vertex AI Text Embedding model to generate the vector embeddings. The following examples demonstrate embedding generation from a familiar SQL interface. google_ml_integration transparently handles integration with Vertex AI models, error handling and type conversion — all with the expressive power of SQL and ACID guarantees you get from PostgreSQL.
- code_block
- <ListValue: [StructValue([(‘code’, “– Generate embeddings for an input textrnpostgres=> SELECT embedding(‘textembedding-gecko@003’, ‘Hello world’);rn{0.046892364,-0.040321123,-0.028917024,-0.026512414,0.0..}t– Returns an embedding with 768 floating point values, representing a vector of this modelrnrn– Cosine distancernpostgres=> SELECTrn embedding(‘textembedding-gecko@003’, ‘Toys’)::vector <=> embedding(‘textembedding-gecko@003’, ‘LLM’)::vector as dissimilar_cosine_distance,rn embedding(‘textembedding-gecko@003’, ‘ML’)::vector <=> embedding(‘textembedding-gecko@003’, ‘LLM’)::vector as similar_cosine_distance;rn dissimilar_cosine_distance | similar_cosine_distancern—————————-+————————-rn 0.4000950696407375 | 0.17603338703224614rn(1 row)”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3efa61769a00>)])]>
Now, let’s demonstrate generating embeddings for the text that describes various toys in our products table. We add a new column to the existing products table which will be used to store the embeddings, and a generated-column expression utilizing the Vertex AI integration to automatically compute the embeddings behind-the-scenes. This provides a convenient mechanism with which to populate the embeddings and keep them in sync as your data evolves. We also create an HNSW index, a powerful ANN index type provided by the pgvector extension that allows for efficient search of similar vectors.
- code_block
- <ListValue: [StructValue([(‘code’, “postgres=> ALTER TABLE productsrn ADD COLUMN description_embeddings Vector(768) rn GENERATED ALWAYS AS (embedding(‘textembedding-gecko@003’, LEFT(description, 2000))) STORED;rnALTER TABLErnrnpostgres=> CREATE INDEX ON productsrnUSING hnsw(description_embeddings vector_cosine_ops)rnWITH (m = 24, ef_construction = 100);rnCREATE INDEX”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3efa617694c0>)])]>
At publication, the Vertex AI Text Embedding model only accepts 3,072 input tokens in a single API request. Therefore, we will truncate long product descriptions to 2000 characters. We can also split full descriptions into right-sized bytes and store each chunk as a row in a separate embeddings table. However, for the purpose of this demonstration, let’s stick to the simpler example mentioned above.
Finding similar toys using pgvector search operator
pgvector supports multiple distance functions, namely:
Euclidean distance (<->)
Cosine distance (<=>)
We can generate vector embeddings for a natural-language search query, and perform efficient ANN search using these similarity search operators to find related products, all within a single SQL statement! The following examples use the cosine distance function to find products matching the semantic meaning of a query (such as returning card games and miniature table-top games for an input query “indoor games”). Refer to our earlier blog on pgvector for more examples of efficient ANN search.
- code_block
- <ListValue: [StructValue([(‘code’, ‘– Find products matching “Indoor games”rnpostgres=> SELECTrn LEFT(product_name, 40) AS product_name,rn LEFT(description, 40) AS description, rn 1 – (description_embeddings <=> embedding(‘textembedding-gecko@003’, ‘Toys for outdoors’)::Vector) AS similarityrn ROUND(CAST(1 – (description_embeddings <=> embedding(‘textembedding-gecko@003’, ‘Toys for outdoors’)::Vector) AS NUMERIC), 3) AS similarityrnFROMrn products prnORDER BY similarity DESCrnLIMIT 3;rn product_name | description | similarityrn——————————————+——————————————+——————–rn Pre Packed Beach Toy Buckets – Toys – Ac | Pre Packed Beach Toy Buckets – Toys – Ac | 0.773rn Itza Sand Boat | Ideal for backyard, pool and beach activ | 0.725rn Outdoor Sport Beach Sand Mold/ Snow Ball | These toys will help to make snowball in | 0.715rn(3 rows)rnrn– Combine semantic-similarity with SQL predicates to create powerful queriesrnpostgres=> SELECT rn LEFT(product_name, 40) AS product_name,rn LEFT(description, 40) AS description, rn ROUND(CAST(1 – (description_embeddings <=> embedding(‘textembedding-gecko@003’, ‘Toys for outdoors’)::Vector) AS NUMERIC), 3) AS similarityrnFROMrn products prnWHERErn (1 – (description_embeddings <=> embedding(‘textembedding-gecko@003’, ‘Indoor games’)::Vector)) > ‘0.65’ t– Similarity quality thresholdrn AND list_price < 50.0rnORDER BY similarity DESCrnLIMIT 3;rn product_name | description | similarityrn———————————-+——————————————+——————–rn Space Pinball Games | 72 Space Pinball Games. Blast off to out | 0.648rn Grabolo Games Category | Grabolo Games Category | 0.602rn Way To Celebrate 6 Pinball Games | Take one of these Mini Pinball Games an | 0.570rn(3 rows)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3efa61769610>)])]>
The above code snippets showcase some simple examples of integrating with Vertex AI and generating embeddings. However, the embedding and ml_predict_row methods go beyond simple embedding generation – you can classify text, invoke predictions, perform sentiment analysis, generate text from prompts and much more through the power of a rapidly-expanding portfolio of LLMs. These can further be encapsulated in SQL UDFs to provide a simple interface customized for your business domain.
Summary
Explore our Vertex AI Colabs on text embeddings and text classification to dive deeper, or check out our complete library of Colabs.