Manual document classification and extraction is still a time-consuming and difficult task for many organizations. This blog series aims to demonstrate how Google Cloud products like Document AI and BigQuery can be used together to help organizations eliminate manual document processing.
In the first part of this blog series, we discussed how to digitize grocery receipts from supermarkets and analyze spending patterns using Google Cloud services. In that blog, we focused on a fictional supermarket called X and learned how to digitize their receipts. In this second part of the series, we will expand the scope of the problem and learn how to digitize receipts from any supermarket in the world.
In this next installment of the blog series, we will learn how to automatically classify different supermarket receipts using the Document AI custom classifier processor. We will then learn how to use Google Cloud Functions (Gen2) with triggers to automate the classification of receipts as soon as they are uploaded to Google Cloud storage.
Digitizing this information allows you to analyze the data and gain insights into your spending habits. This can help you identify areas where you can save money, such as by purchasing generic brands instead of name brands or buying in bulk. With this powerful combination of Google Cloud technologies, you can turn your receipts into a valuable data source that can help you save money and make smarter purchasing decisions.
To illustrate, let’s assume that there are several supermarkets in your neighborhood, such as Supermarket X, Supermarket Y, and Supermarket Z, each with its own unique invoice format. The first issue here is to classify the different types of supermarket invoices so that they can be parsed using the custom processors described in part one of this blog series.
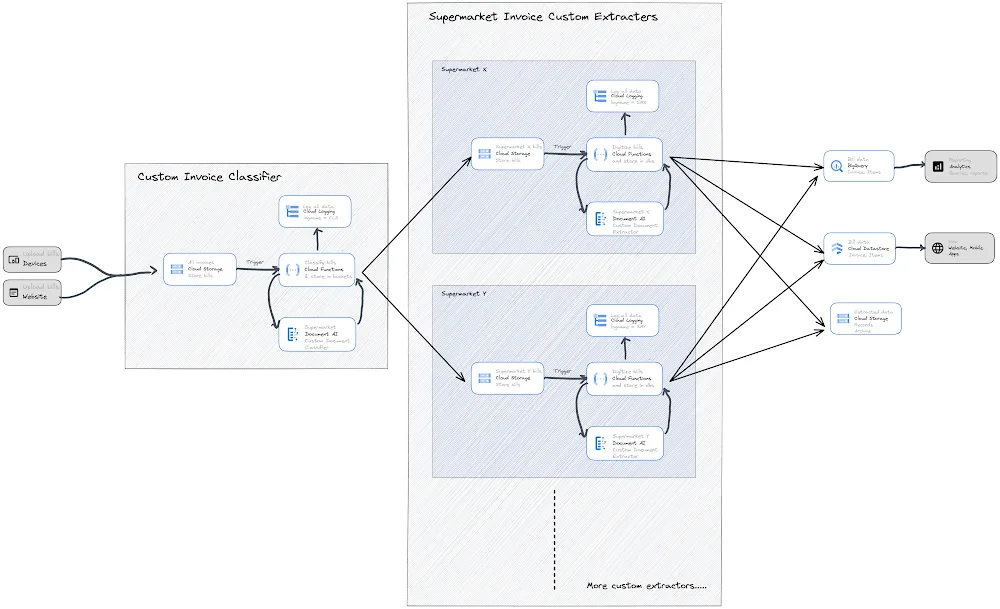
The following is a visual representation of the architecture:
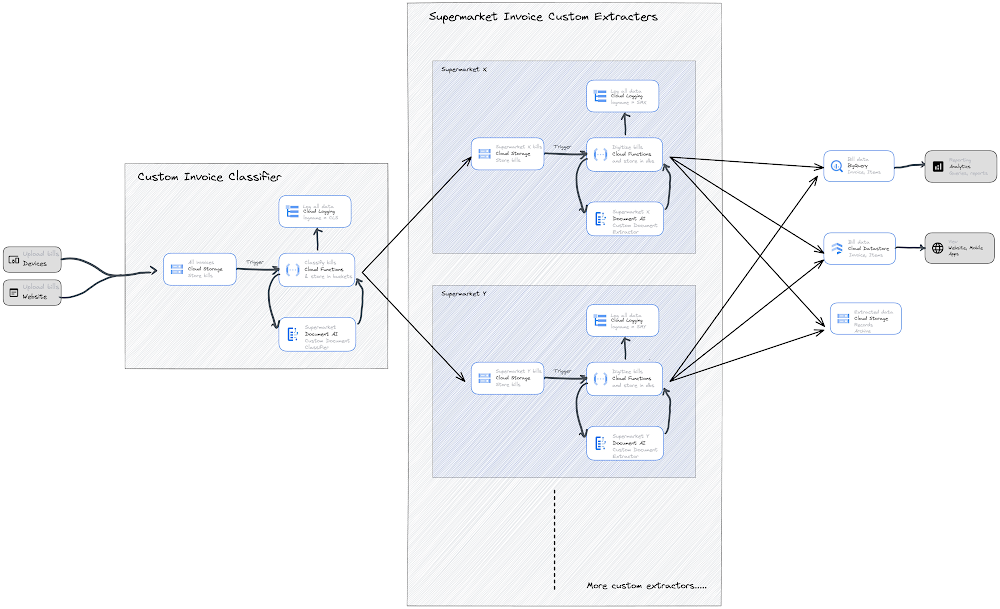
This blog will discuss how to classify different types of supermarket invoices and place them in different cloud storage buckets so that they can be automatically processed by their individual cloud functions. If all supermarket custom extractors use the same processor schema (as described in part one of this blog series), they will all run the same code and be able to write to the same table in BigQuery and Datastore.If custom extractors do not use the defined schema, Cloud Functions will need to write the extracted data from invoices to different tables in BigQuery. In this case, materialized views can be built to visualize the data from these different tables.
The benefits of the above architecture are:
It automates every step, from users uploading supermarket invoices to digitizing them.
Custom extractors can be maintained and developed independently. They can follow the same schema or a separate schema based on needs.
All Cloud Functions write logs with custom log names, which allows us to identify issues quickly.
Here are the steps to classify different types of supermarket invoices and upload them to their individual cloud storage buckets:
1. If you haven’t already, set up a Google Cloud account with Starter Checklist.
2. Set up Document AI Custom Document Classifier:
a. This guide describes how to use Document AI Workbench to create and train a Custom Document Classifier that classifies invoices from different supermarkets.
b. Follow the guide to create a custom classifier that can classify invoices from the supermarkets you visit most often. We observed an average of 20 receipts from each supermarket are needed for training and testing the classification model.
c. The processor schema should be as shown in the image below. Add labels as required. Labels should be clearly defined and unique to each supermarket. For clarity, it is best to name labels after supermarket names.
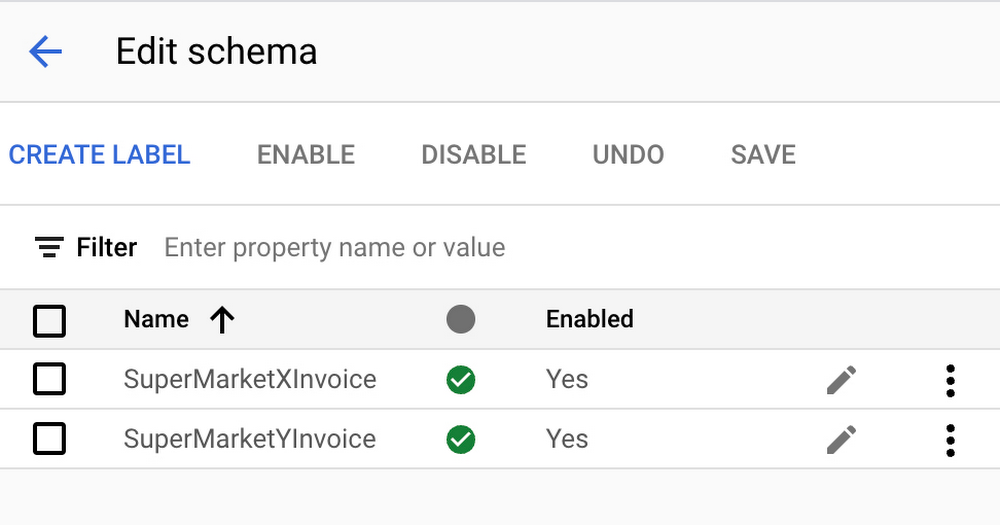
d. This custom document classifier processor will be used in Cloud Functions to identify the type of invoice uploaded by users via a web or mobile app.
3. Set up Google Cloud Storage: Follow this documentation and create a storage bucket to store uploaded bills from the user.
4. Set up Google Cloud Function:
a. For instructions on how to create a second-generation Cloud Function with Eventarc trigger that will be activated when a new object is added to the cloud storage created in step 3, please see this documentation.
b. When creating the function, make sure that “Allow internal traffic and traffic from Cloud Load Balancing” is selected in the network settings.
c. When adding an Eventarc trigger, choose the “google.cloud.storage.object.v1.finalized” event type.
d. It is recommended to create a new service account instead of using the “Default Compute Service Account” when creating Eventarc. The new service account should be granted the “Cloud Run Invoker” and “Eventarc Event Receiver” permissions.
e. When creating a Cloud Function, do not use the “Default Compute Service Account” as the “Runtime service account”. Instead, create a new one and grant it the following roles to allow it to connect to DataStore, BigQuery, Logging, and Document AI: BigQuery Data Owner, Cloud Datastore User, Document AI API User, Logs Writer, Storage Object Creator, and Storage Object Viewer.
f. Once done, service accounts and permissions should appear as follows:

g. Next, open the Cloud Function you created and select .NET 6.0 as the runtime. This will allow you to write C# functions.
h. To ensure a successful build, replace the current code in the Cloud Function with this code, replacing the variables in the code with the appropriate Google Cloud service names. Replace content in HelloGcs.csproj and Function.cs files.
i. Deploy the Cloud Function.
5. Testing:
a. To test the application, upload a supermarket bill to the same cloud storage bucket that you created in step 3 and configured to “Receive events from” in Eventarc in step 4.
b. When a supermarket bill is uploaded to blob storage in step 3, the cloud function in step 4 is triggered. The cloud function calls the Document AI custom classifier (created in step 2) endpoint and classifies the invoice based on the model’s response. The cloud function then stores the file in a cloud bucket dedicated to that supermarket’s files.
c. If you have built the architecture in part one of this blog series, then ensure that the cloud storage bucket is the source storage bucket. This will trigger another cloud function that will extract information from the invoice according to the defined schema and write it to BigQuery, Datastore, and Cloud Storage simultaneously.
Alternate Take:
Another option is to use Google Pub/sub and one Cloud Function to classify and process all invoices.
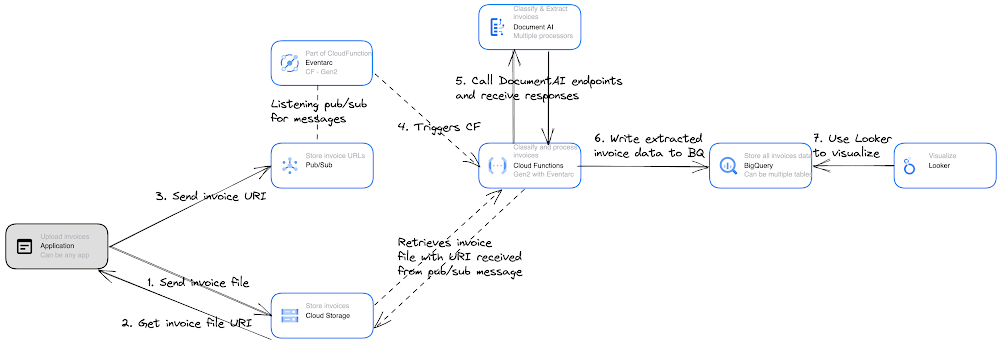
In this approach, all uploaded invoices are stored in cloud storage and their reference URLs are queued into pub/sub as messages for processing. Eventarc supports the “google.cloud.pubsub.topic.v1.messagePublished” event. So, when a new message is written to pub/sub, a Gen2 cloud function is triggered that can read the message that contains the invoice URI in cloud storage.CloudFunction then uses the URI to retrieve the invoice from Cloud Storage, classifies it, extracts the data, and then writes it to any of Google Storage options. The only problem with this approach is that having a single cloud function to process all types of invoices can be difficult to manage. This works best if the supermarket custom extractors discussed in part one of the blog series use the same processor schema to extract any supermarket invoice.
Summary:
The first part of the blog described an architecture that digitizes a single supermarket’s invoice, which has its own unique format, using Google Cloud services such as DocumentAI, Cloud Functions (Gen2), BigQuery, Datastore, and Cloud Storage. This second part of the blog expands the scope of the architecture to discuss one where any invoice from any supermarket in the world can be taken as input, classified first using DocumentAI, and then processed as discussed in part one.
Congratulations on digitizing every supermarket receipt in the world! This method can be applied to any document processing use case in any industry.
Before you go, check out Google Cloud’s tutorials and samples to learn more about use cases like these.