
Operational Security: Enabling transparency, collaboration, and privacy (Palantir RFx Blog Series, #5)
Organizations should look beyond traditional functional security requirements to identify security features that enable transparency and collaboration, rather than hamper them.
Editor’s note: This is the fifth post in the Palantir RFx Blog Series, which explores how organizations can better craft RFIs and RFPs to evaluate digital transformation software. Each post focuses on one key capability area within a data ecosystem, with the goal of helping companies ask the right questions to better assess technology. Previous installments have included posts on Ontology, Data Connection, Version Control, and Interoperability.

Introduction
We founded Palantir to address what we believed to be a false dichotomy. In the wake of 9/11, many believed that strengthening national security in the United States also meant weakening privacy protections. Preventing terrorist attacks, as the thinking went, required increased levels of government surveillance. We rejected this approach with the understanding that it is possible to build software that supports counterterrorism missions while protecting our privacy and civil liberties. By building privacy-protective features into our products by design, we sought to enable a new paradigm for U.S. counterterrorism and other critical government workflows. Today, these technologies facilitate responsible data processing for our government customers in accordance with relevant laws, regulations, and policies.
In the private sector, as more companies have adopted our software over time, we’ve come across a number of related false tradeoffs. One of them is the need to balance data security and data transparency. IT departments often approach this as a zero-sum challenge, where sharing data more broadly within the organization will improve productivity but also increase the attack surface for potential data breaches. This “tradeoff” is especially challenging within highly regulated industries such as banking and healthcare, where data ecosystems must adhere to stringent laws and regulations. Organizations often conclude they must lock down and silo their data, establishing onerous controls at the expense of permissable cross-team collaboration and productivity.

Drawing on lessons learned from our government work, we have helped commercial enterprises deploy software that enables modern data protection and governance postures across complex data landscapes. The software capabilities include data minimization, accountable data usage, and data retention and deletion handling that collectively increases organizational confidence and trust in the data ecosystem to enable rather than hamper data sharing and collaboration.
Unfortunately, despite significant developments in software capabilities, many organizations unwittingly set low bars for their security requirements in RFPs. They repeat outdated security standards and requirements, missing opportunities to evaluate differentiated security capabilities that promote collaboration while adhering to the organization’s security profile.
This blog post explores these capabilities and suggests how to best structure and evaluate functional security requirements in ways that also increase transparency, collaboration, and data sharing across the organization.
How do RFXs evaluate software security?
Security requirements in RFXs typically address three kinds of security features:
- Corporate Security: Are the people and facilities of the vendor documented and trustworthy? Are the supply chains resilient and reliable?
- Infrastructure Security: Is the underlying infrastructure of the software solution secured by encryption, penetration testing, network safeguards, etc.?
- Operational Security: What controls does the software platform provide to enforce data security across all users and system connections?
We focus the topic of this blog post on the third category above: Operational Security. While corporate and infrastructure security are also critical considerations when choosing which vendors to work with in establishing a data ecosystem, they are beyond the scope of this article.
Operational security requirements typically include a list of standard features related to access controls, authentication, and authorization (e.g., does the solution support authorization via role-based access controls (RBAC)? Does the solution support authentication via Lightweight Directory Access Protocol (LDAP)? Does the solution provide an interface to manage security controls?). While these are essential features of a data ecosystem solution, they generally lack the flexibility and sophistication to actively enable the levels of data transparency and collaboration that modern enterprises demand.
One common example of where operational security requirements often fall short concerns role-based access controls (RBAC). Most data systems include RBAC features, but they are often clunky and rigid, forcing administrators to define permissions for entire groups. Data owners must then lock down access to key data sources for fear of oversharing to the wrong users. Other data systems make granular access controls available to administrators and data owners but lack an intuitive interface that enables legibility and maintainability. Again, the end result is data owners (understandably) biasing towards the low-risk posture of locking down data access.
Below, we explore how organizations can specify security requirements that increase both data security and transparency across an organization.
What differentiates best in class operational security capabilities?
The most effective data ecosystems are widely adopted because they enable data access and collaboration in a secure way. Ultimately, user adoption and system impact are dependent on trust; users and user groups contribute new artifacts with the understanding that these products (and derived products) will be appropriately accessed downstream. IT teams and system administrators will manage and maintain the system in confidence to match the organization’s risk profile and regulatory requirements.
One critical element of establishing this trust is the ability to maintain data control and transparency over time. Individuals who are accountable for resources, such as data owners or team leads, need to be able to control how resources are shared both today and in the future as those resources are accessed, analyzed, and transformed for other purposes. Previous paradigms — of files being shared over email and then control is lost forever — are no longer appropriate. Security policies must travel with the data.
At a high level, this posture of trust is made possible by three overarching capabilities: strict enforcement, granular controls, and transparency.
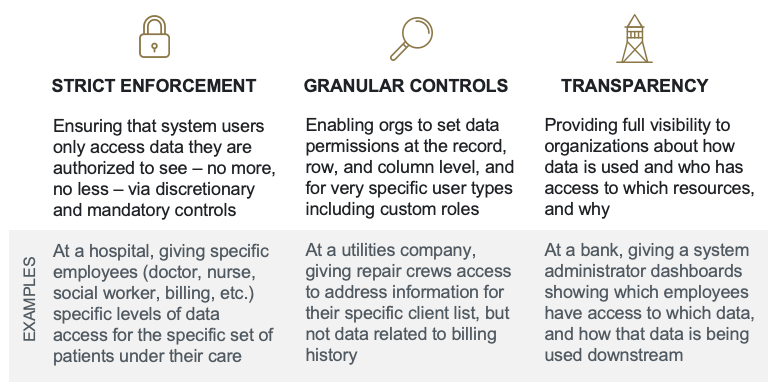
Strict enforcement means that system users can only access data they are authorized to see. To achieve strict enforcement, organizations have traditionally focused on discretionary access controls, where project owners are responsible for managing access to data and projects. Increasingly, organizations are also implementing mandatory access controls, in which access to resources are controlled centrally by the operating system itself and a system administrator. Mandatory access controls are considered to be the strictest version of enforcement, often via the deployment of security markings (or just “markings”) which provide data categorization labels to define what users can see and do with the data. These labels propagate everywhere the data is used, ensuring that restrictions are enforced on both the data itself and any downstream artifacts/transformations based on the top-level data.
Granular controls allow organizations to assign data access permissions to system users in a flexible and precise manner. This granularity applies to both the data (organizations can specify permissions down to the column/row level) and to the user accessing the data (organizations can specify permissions for individual users, not just teams or broad user groups). Oftentimes, organizations require very specific permissions to be applied to certain object types — like when a bank wants to restrict employee data access only to customers at a particular branch. Thus, the solution should provide a user interface that lets administrators limit access to only the specific rows that a specific user has permission to see. For more information about how Palantir approaches these capabilities, see this documentation on Restricted Views in Palantir Foundry.
Transparency enables users to understand who has access to which resources and why. In modern enterprises, organizations typically use many disparate systems that contain critical or sensitive data, and decision makers at these organizations need to draw upon this information to make business-critical decisions. This creates an acute challenge for data governance teams. Tracking who has access to what information and why, across thousands of datasets and thousands of users, quickly becomes an exceptionally complex problem. In order to protect the privacy of the individuals whose personal information is represented within the data, data governance teams must ensure that users only have access to sensitive or personal data when strictly necessary. This challenge grows exponentially as organizational scale.
To properly track who has access to which data, organizations should follow a purpose-based access control model. Instead of applying for access to an individual data set, data ecosystems can enable users to request data access based on a purpose. The purpose can be set by data governance teams to contain data specifically scoped to help the user meet their goal — no more, no less. The solutions can be configured to require every user to apply to a purpose, and they only have access to the data that’s been assigned to that purpose. The solution should enable data governance teams to record rationales for their decisions at the same time they grant a user access to data. Purpose justifications should be captured for data governance reviews, enabling auditors to understand not just who has access to what data, but also why they were given access — with all the context that went into that decision. For more information about purpose-based access controls, see this blog post and the Checkpoints section of Foundry’s product documentation.
Requirements
With these principles in mind, we suggest incorporating the following security requirements in RFXs to identify best in class solutions.
The solution must provide an accessible and intuitive user interface to configure and manage data permissions. The ability to implement, manage, and edit security permissions is paramount. Any friction related to accessibility, availability, or usability can have major consequences for system users and the organization as a whole. The UI should be quick to access, easy to use, and readily observable in a live demonstration of the platform. From the UI, administrators should be able to build, test, implement, and manage security policies. The test function is particularly important so that policies can be previewed before implementation.
The solution must offer granular permission options that include restrictions based on upstream data source, classification marking, user attributes, column names, and/or specific values. Modern data systems require highly granular access controls to maximize impact and utility across many different users and user types. These controls need to be applied not just to different users but also to the data itself below the resource level. Organizations need to be able to specify access policies at the record, row, or column level, leveraging a user’s attributes or group membership against specific values in the dataset.
The solution must support purpose-based access control lists (PBAC), in addition to role-based access controls (RBAC) and classification-based controls (CBAC). With PBAC, instead of applying for blanket access to data sets and applications without the further context that allows data governance users to evaluate the legitimacy of the request, users apply for access to a purpose. A purpose is tied to data and applications deemed relevant for users to achieve a particular goal. Users can apply to one or more purposes, and they only have access to the data that has been assigned to those purposes within siloed secure project spaces. Data Assets (which may contain datasets, reports, and other applications) can be approved for use by one or more purposes.
To enable role-based access controls, the solution must enable “Discoverer” permissions, in addition to standard permissions such as “Owner,” “Editor,” and “Viewer.” The Discoverer permission enables authorized users to view the name of a given resource and relevant metadata but does not enable the users to view the underlying data. This capability provides a broader range of data access options and avoids the false tradeoff between completely locking down the existence of data assets and over-exposing data that should not be broadly disseminated. Should relevant users identify a pertinent data asset, they can request access and then ascertain whether the data suits their purposes.
The solution must enable custom role definitions for specific workflows, rather than default user roles (e.g., administrator vs. general user). For projects to be successful, individual system users need to be empowered to work freely within the system. Organizations need to give individuals access to all the data they are allowed to access — no more and no less. Custom role definitions allow for the precise separation and delegation of responsibilities, enabling maximum access and preventing scenarios where administrators must choose between overly permissive or restrictive policies. The solutions’s granular access controls should provide the flexibility to address a range of cases and automatically decipher whether a given set of permissions conflicts with other granted permissions.
The solution must support security markings (markings). These markings must apply to specific data assets and propagate to all derived data assets and transformations downstream. Markings are data categorization labels that define eligibility criteria that restrict visibility and actions to users who meet those criteria. They are a key mechanism to enforcing mandatory access controls, which are considered to be the strictest level of control an organization can impose on its data. Users must be a member of all markings applied to a resource to access it. Administrators can manage markings for the organization, allowing data protection officers to centrally manage and audit exactly who can access any given category of data. Markings should be inherited along both the file hierarchy and direct dependencies and propagate through transform and analysis logic. All resources derived from a marked file, folder, or project will assume a marking unless the marking is explicitly removed.
The solution must enable non-technical users to obfuscate data using encryption, decryption, and/or hashing. All cryptographic operations must be auditable. Many organizations have selective revelation workflows, where access to certain data is only allowed after a user provides rationale (e.g., a health insurance administrator may need specific permission to view a member’s Social Security Number). In these scenarios, sensitive data is often encrypted by default and users with legitimate/approved purposes can selectively decrypt specific fields when they need it. Data systems must be able to allow these cryptographic functions in a flexible, precise, and auditable way.
Conclusion
As enterprises have built out their data ecosystems over time, their expectations related to performance, impact, and scale have likewise grown. However, many enterprises continue to rely on an outdated baseline of security requirements in their RFPs. While every organization and every data system has specific, idiosyncratic security requirements, organizations should be aware of the full range of operational security capabilities available to them in order to avoid the false tradeoff between data security and data transparency. Where relevant, RFPs should be designed to surface information related to granular permissioning, purpose-based access controls, security markings, and data obfuscation capabilities.
![]()
Operational Security: Enabling transparency, collaboration, and privacy (Palantir RFx Blog Series… was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.