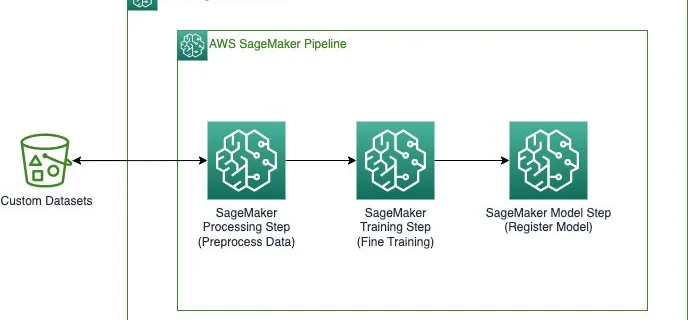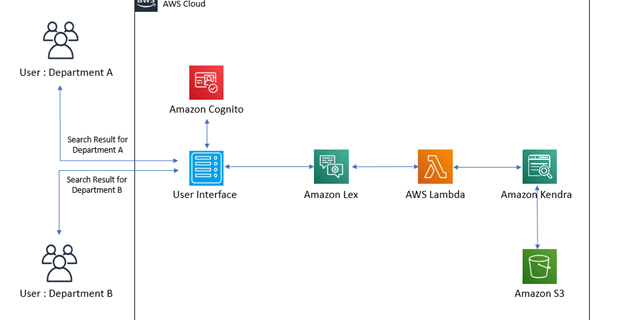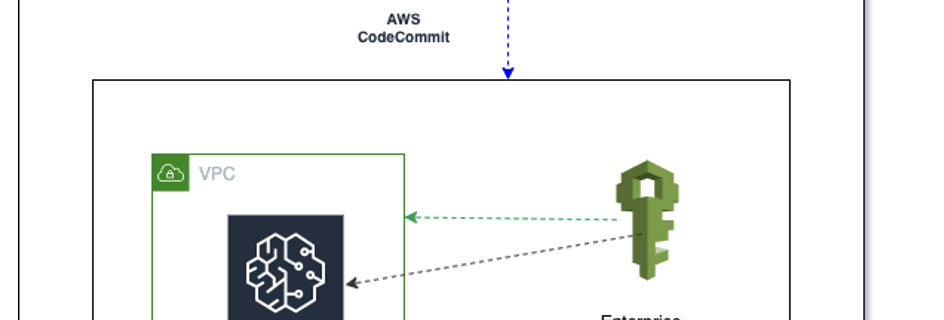
FriendlyCore: A novel differentially private aggregation framework
Posted by Haim Kaplan and Yishay Mansour, Research Scientists, Google Research Differential privacy (DP) machine learning algorithms protect user data by limiting the effect of each data point on an aggregated output with a mathematical guarantee. Intuitively the guarantee implies that changing a single user’s contribution should not significantly change the output distribution of the …
Read more “FriendlyCore: A novel differentially private aggregation framework”